







向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx
这篇文章是训练YOLO v2过程中的经验总结,我使用YOLO v2训练一组自己的数据,训练后的model,在阈值为.25的情况下,Recall值是95.54%,Precision 是97.27%。
需要注意的是,这一训练过程可能只对我自己的训练集有效,因为我是根据我这一训练集的特征来对YOLO代码进行修改,可能对你的数据集并不适用,所以仅供参考。
我的数据集 批量改名首先准备好自己的数据集,最好固定格式,此处以VOC为例,采用jpg格式的图像,在名字上最好使用像VOC一样类似000001.jpg、000002.jpg这样。可参照下面示例python代码

读取某文件夹下的所有图像然后统一命名,用了opencv所以顺便还可以改格式。

这里面用到的文件夹是Annotation、ImageSets和JPEGImages。其中文件夹Annotation中主要存放xml文件,每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;而ImageSets我们只需要用到Main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);JPEGImages文件夹中放我们已按统一规则命名好的原始图像。
图像标注
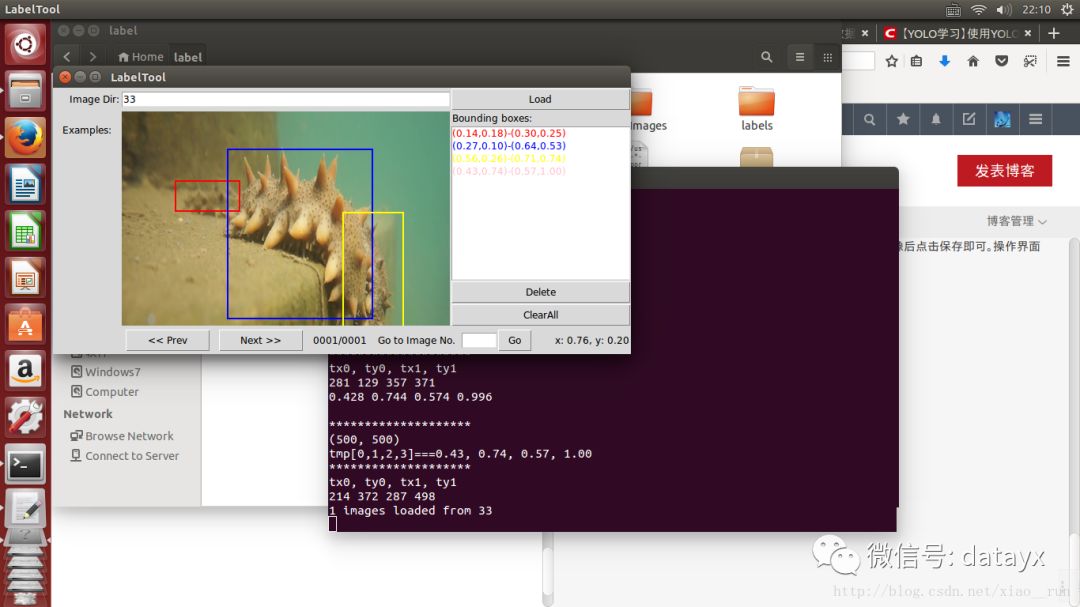
代码篇幅有限
请查看原文
https://blog.csdn.net/xiao__run/article/details/78714659

