







图片标注:
推荐在线标注工具:Make Sense
点击页面右下角的Get Started进入主页面
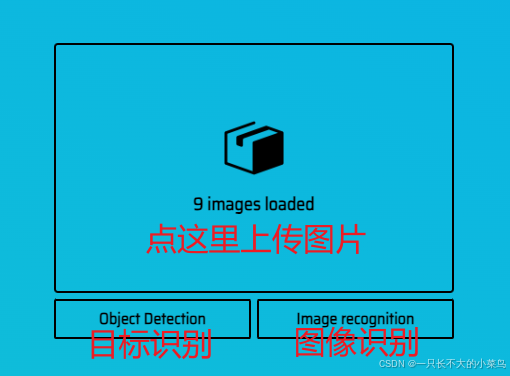
批量上传图片,并点击【目标识别】:
目标识别:框选出我们要识别的指定目标
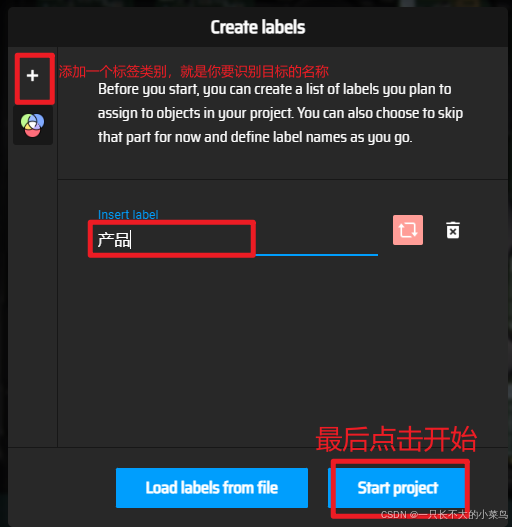
设置一个标签类别(我这里做演示,实际使用最好使用英文名称):
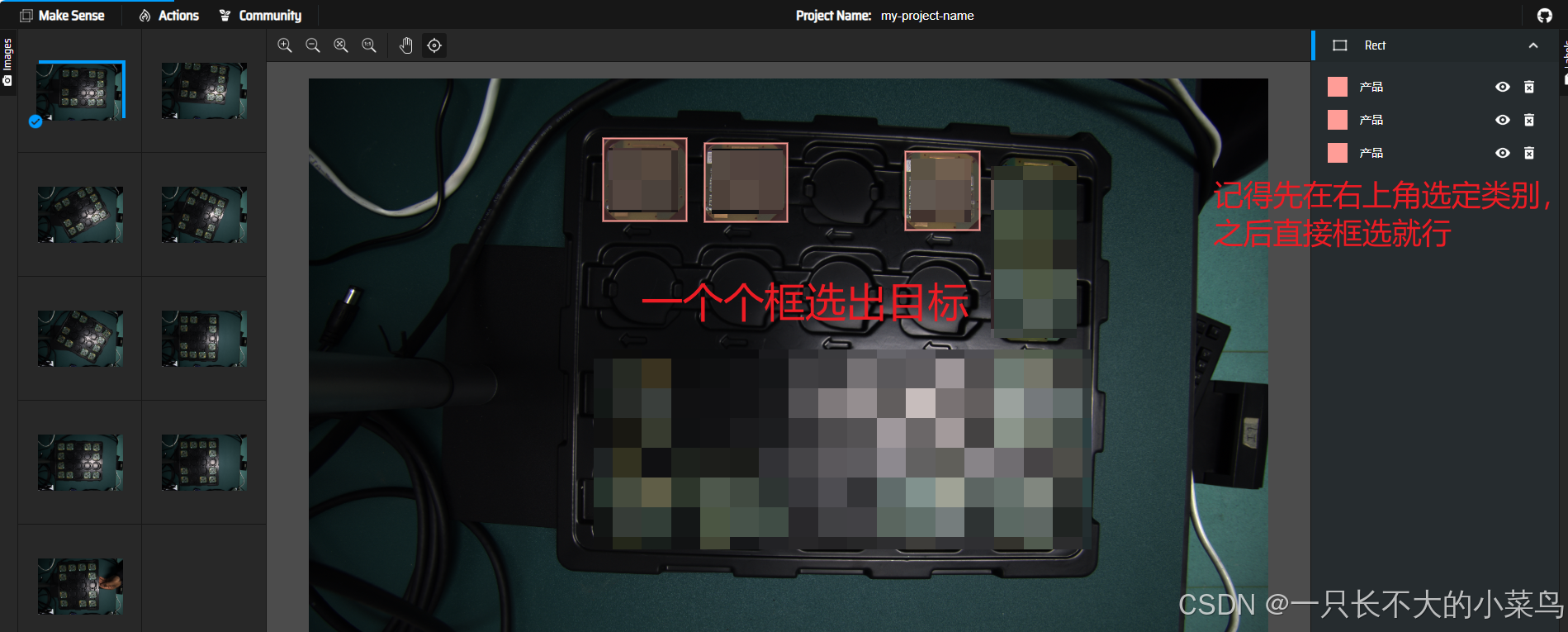
开始标注:
标注完成了之后到处标注信息:
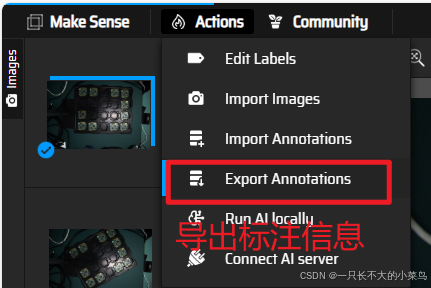
导出的标注文件的信息:
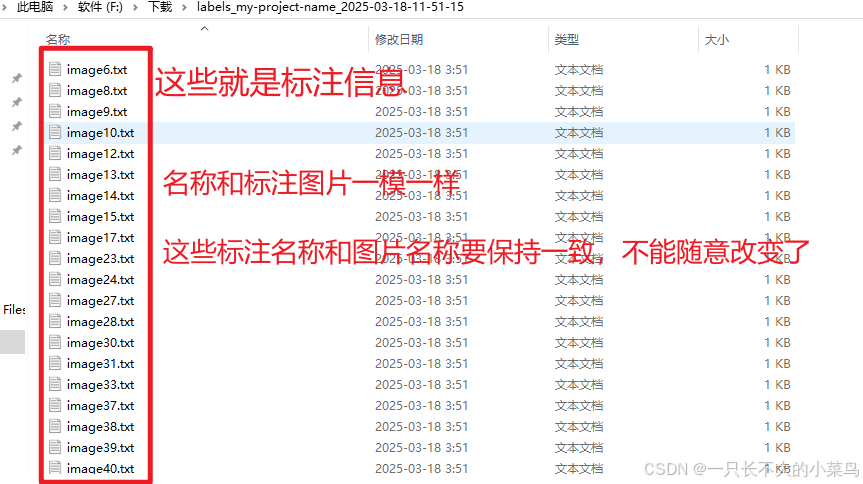
等会这些txt文件将要分别放在labels文件夹中。
接着做其余动作:
安装python3.10
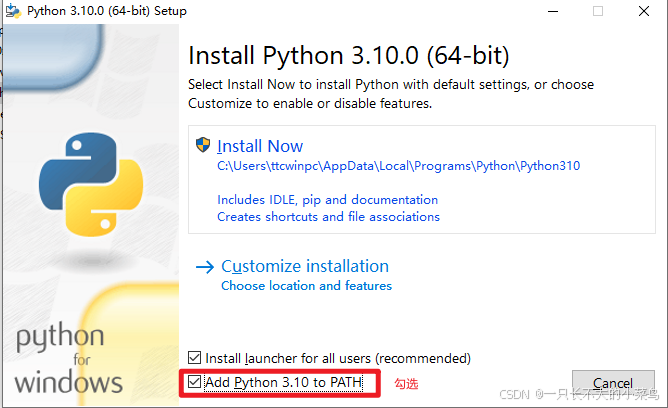
添加到系统变量路径,选择【install now】
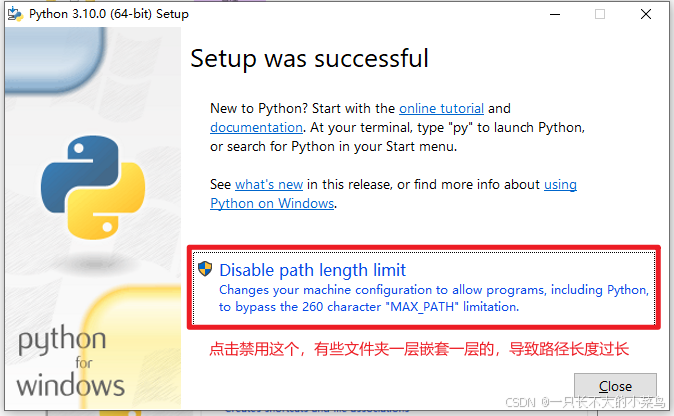
禁用最大长度路径:
