









上一节我们说了决策树,今天我们来聊聊随机森林,随机森林算法这两年是真的火,我刚刚查了文献,只要扯到随机森林的,随便BB几句,就可以发一篇中文核心或双核心论文,你写死写活不如现在搞搞随机森林,时不我待呀,还等什么。
随机森林在2001年由Breiman提出,其解决了logistic回归容易出现共线性的问题,它包含估计缺失值的算法,如果有一部分的资料遗失,仍可以维持一定的准确度。随机森林中分类树的算法自然地包括了变量的交互作用( interaction),所以它也不需要检查变量的交互作用和非线性作用是否显著。在大多数情况下模型参数的缺省设置可以给出最优或接近最优的结果。
随机森林可以简单的理解为很多的决策数通过分类投票。原理大致是:对训练集进行有放回随机抽样,获得的 多个个样本形成训练集的一个子集作为新训练集。然后在生成的新训练集中随机抽取训练集的 p个特征形成子集,利用该子集训练一棵决策树,并且不对其进行剪枝。不断的重复这个过程直至训练出 n 棵决策树,把待分类的测试样本给每棵决策树进行分类,并对每棵决策树的分类结果进行统计,以最多决策树认同的类别作为最终的分类结果。
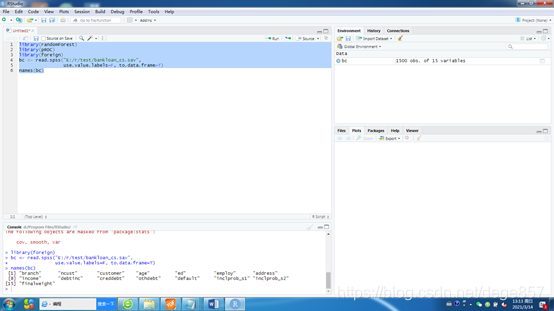
我们继续使用上次的数据来进行随机森林,需要randomForest、pROC、foreign包,我们先导入数据并查看变量
library(randomForest)
library(pROC)
library(foreign)
bc <- read.spss("E:/r/test/bankloan_cs.sav",
use.value.labels=F, to.data.frame=T)
names(bc)
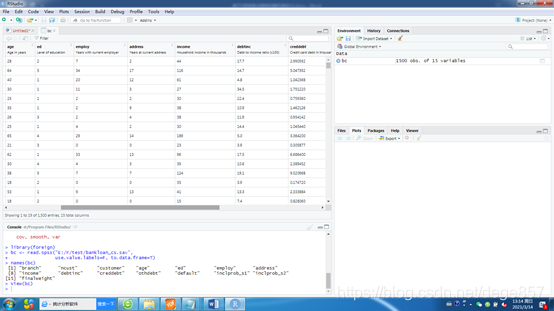
删除部分多余的变量
bc<-bc[,c(-1:-3,-13:-15,-5)]
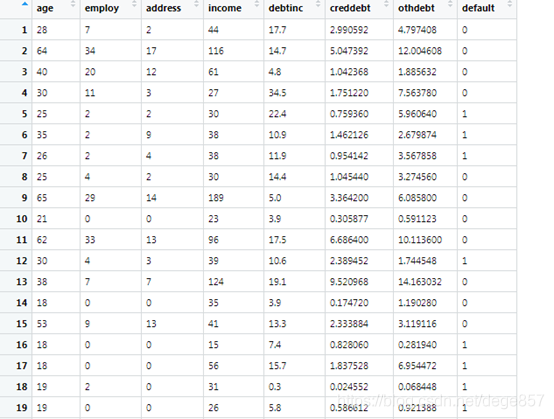
得到如下数据
Age年龄, employ在职雇主的年限,address在这个地方住的时间,income收入,debtinc债务收入比,creddebt信用卡债务,othdebt其他债务,最后一个default是我们的结局指标,即是否是高风险客户。
把数据分为训练集和预测集(就是一个建模,一个验证),要先设一个种子,这样有可重复性
###设置训练和预测集
set.seed(1)
index <- sample(2,nrow(bc),replace = TRUE,prob=c(0.7,0.3))
traindata <- bc[index==1,]
testdata <- bc[index==2,]
###拟合随机森林模型,默认的mtry的值是自变量除以3
def_ntree<- randomForest(default ~age+employ+address+income+debtinc+creddebt
+othdebt,data=traindata,
ntree=500,important=TRUE,proximity=TRUE)
感觉模型误差还是蛮大的

plot(def_ntree)##画图
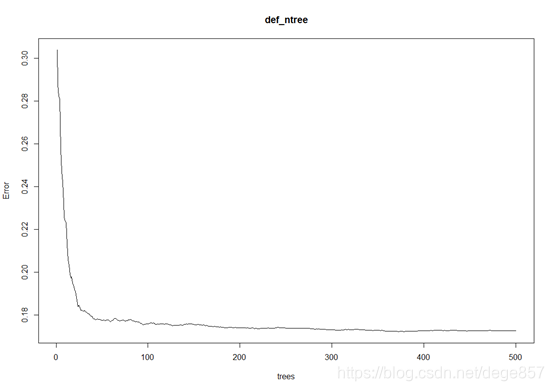
图中表明到了500科树,误差已经变化非常小了,也可以用如下代码求最小误差的树,但我感觉还是看图比较靠谱
which.min(def_ntree $err.rate[,1])### 最小误差的树
我们自己随机模拟建立一个客户数据,给系统进行判断
newdata1<-data.frame(age=30,employ=5,address=2,income=100,
debtinc=5.2,creddebt=0.3,othdebt=0.2)
predict(def_ntree,newdata1)