接下来我们把标注文件改成.XML 文件才能训练,不多说直接上代码
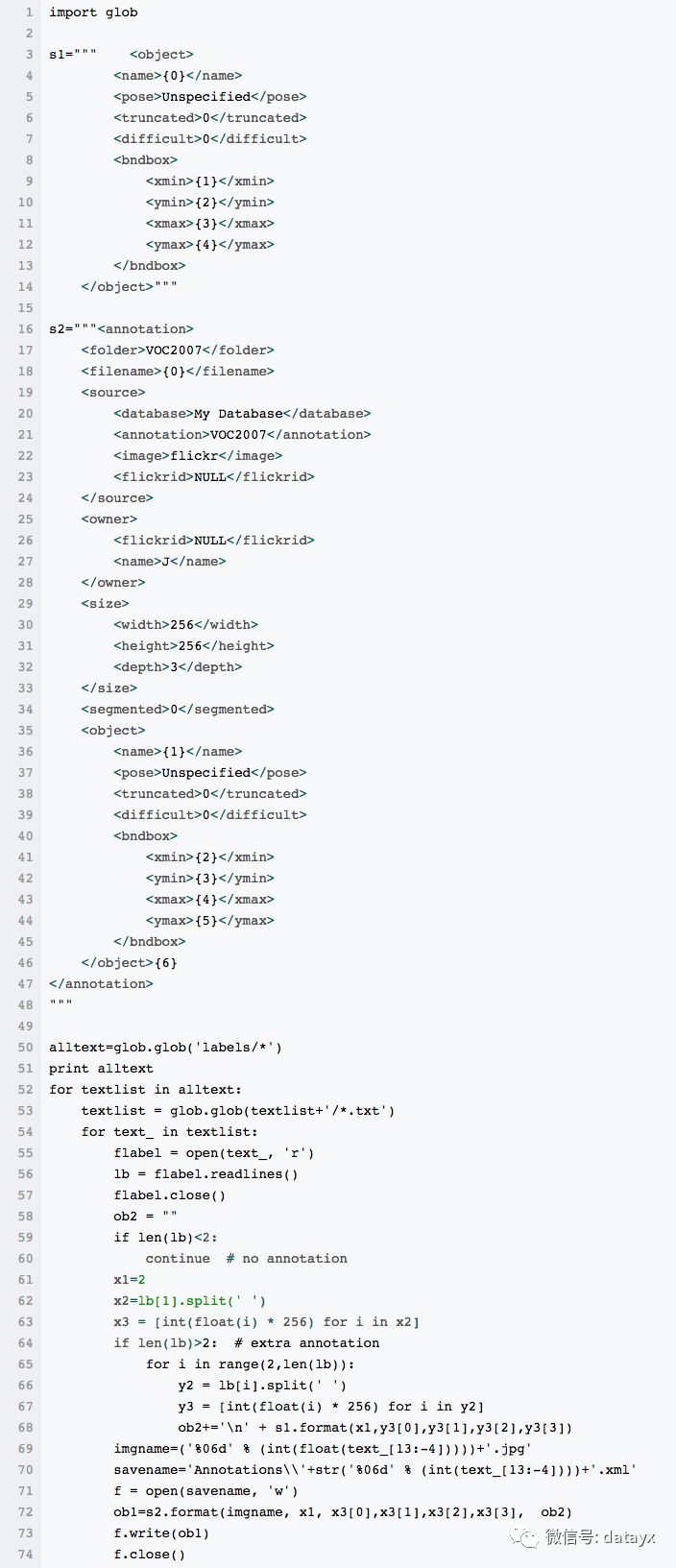

用YOLOv2训练

这里包含了类别和对应归一化后的位置(i guess,如有错请指正)。同时在scripts\下应该也生成了train_2007.txt这个文件,里面包含了所有训练样本的绝对路径。

代码篇幅有限
请查看原文
https://blog.csdn.net/xiao__run/article/details/78714659
也可参考https://blog.csdn.net/shangpapa3/article/details/77483324
Keras 实战 YOLO v3 目标检测图文教程
运行步骤
1.从 YOLO 官网下载 YOLOv3 权重
wget https://pjreddie.com/media/files/yolov3.weights
下载过程如图:

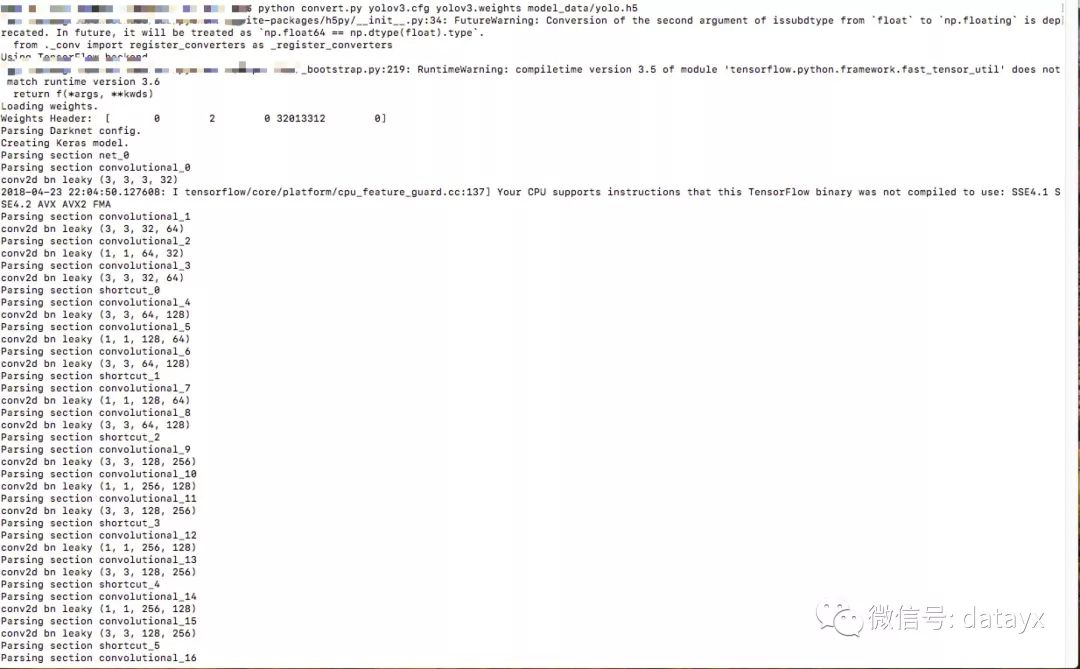
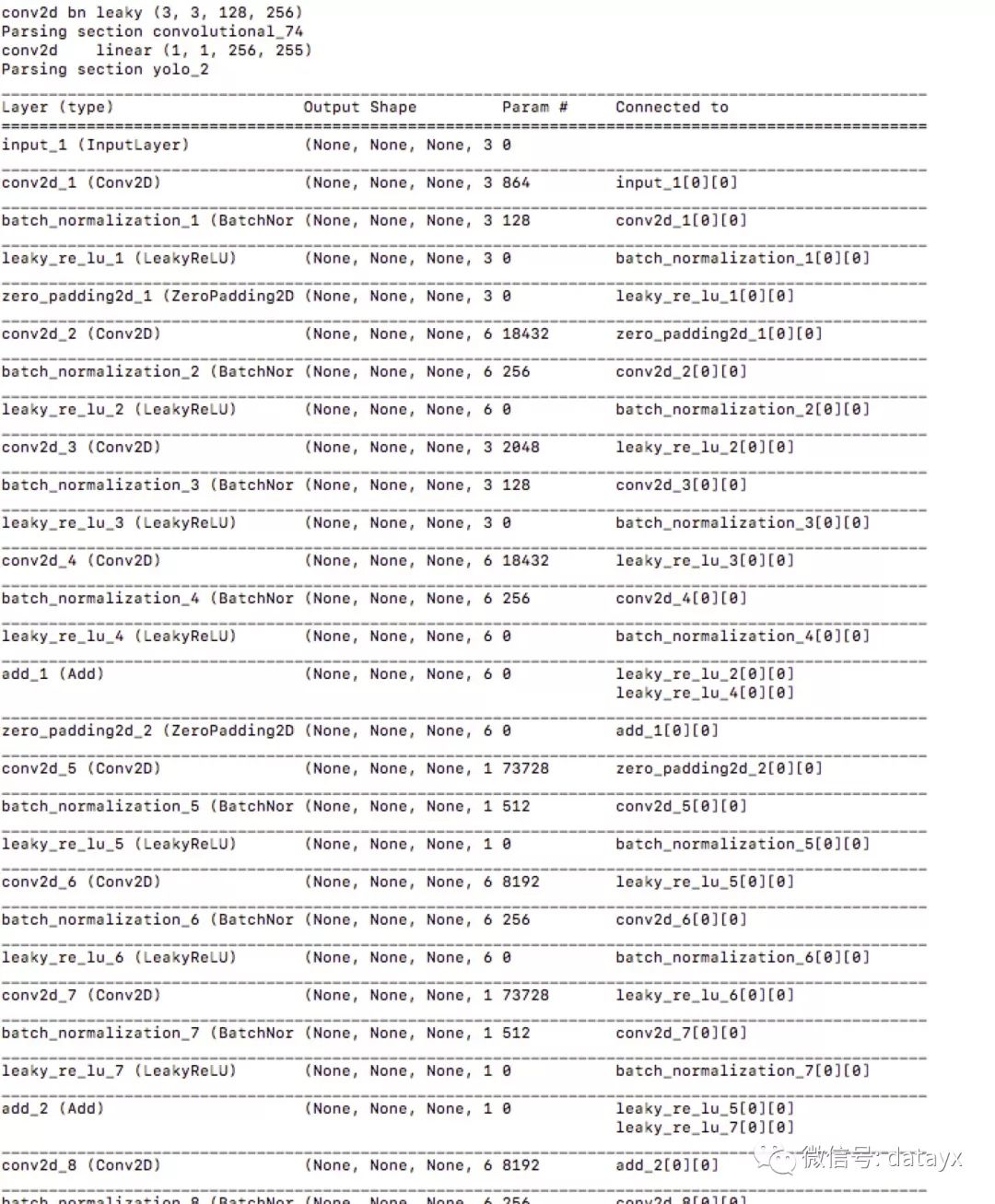
2.转换 Darknet YOLO 模型为 Keras 模型
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
转换过程如图:
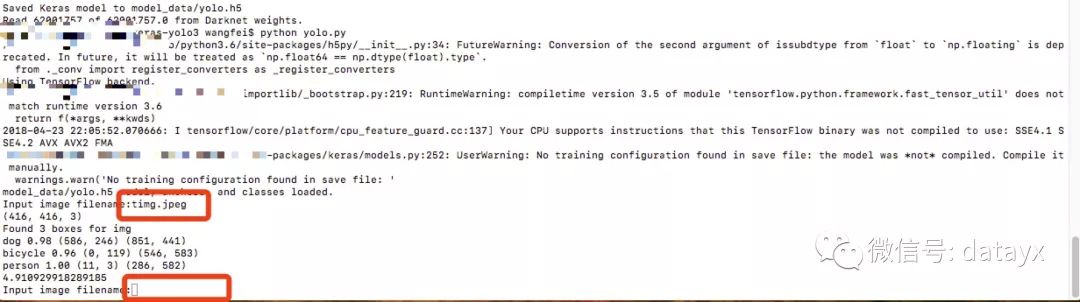
3.运行YOLO 目标检测
python yolo.py
需要下载一个图片,然后输入图片的名称,如图所示:
我并没有使用经典的那张图,随便从网上找了一个,来源见图片水印:

识别效果:

项目地址:https://github.com/qqwweee/keras-yolo3
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注

















 9666
9666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