使用cmd命令终端安装训练库(阿里源,安装训练必须的库,安装过程中不要去动,安装完成有提示信息的):
pip install -i https://mirrors.aliyun.com/pypi/simple/ ultralytics torch torchvision
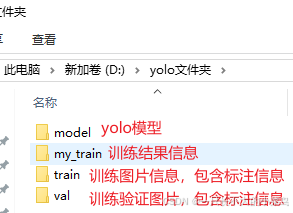
创建一个yolo文件夹(尽量避免使用中文文件名称,我这为了方便演示):
- 把刚刚标注的txt文件放入train\labels文件夹中
- 把刚刚需要标注的图片文件放入train\images文件夹中
- 在train\labels文件夹和train\images文件夹中,分别【剪切】几个文件到val文件夹中剪切的图片和文本都要名称一致,分别放到val的labels和images文件夹中,用于训练验证。
*这两个是一一对应的,也就是说图片名称和标注名称是一致的。
val文件夹中,需要放置几个错误的产品,放图片和txt文件,txt设置为空就行,图片名称和txt文件名要保持一致,用于验证的
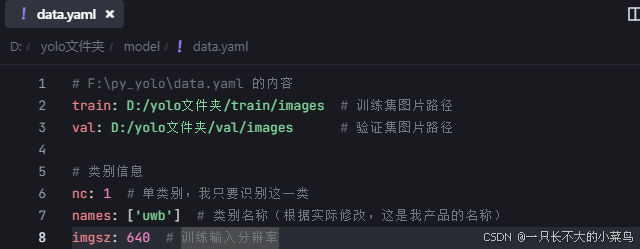
Yolo的data.yaml文件信息:
训练代码:
yolo detect train \ #检测模型训练
data=F:\py_yolo\data.yaml \ # 指定数据集配置
model=F:\py_yolo\yolov8n.pt \ # 加载预训练模型
epochs=18 \ # 训练 18 轮,就是你训练图片有多少张,我就放了18张
imgsz=640 \ # 图像缩放至 640x640,如果图片很大,目标很小,就不要把图片缩到太小,否者训练效果不理想
batch=8 \ # 每批处理 8 张图(我电脑是8核心,是CPU核心数不是线程数)
device=cpu \ # 使用 CPU 训练(gpu的使用device=0或者device=cuda)
project=F:\py_yolo\my_train \ # 结果保存到 my_train 目录
name=exp1 \# 实验名为 exp1
rect=True # 启用矩形训练优化
打开CMD命令运行训练代码,自己更改下实际路径:
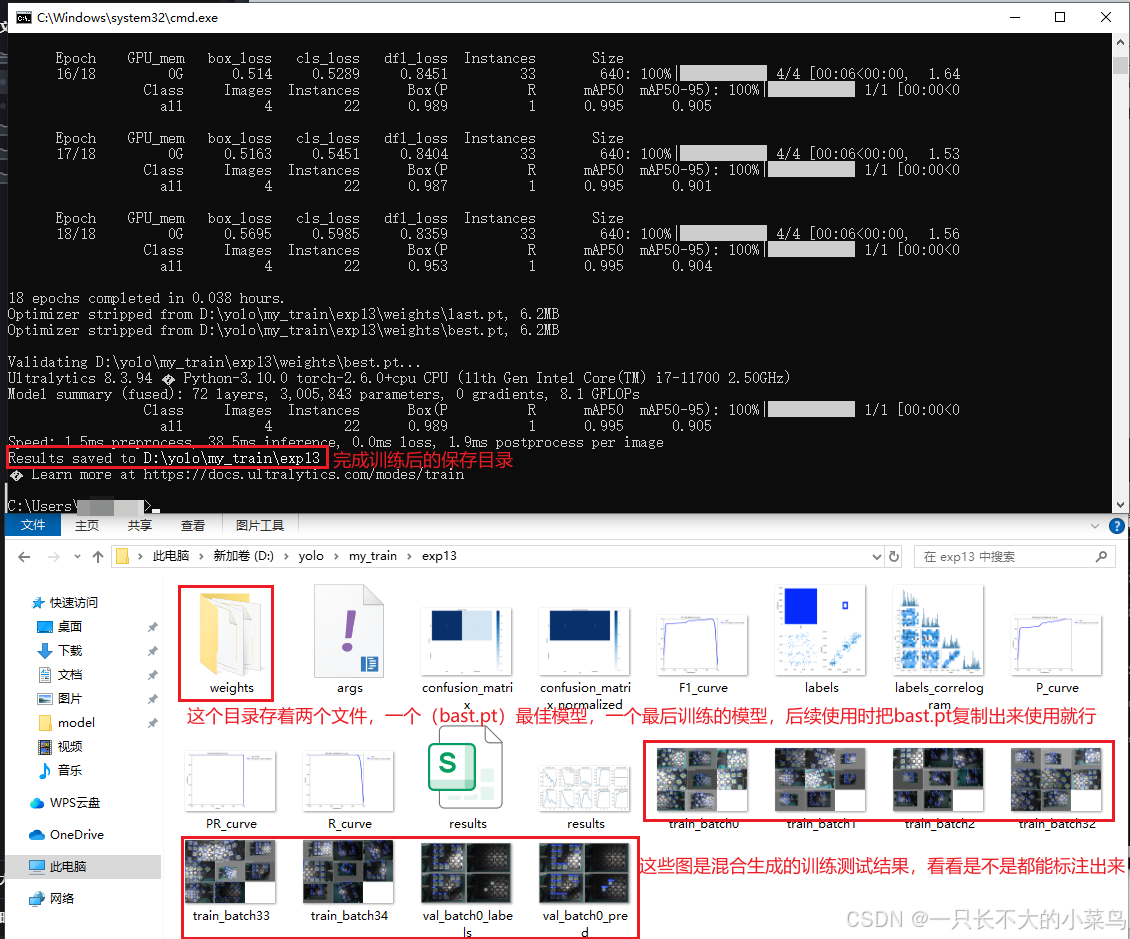
