







Partial Dependence Plot(PDP)部分依赖图
参考网址:
[1] Interpretable Machine Learning
1. PDP理论
1.1 数值特征
部分依赖图显示了一个或两个特征对ML模型预测结果的边际影响。部分依赖图可以显示目标和特征之间的关系是线性的、单调的还是更复杂的。例如,当应用于线性回归模型时,部分相关性图始终显示线性关系。
用于回归的部分依赖函数定义:
f
^
x
S
(
x
S
)
=
E
x
C
[
f
^
(
x
S
,
x
C
)
]
=
∫
f
^
(
x
S
,
x
C
)
d
P
(
x
C
)
\hat{f}_{x_S}(x_S)=E_{x_C}\left[\hat{f}(x_S,x_C)\right]=\int\hat{f}(x_S,x_C)d\mathbb{P}(x_C)
f^xS(xS)=ExC[f^(xS,xC)]=∫f^(xS,xC)dP(xC)
x
S
x_S
xS是部分依赖函数要绘制的特征;通常集合S中仅有一个到两个特征;S中的feature(s)是我们希望了解其对预测的影响的特征。
x
C
x_C
xC是ML模型
f
^
\hat{f}
f^使用的其他特征,C是S的补集;
特征向量
x
S
x_S
xS和
x
C
x_C
xC的组合构成了总特征空间x。
Partial Dependence的工作原理是,在集合C中的特征分布上边缘化机器学习模型的输出,以便该函数显示我们感兴趣的集合S中的特征与预测结果之间的关系。通过边缘化其他特性,我们得到的函数只依赖于S中的特性,包括与其他特性的交互。
通过计算训练数据中的平均值来估计部分函数
f
^
x
S
\hat{f}_{x_S}
f^xS,也称为Monte Carlo方法:
f
^
x
S
(
x
S
)
=
1
n
∑
i
=
1
n
f
^
(
x
S
,
x
C
(
i
)
)
\hat{f}_{x_S}(x_S)=\frac{1}{n}\sum_{i=1}^n\hat{f}(x_S,x^{(i)}_{C})
f^xS(xS)=n1i=1∑nf^(xS,xC(i))
Partial Function告诉我们,对于给定特征集合S的value(s),预测的平均边际效应是什么。在这个公式中, x C ( i ) x^{(i)}_{C} xC(i)是数据集中我们不感兴趣的特性的实际特征值,n是数据集中的实例数。PDP的一个假设是C中的特征与S中的特征不相关。如果违背了这一假设,那么部分依赖图计算的平均值将包含非常不可能或甚至不可能的数据点(见缺点)。
