









潜类别轨迹建模(Latent Class Trajectory Modeling, LCTM)是一种统计方法,用于识别具有相似时间发展模式的未观测群体。这种方法结合了潜变量模型和轨迹分析的优点,可以用来探索不同个体随时间变化的规律或趋势,并将这些个体分类到不同的潜类别中去。
主要特点
识别潜在群体:LCTM能够帮助研究者在数据中发现存在但不可直接观测到的不同群体。
考虑个体差异:此方法允许每个个体在其所属类别的框架内有不同的轨迹,从而考虑到个体之间的变异性。
灵活的模型设定:可以根据研究目的选择不同的模型设定,比如线性、二次方或者更复杂的函数形式来描述轨迹。
应用领域
LCTM被广泛应用于社会科学研究、心理学、公共卫生、医学研究等领域。例如,在医学研究中,它可以用来分析患者在接受某种治疗后的恢复过程,识别出不同的恢复模式以及与之相关的因素。
目前潜轨迹模型(GBTM)属于比较好发文的,能发的文章分数也比较高,有些机构还开专门开了潜轨迹模型(GBTM)培训班,因为属于纵向分析,本公众号今后将陆续介绍它,本期以文章《Framework to construct and interpret latent class trajectory modelling》来介绍规范建立潜轨迹模型(GBTM)

作者Hannah Lennon把规范构建潜轨迹模型(GBTM)分成8步:

1 范围模型通过根据现有文献和基于合理的临床模式的结构暂时选择一个合理的类数。
2 从步骤1优化模型,以确认最佳的类别数量,通常测试K=1–7类。 最低贝叶斯信息准则值。
3 使用在步骤2中选定的K值,从固定效应到无限制随机效应,优化模型结构。
4 按照在线说明进行模型适当性评估 补充表S3,包括分配的后验概率(APPA)、正确分类的几率(OCC)和相对熵。
5 调查图形展示
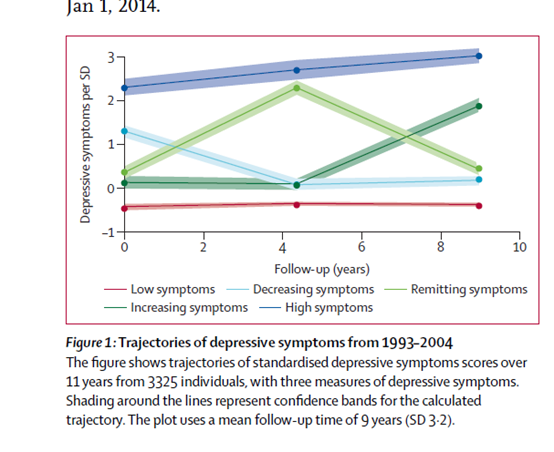
在同一个图表中绘制每个类别随时间变化的平均轨迹。
6 运行额外的工具来评估歧视,包括分离度(DoS)和Elsensohn的残差包络。
DoS 大于零。
7 评估临床特征和可能性。
按潜在类别分列特征的表格。这些轨迹模式在临床上有意义吗?也许,考虑具有最低人口百分比的类别。
8 进行敏感性分析,例如,测试在所有时间点都没有完整数据的模型。
下面来个小例子演示:
导入数据和R包,
library(lcmm)
bmi_long<-read.csv("E:/r/test/bmi.csv",sep=',',header=TRUE)
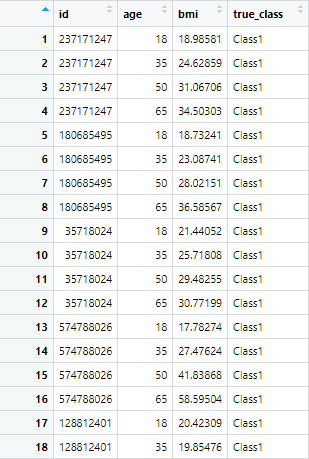
这是个很简单的数据,ID属于随机项,咱们要研究bmi和age的关系
首先我们写出轨迹类别数量为1时候的潜类别轨迹的代码:
m.1 <- hlme(bmi ~ 1+ age + I(age^2),
random = ~ 1 + age,
ng = 1,
data = data.frame(bmi), subject = "id")
然后通过贝叶斯信息进行选择
for (i in 2:5) {
mi <- hlme(fixed =bmi ~ age + I(age^2),
mixture= ~ age,
random = ~ age,
ng = i,
nwg = TRUE,
data = bmi_long[1:500, ], subject = "id")
}
根据贝叶斯信息咱们选择bic最小的2分类为轨迹模型
m2 <- hlme(fixed =bmi ~ age + I(age^2),
mixture= ~ age,
random = ~ age,
ng = 2,
nwg = TRUE,
data = bmi_long[1:500, ], subject = "id")
summary(m2)
通过模型进行绘图
plot(plotpred, lty=2,lwd = 2,xlab="Age", ylab="BMI", legend.loc = "topleft", cex=0.75)
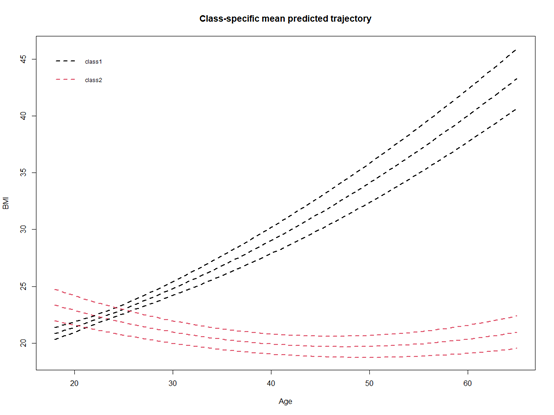
可以进一步整理图形
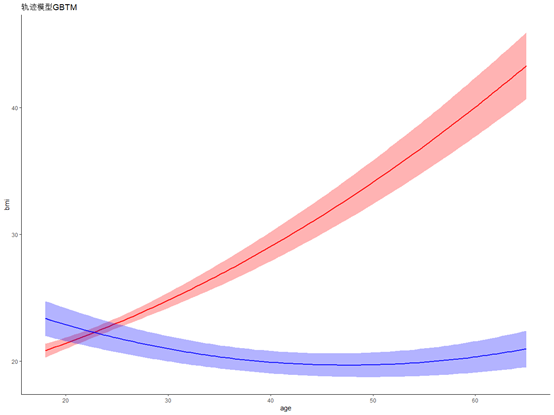
还要提取几个重要的指标,后验概率,个体的类别归属后面在介绍。


















 7389
7389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