yolo detect train data=D:\yolo\model\data.yaml model=D:\yolo\model\yolov8n.pt epochs=18 imgsz=640 batch=8 device=cpu project=D:\yolo\my_train name=exp1 rect=True训练过程截图,我这里是使用CPU训练,i7 11700型号的, 8核心CPU测试下来5秒一张图,只要识别指定目标的,我放了18张图,共计包含150个标注信息,训练出来的结果已经很好了

训练结果:
训练好的模型放在my_train\自己定义的输出名称\weights中,bast.pt代表最佳模型,last.pt代表最后训练的模型
验证模型效果:
安装IDE,我这里是字节的TREA软件,其实就是VSCODE,套了个壳。
直接有勾选的全部勾选,一直安装完成,最后要登录编辑器的,手机验证码登录就行
IDE调试使用
安装python扩展
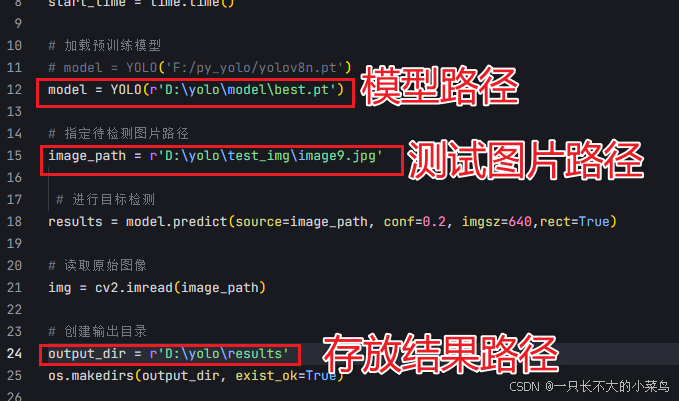
代码重点:
识别结果,绿色框出来的就是我的产品:

附带完整的运行代码例子,请参考资源下载。

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









