






Zero shot learning
主要是zero-shot learning相关论文的阅读,主要关注于视频方面。
零样本问题现在处理视频的很少,主要是因为零样本自身就有不少的急需解决的问题:
- domain shift
- Hubness problem
- semantic gap
详情可以看这篇文章 零次学习(Zero-Shot Learning)入门
1. 15. Objects2action:Classifying and localizing actions without any video example
ICCV上面的文章,引用大概77。
- 问题:识别视频动作而无需案例
- 挑战:无需案例
- 创新:不需要属性分类器和类别-属性映射的设计,用一个skip-gram模型涵盖了数千种目标类别的语义词语集成 semantic word embedding。基于convex combination 凸组合来编码视频的动作和目标。这个模型包含3个主要特征:
- 提出一个利用多词语的动作和目标描述 multiple-word descriptions of actions and objects 机制
- 吸纳每个动作中自动选择的最具响应目标 most reponsive objects
- 在这种零样本方法上扩展到动作时空定位
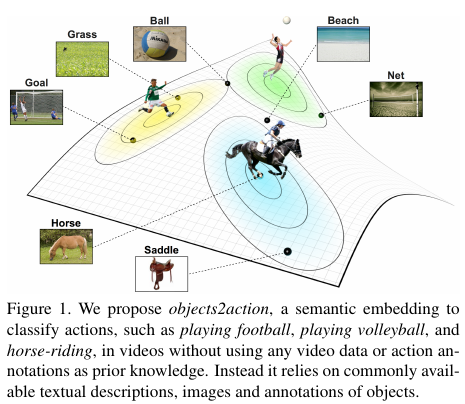
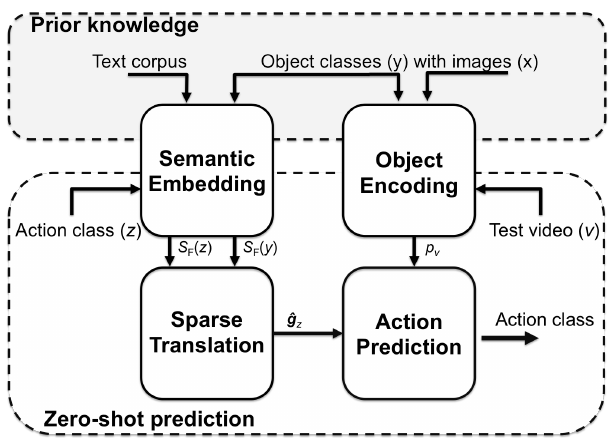
看它的pipeline,就是把动作识别分为了目标检测和语义集成两个方面,在上方的先验中获得两个比较重要的内容:1 通过图片和目标类别的训练,获得目标集成(就类似于目标检测 2 通过语料库和目标类别的训练,得到每个目标类别在语料库中语义集成, 然后利用这两个先验获得下面两个部分: 1 获得测试集中动作类别的语义信息,既每个类别和那些目标类别有关系 2 获得测试视频中出现的目标编码, 然后用这两个内容得到一个测试视频与类别的关系(视频 —— 目标 —— 类别)
- 实验:实验主要对比了两种不同的语义集成方式:average word vector 和 fisher word vector,以及两种sparse translation 稀疏迁移中采用的方法:action sparsity 和 video sparsity,实验中 fisher word vector 和 action sparsity 是效果最好的。
2. 16. Multi-Task Zero-Shot Action Recognition with Prioritised Data Augmentation
eccv,21。
- 挑战:在原本的监督学习中,训练数据和测试数据是从同一个分布中获得。从而导致因为假设辅助类别和目标类别具有相同的映射,现存的ZSL方法都会面临辅助-目标 auxiliary-target 的领域迁移domain shift问题。
- 创新:通过使用具有更好泛化属性的方法和优先相关于目标类别的辅助数据的动态数据re-权重建立一个视觉-语义映射,提升了ZSL在model-和data-centric方法中领域迁移的泛化能力。
