









目前真实世界研究(Real-World Study, RWS)突然就火了起来,目前很多顶刊都刊登了关于真实世界研究的文章。引起了我的兴趣,后续将间断介绍一些真实世界研究的方法学内容。


真实世界研究(Real-World Study, RWS) 是一种在真实医疗或生活环境中收集数据、评估医疗干预措施(如药物、器械、治疗方案)效果和安全性的研究方法。它与传统的*、随机对照试验(RCT)形成互补,更注重在非理想化、多样化的现实场景中观察医疗实践的结果。
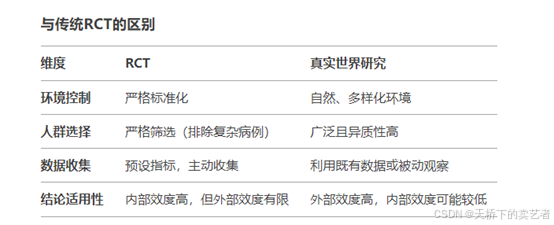
咱们都知道,RCT的证据力度很强,那为什么强呢?主要是人群经过筛选后,人群的特征相似(年龄、性别等),而且观察变量X是随机分配的,这样有很强的可比性。而我们通常的真实世界研究通常用的是观察性数据,非随机化,数据可能来自电子健康记录、登记数据、或者回顾性收集的数据,患者年龄性别等其他特征很难相似,观察变量X在两组见不会随机分配。这样咱们的研究指标可能就会因为混杂因素影响而导致结果出现偏倚。
我这几天查看了一些真实世界研究的方法,其实不需要有复杂的统计学方法,大多数都是倾向评分匹配,逆概率加权,数据插补这类的,比如下面文章说的是:模拟随机临床试验,

倾向性评分用于消除混杂因素的影响,正确估计处理措施对结局的作用,主要有四种方法:倾向性评分匹配,倾向性评分分层,倾向性评分逆概率加权(IPTW)和倾向性评分调整。主要是把两组患者的基线资料配平。公众号上基本上所有方法类的文章都有。
主要的是方法学部分差异,比如说缺失数据的处理,分层分析,混杂因素筛查等等。
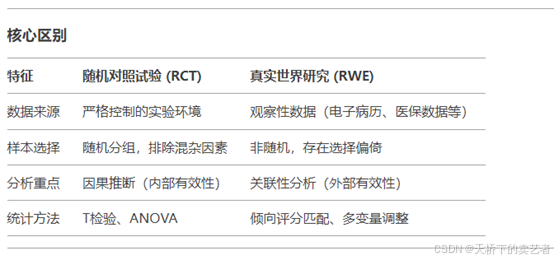
最后是用R语言的一个小例子演示一个RCT和真实世界研究(RWE)分析方法上的区别,
先生成一个RCT数据和RWE数据
生成rct数据
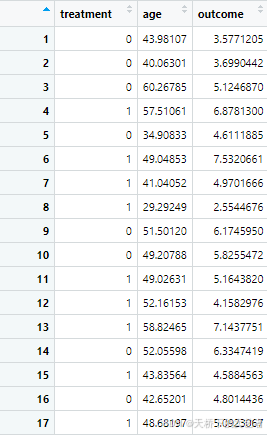
# 生成 RCT 数据(理想化环境)
set.seed(123)
n <- 1000 # 样本量
# 随机分配处理组和对照组(无混杂)
rct_data <- data.frame(
treatment = sample(c(0, 1), n, replace = TRUE), # 处理变量(随机)
age = rnorm(n, 50, 10), # 年龄(与处理无关)
outcome = numeric(n)
)
rct_data$outcome <- 0.5 * rct_data$treatment + 0.1 * rct_data$age + rnorm(n)
rct_data$treatment<-as.factor(rct_data$treatment)
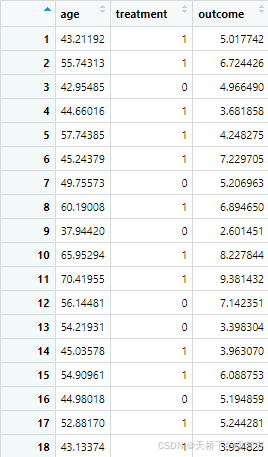
生成 RWE 数据(存在混杂),在RWE 数据中,年龄是和治疗相关的,属于混杂因素
# 生成 RWE 数据(存在混杂)
rwe_data <- data.frame(
age = rnorm(n, 50, 10)
)
# 年龄越大,接受治疗的概率越高(引入混杂)
rwe_data$treatment <- rbinom(n, 1, plogis(0.1 * (rwe_data$age - 50)))
rwe_data$outcome <- 0.5 * rwe_data$treatment + 0.1 * rwe_data$age + rnorm(n)
rwe_data$treatment<-as.factor(rwe_data$treatment)
分析RCT数据的时候,因为已经调整混杂,直接分析就行
model_rct <- lm(outcome ~ treatment + age, data = rct_data)
summary(model_rct)
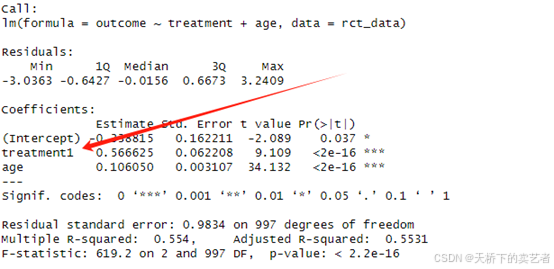
显示治疗和不治疗的系数差是0.5.
下面咱们使用RWE数据来分析,如果咱们不调整年龄混杂,不进行人群匹配,直接分析
model_naive <- lm(outcome ~ treatment, data = rwe_data)
summary(model_naive)
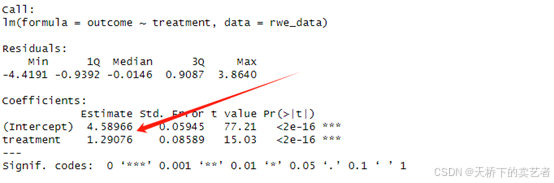
我们可以看到结果和RCT结果相差很大,
接下来咱们对RWE数据进行倾向评分和匹配
生成psm模型
library(MatchIt)
#估计倾向评分
psm_model <- matchit(
treatment ~ age, # 用年龄预测治疗分配
data = rwe_data,
method = "nearest", # 最近邻匹配
distance = "logit" # 逻辑回归模型
)
提取匹配好的数据
#匹配后的数据
matched_data <- match.data(psm_model)
分析
#分析匹配后数据
model_rwe <- lm(outcome ~ treatment + age, data = matched_data)
summary(model_rwe)
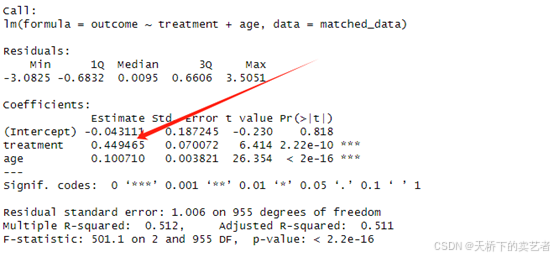
我们可以看到最后系数是0.45.接近0.5,和我们使用RCT做出来的结果非常接近,所以再真实世界研究中,找到混杂因素,人群匹配非常重要。实际中的分析比这个更加复杂,但是使用了真实世界研究分析后,确实能达到或者接近RCT的效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