对于ML模型输出概率的分类,PDP 显示给定 S 中 feature(s) 不同值的某个类别的概率。处理多个类的一个简单方法是画一条线或绘制每个类。\
PDP 是一种全局方法:该方法考虑所有实例并给出关于特征与预测结果的全局关系的声明。
1.1 分类特征
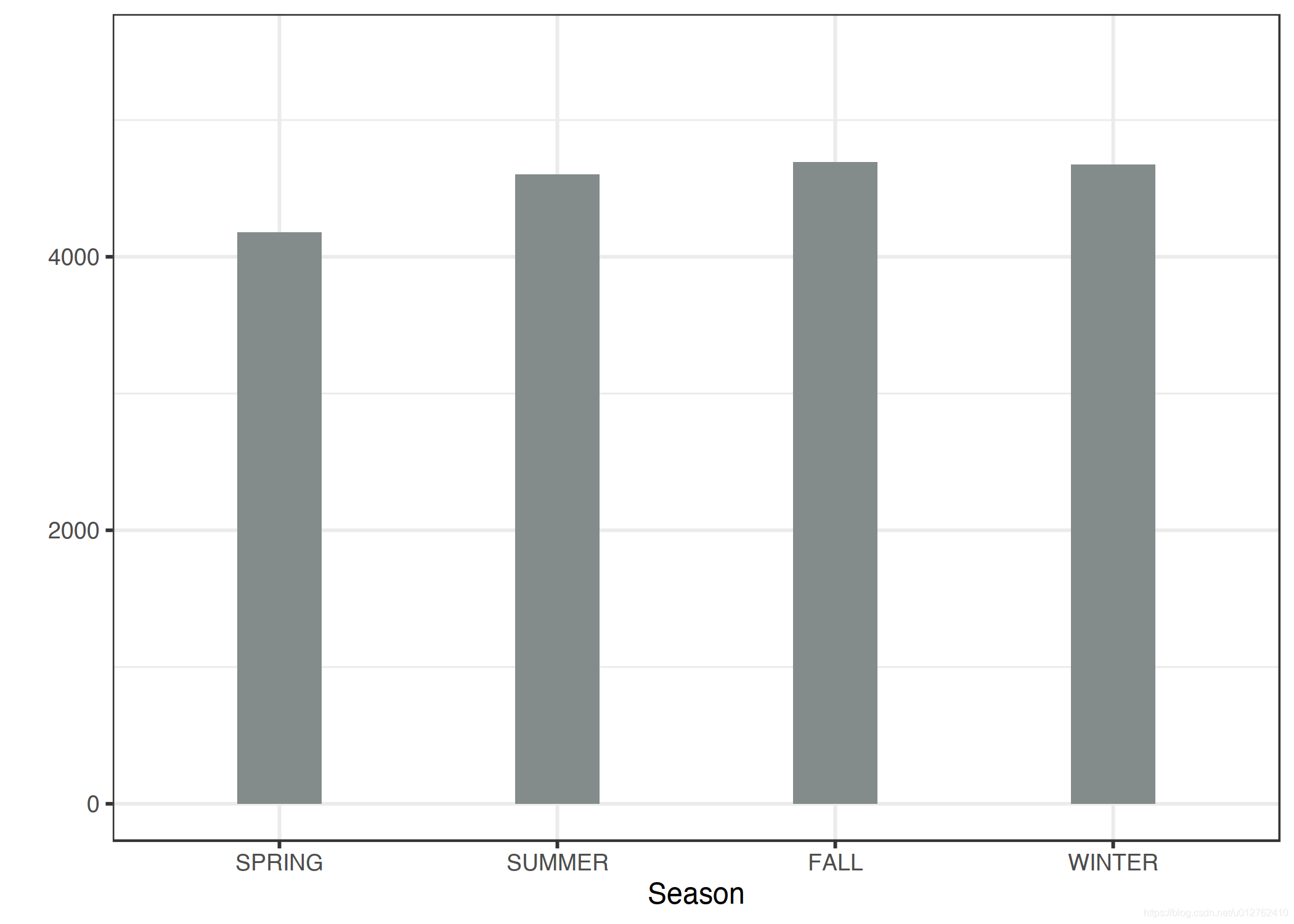
到目前为止,我们只考虑了数值特征。 对于分类特征,部分依赖很容易计算。 对于每个类别,我们通过强制所有数据实例具有相同的类别来获得 PDP 估计。例如,如果我们查看自行车租赁数据集并对季节的部分依赖图感兴趣,我们会得到 4 个数字,每个季节一个。为了计算“夏天”的值,我们将所有数据实例的季节替换为“夏天”并对预测进行平均。
2. PDP例子
实际上,特征集 S 通常只包含一个特征或最多包含两个,因为一个特征产生 2D 图,而两个特征产生 3D 图。 除此之外的一切都非常棘手。即使是在2D纸上或显示器上使用3D也很有挑战性。
让我们回到回归示例,在该示例中,我们预测在给定日期将租用的自行车数量。首先我们拟合一个机器学习模型,然后我们分析部分依赖关系。 在这种情况下,我们拟合了一个随机森林来预测自行车的数量,并使用部分依赖图来可视化模型学习到的关系。 下图显示了天气特征对预测自行车数量的影响。