系统考虑为高风险客户。如果是3分类结局指标还可以使用下面语法进行概率分析和投票
predict(def_ntree,newdata1,type = "prob")
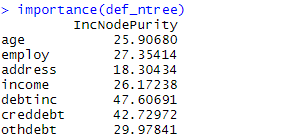
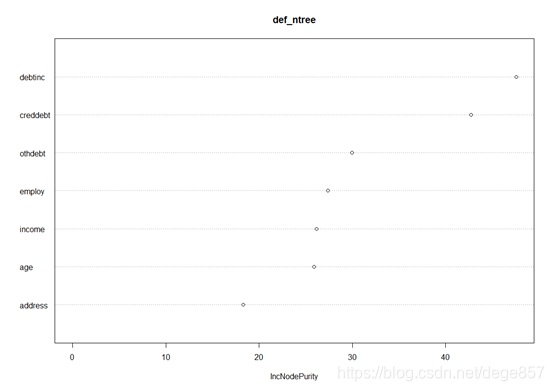
查看模型相关的重要指标,通过打分和图示得到影响模型最重要的指标,可以看出负债收入比最重要,这和决策树判断的一样
importance(def_ntree)
varImpPlot(def_ntree)
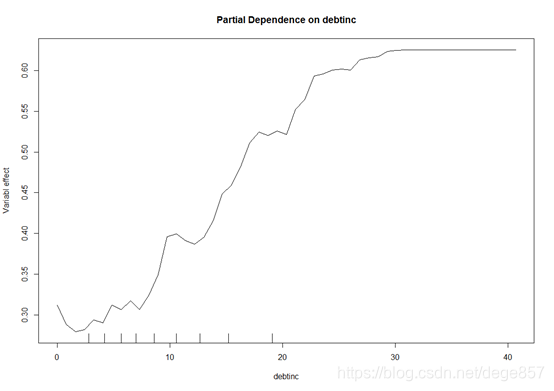
假如我们想知道影响最大的债务收入比这个指标对结局指标的影响,右下图可发现,债务收入大于30很容易被判为高风险客户
partialPlot(def_ntree,traindata,debtinc,"0",xlab = "debtinc",ylab = "Variabl effect")
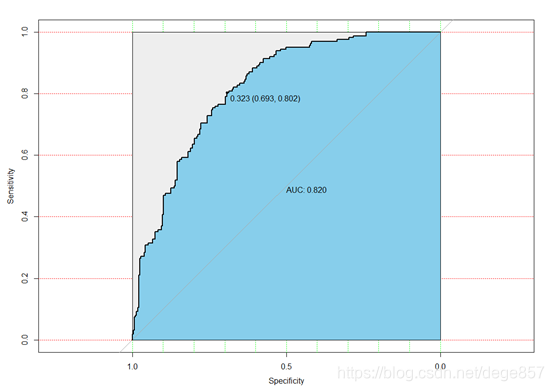
最后通过验证集来验证模型
def_pred<-predict(def_ntree, newdata=testdata)##生成概率
roc<-multiclass.roc (as.ordered(testdata$default) ,as.ordered(def_pred))#拟合ROC
roc1<-roc(as.ordered(testdata$default) ,as.ordered(def_pred))
round(auc(roc1),3)##AUC
round(ci(roc1),3)##95%CI
plot(roc1)
plot(roc1,print.auc=T, auc.polygon=T, grid=c(0.1, 0.2), grid.col=c("green","red"),
max.auc.polygon=T, auc.polygon.col="skyblue",print.thres=T)
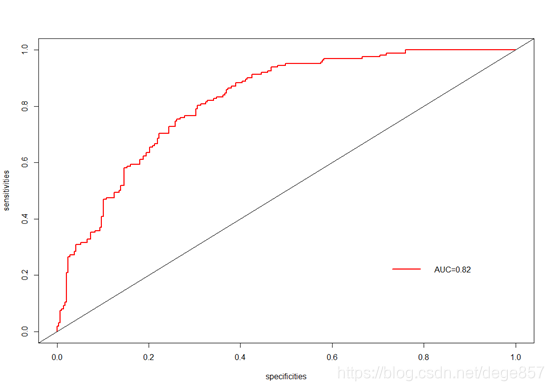
也可以画成这样的图
plot(1-roc1$specificities,roc1$sensitivities,col="red",
lty=1,lwd=2,type = "l",xlab = "specificities",ylab = "sensitivities")
abline(0,1)
legend(0.7,0.3,c("AUC=0.82"),lty=c(1),lwd=c(2),col="red",bty = "n")
参考文献:
- R的randomForest说明
- 唐大伟. 基于随机森林的日径流量预测模型及其R语言实现研究[J]. 黑龙江水利科技, 2019(12).
- 郑志伟,邱佳玲,阳庆玲,龚晓春,郭山清,贾忠伟,郝春.随机森林对文本情感分析的应用与R软件实现[J].现代预防医学,2018,45(8):1345-1348,1353.
- 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.
更多精彩文章请关注公众号:零基础说科研

















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











