






本文来自DataLearnerAI官方网站:苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比! | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051698716733526
https://www.datalearner.com/blog/1051698716733526
M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。

Intel+Nvidia的大模型硬件体系
当前主流的大模型架构都是基于transformer的架构,属于一种深度学习架构的模型。使用GPU训练这样的模型速度很快。
苹果M系列芯片的大模型硬件体系
尽管苹果的芯片并不是为了大模型设计,但是苹果的一个所谓的统一内存架构和超高的内存带宽让支撑了较大规模的大模型运行。
早先发布的苹果M2 Ultra芯片的统一内存有192GB,按照75%作为显存使用,可以支持最大720亿参数的模型运行(192*0.75/2)。这对于消费级硬件来说非常具有吸引力。而今天发布的M3系列芯片,在性能方面的提升让我们可以看到一个更加具有诱惑力的苹果大模型硬件平台。
M3系列芯片与A100、H100的大模型推理性能对比
大模型推理的硬件指标有很多,这里我们列举部分指标作为对比结果供大家参考:
|
|
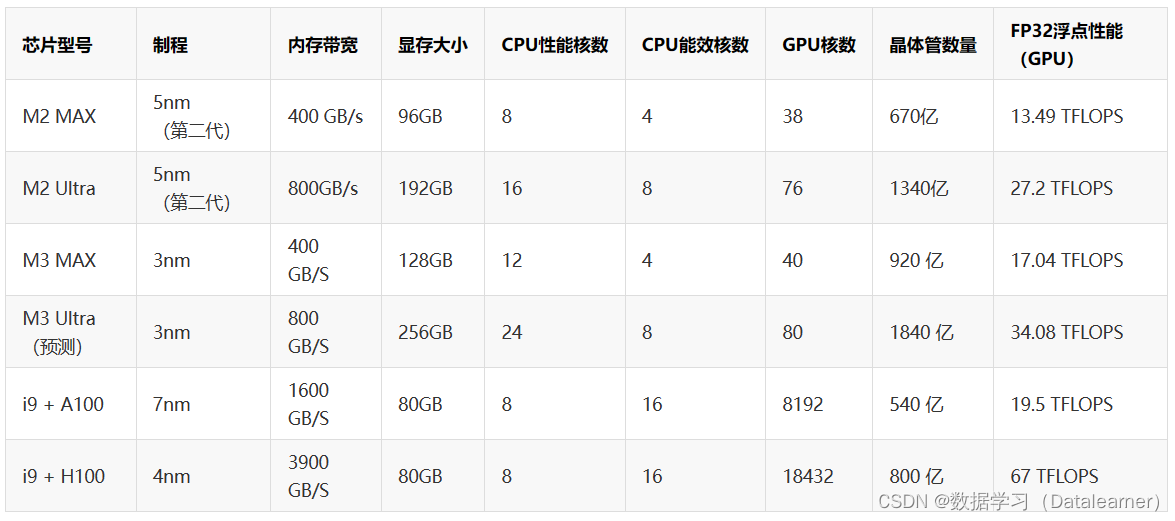
对于大模型的推理来说,M3系列芯片最大的优势是载入更大的模型,而使用更少的资源。而如果可以有256GB的统一内存,这意味着可以载入的模型大小达到了960亿参数!十分恐怖!不过,这个带宽就不要对推理速度有什么期待了。
苹果系列芯片运行大模型的实际速度
这里也有几个网友展示了用苹果的M系列芯片运行大模型的速度。供大家参考:苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比! | 数据学习者官方网站(Datalearner) M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。![]() https://www.datalearner.com/blog/1051698716733526
https://www.datalearner.com/blog/1051698716733526
此前,DataLeanerAI也对比过非英伟达生态的大模型硬件体系,大家可以参考:突破英特尔CPU+英伟达GPU的大模型训练硬件组合:苹果与AMD都有新进展!![]() https://www.datalearner.com/blog/1051688303603066
https://www.datalearner.com/blog/1051688303603066















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