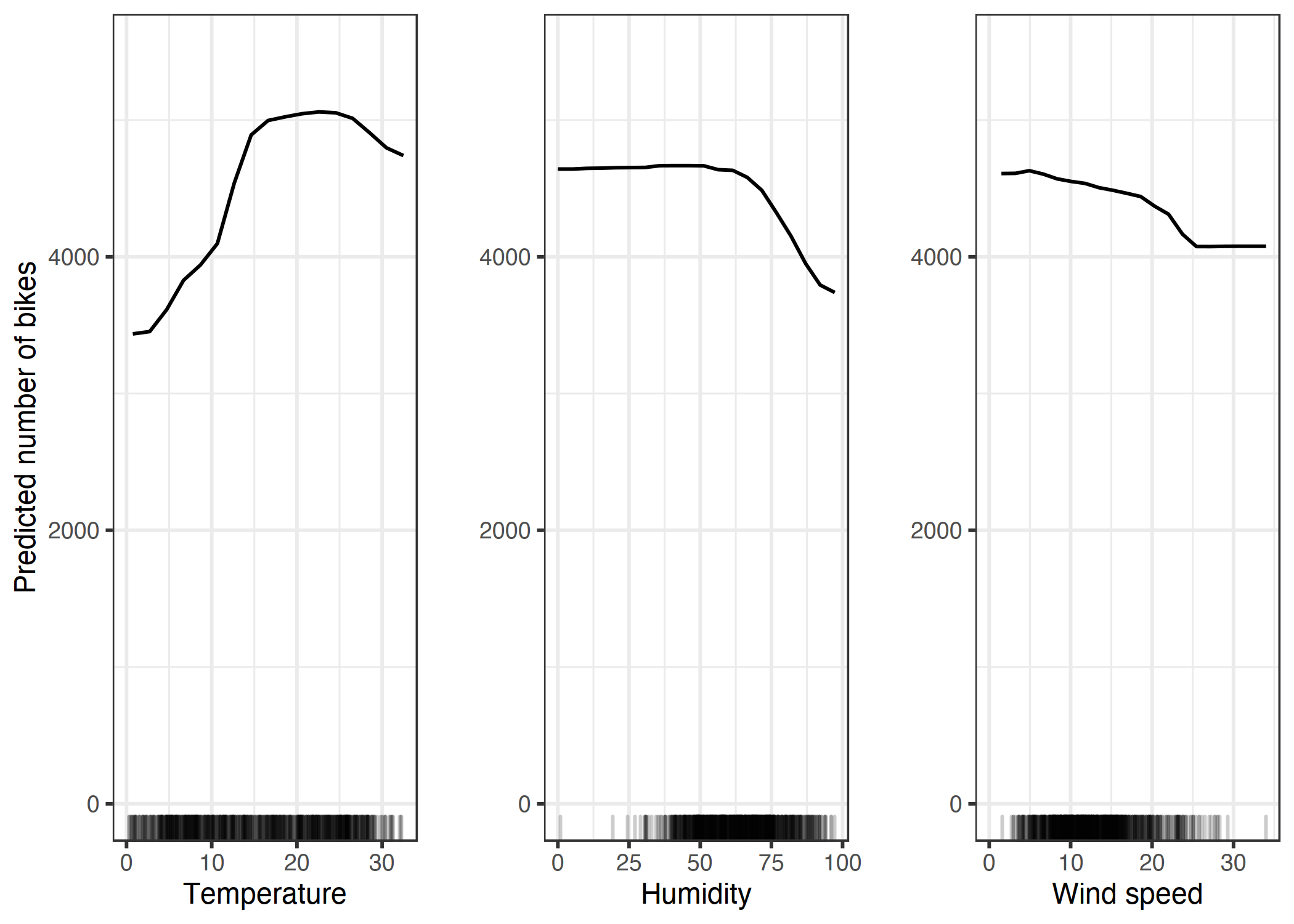
自行车数量预测模型以及温度、湿度和风速的 PDP。 最大的差异体现在温度上。 天气越热,租用的自行车就越多。 这一趋势上升到 20 摄氏度,然后趋于平缓并在 30 摄氏度时略微下降。x 轴上的标记表示数据分布。
该模型预测,对于温暖但不太热的天气,租赁自行车的平均数量会很高。当湿度超过60%时,潜在的骑行者越来越不愿意租用自行车。此外,风越大,喜欢骑自行车的人就越少,这是有道理的。有趣的是,当风速从25公里/小时增加到35公里/小时时,预测的自行车租赁数量并不会下降,但没有太多的训练数据,所以机器学习模型可能无法学习到这个范围的有意义的预测。至少在直觉上,我认为自行车的数量会随着风速的增加而减少,尤其是在风速非常大的时候。
为了说明具有分类特征的部分依赖图,我们检查了季节特征对预测的自行车租赁的影响。
我们还计算了宫颈癌分类的部分依赖性。 这次我们拟合了一个随机森林,根据风险因素来预测女性是否可能患上宫颈癌。 我们计算并可视化癌症概率对随机森林不同特征的部分依赖:
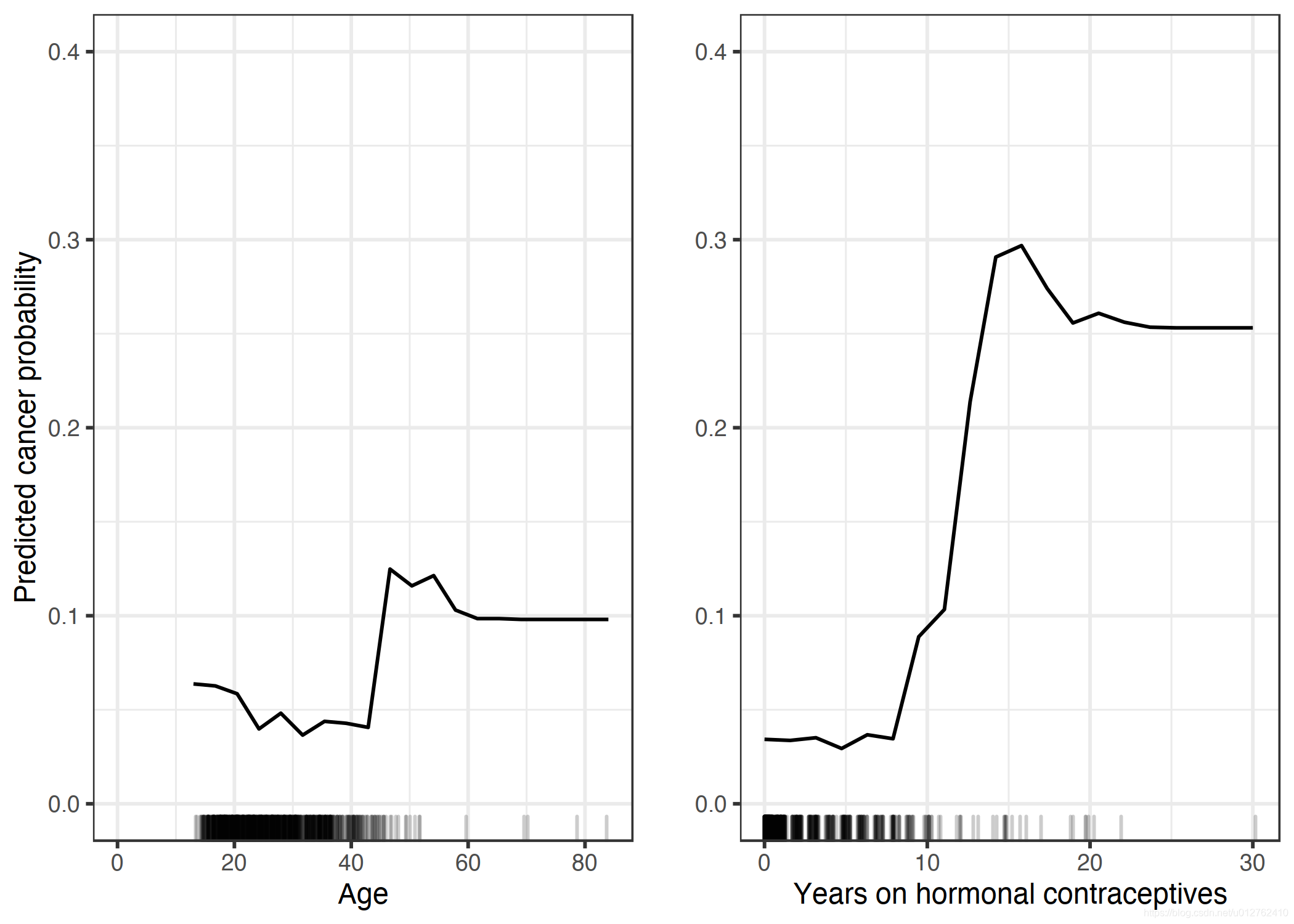
基于使用激素避孕药的年龄和年份的癌症概率 PDP。 对于年龄,PDP 显示概率在 40 岁之前较低,并在 40 岁之后增加。 服用激素避孕药的时间越长,预测的癌症风险就越高,尤其是在 10 年后。 对于这两个特征,没有多少具有大值的数据点可用,因此这些区域的 PD 估计不太可靠。
我们还可以同时可视化两个特征的部分依赖关系:
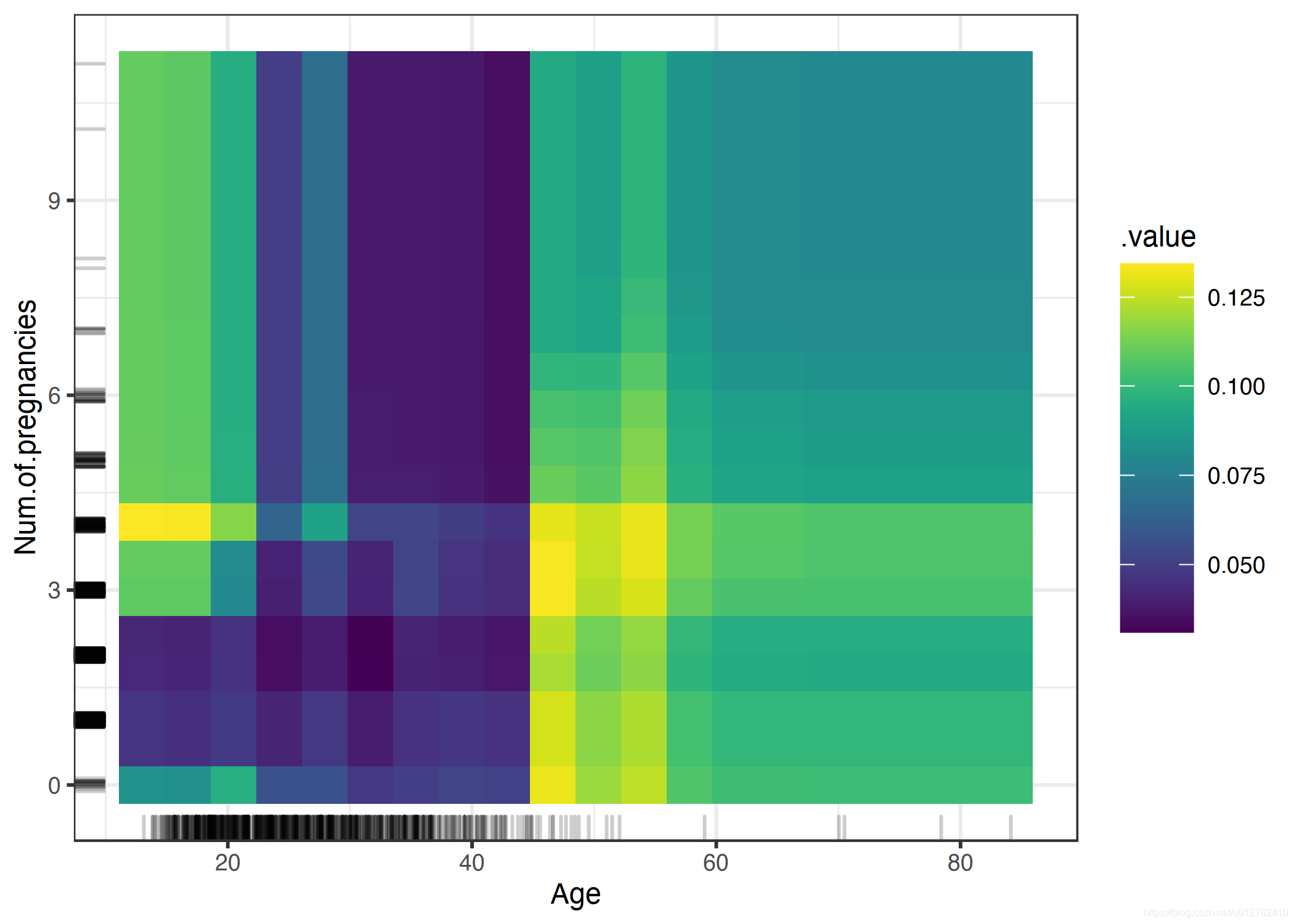
癌症概率的 PDP 与年龄和怀孕次数的相互作用。 该图显示了 45 岁时癌症概率的增加。对于 25 岁以下的女性,与怀孕 0 次或超过 2 次的女性相比,怀孕 1 次或 2 次的女性预测的癌症风险较低。 但是在得出结论时要小心:这可能只是相关关系而不是因果关系!
3. PDP优点
- 部分依赖图的计算很直观:如果我们强制所有数据点假设该特征值,则特定特征值的部分依赖函数表示平均预测。根据我的经验,外行通常很快就能理解 PDP 的概念。
- 如果您计算 PDP 的特征与其他特征不相关,那么 PDP 完美地代表了该特征如何平均影响预测。在不相关的情况下,解释很清楚:部分依赖图显示了当第 j 个特征发生变化时数据集中的平均预测如何变化。当特征相关时会更复杂,另见缺点。
- 部分依赖图很容易实现。
- 部分依赖图的计算具有因果解释。我们干预一个特征并测量预测的变化。这样做时,我们会分析特征与预测之间的因果关系。
这种关系是模型的因果关系——因为我们明确地将结果建模为特征的函数——但不一定适用于现实世界!
4. PDP缺点
- 部分依赖函数中显示的最大特征数是两个。这不是 PDP 的错,而是二维表示(纸或屏幕)的错,也是我们无法想象超过 3 维的错。
- 一些 PD 图不显示特征分布。省略分布可能会产生误导,因为您可能会过度解释几乎没有数据的区域。通过显示 rug(x 轴上数据点的指标)或直方图可以轻松解决此问题。
- 独立性假设是 PD 图的最大问题 假设为其计算部分依赖的特征与其他特征不相关。例如,假设您想根据人的体重和身高预测他的步行速度。对于特征之一的部分依赖,例如身高,我们假设其他特征(体重)与身高无关,这显然是错误的假设。对于特定高度(例如 200 cm)的 PDP 计算,我们对重量的边际分布进行平均,其中可能包括低于 50 kg 的重量,这对于 2 米的人来说是不现实的。换句话说:当特征相关时,我们会在特征分布的实际概率非常低的区域创建新的数据点(例如,不太可能有人身高 2 米但体重不到 50 公斤)。
















 8237
8237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