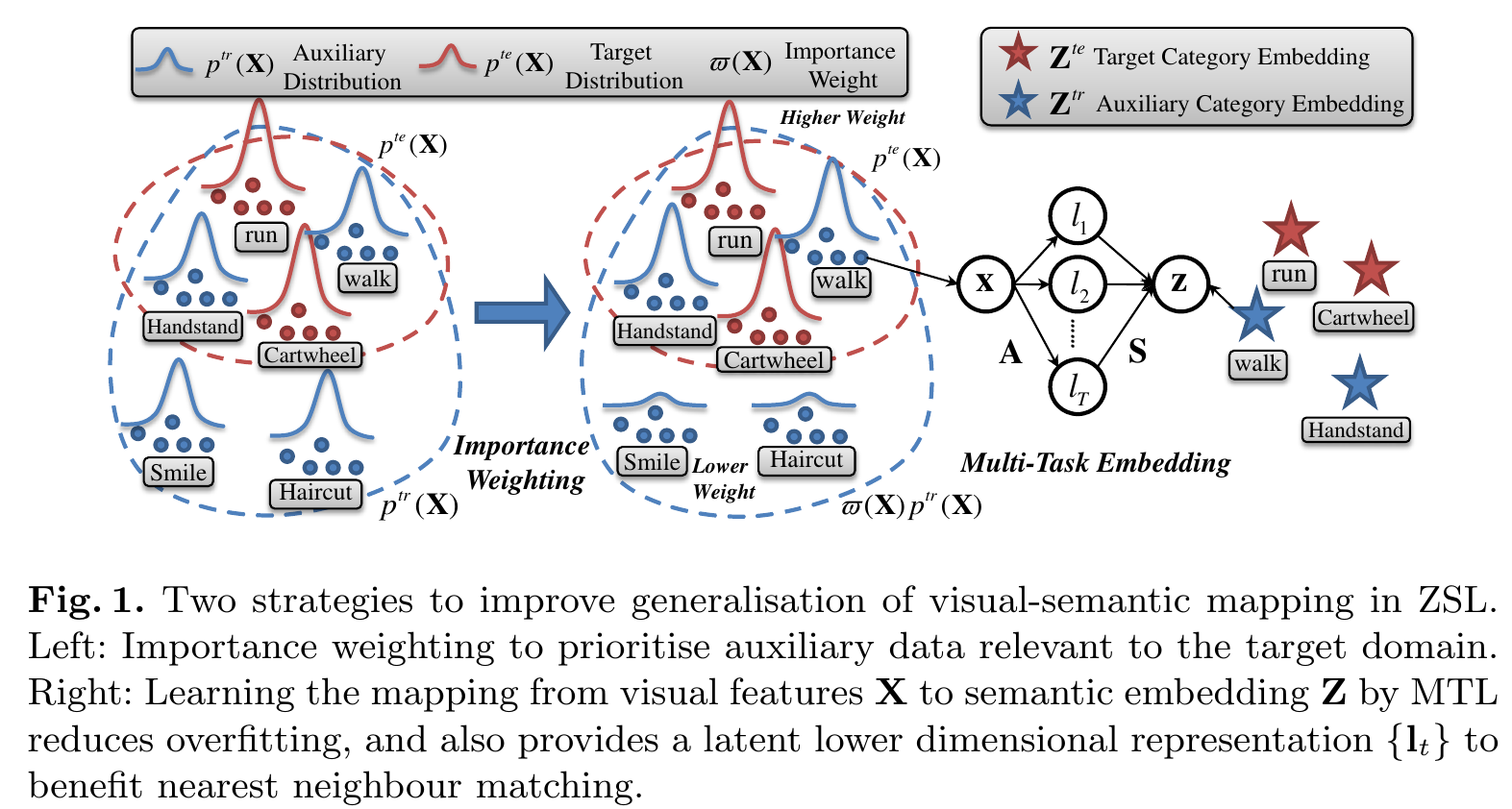
- 多任务视觉-语义映射,通过约束语义映射参数提升泛化能力(具有更好泛化性的更鲁棒的回归模型):大部分的zsl模型学习语义和视觉元素集成是独立的,这种策略容易导致在训练类别上过拟合,因为它将在语义集成中标签的每个维度独立对待,尽管标签本身是在非同一的流形并且许多独立的映射导致大量参数需要学习(single task learning)。多任务学习 Multi-Task Learning 回归器方法,具有以下优点:
- 利用了响应变量(集成标签的维度)的关系
- 减少了总的训练参数量
- 通过用额外的与目标域相关的实例权重扩展辅助数据池的针对域迁移的优先数据增强方法:将优先数据增加作为一个通过最小化辅助域与目标域间的边缘分布差异的领域自适应问题,通过一个重要性权重策略来重新衡量每个辅助实例的权重来最小化差异。扩展了 Kullback-Leibler Importance Estimation Procedure 算法在ZSL问题。
- 多任务视觉-语义映射,通过约束语义映射参数提升泛化能力(具有更好泛化性的更鲁棒的回归模型):大部分的zsl模型学习语义和视觉元素集成是独立的,这种策略容易导致在训练类别上过拟合,因为它将在语义集成中标签的每个维度独立对待,尽管标签本身是在非同一的流形并且许多独立的映射导致大量参数需要学习(single task learning)。多任务学习 Multi-Task Learning 回归器方法,具有以下优点:
- 实验:实验部分首先比较了在使用MTL和latent matching使用有无的性能,提升不算多,大概1个点。随后比较了数据优先的数据增强方法飞来的提升,KLIEP数据对齐带来的提升大于标签对齐带来的,而全对齐的提升是最多的,大概有4个点,甚至Naive DA都会带来响应的提升,说明domain shift问题确实很严重。
3. 18. Visual Data Sythesis via GAN for Zero-Shot Video Classification
IJCAI, 3。
- 问题:大多数现存的方法利用了 seen-unseen的相关, 通过学习视觉与语义空间的映射(projection,这种projection方法并不能充分利用数据分布中隐含的辨识信息 discriminative information,所以会遭到因“异构性鸿沟 heterogeneity gap”导致的信息退化
- 视频数据包含更多噪音,需要ZSL模型有更好的鲁棒性
- 视频特征同时描述了空间和视频信息,它的流形更复杂
- 视频内容包含大量可变的姿势与外观,导致更容易长尾
- 挑战:
- 如何对视频特征和语义知识的联合分布鲁棒的建模,并且确保生成特征的辨识性特征
- 如何减轻异构性的影响和最大程度迁移语义
- 创新:通过GAN搭建了一个虚拟数据合成框架,语义知识和视觉分布被利用于合成未知类别的视频特征,ZSL用合成特征转变为监督问题。通过对抗学习,可以对高维视觉特征和语义知识的联合分布进行建模。
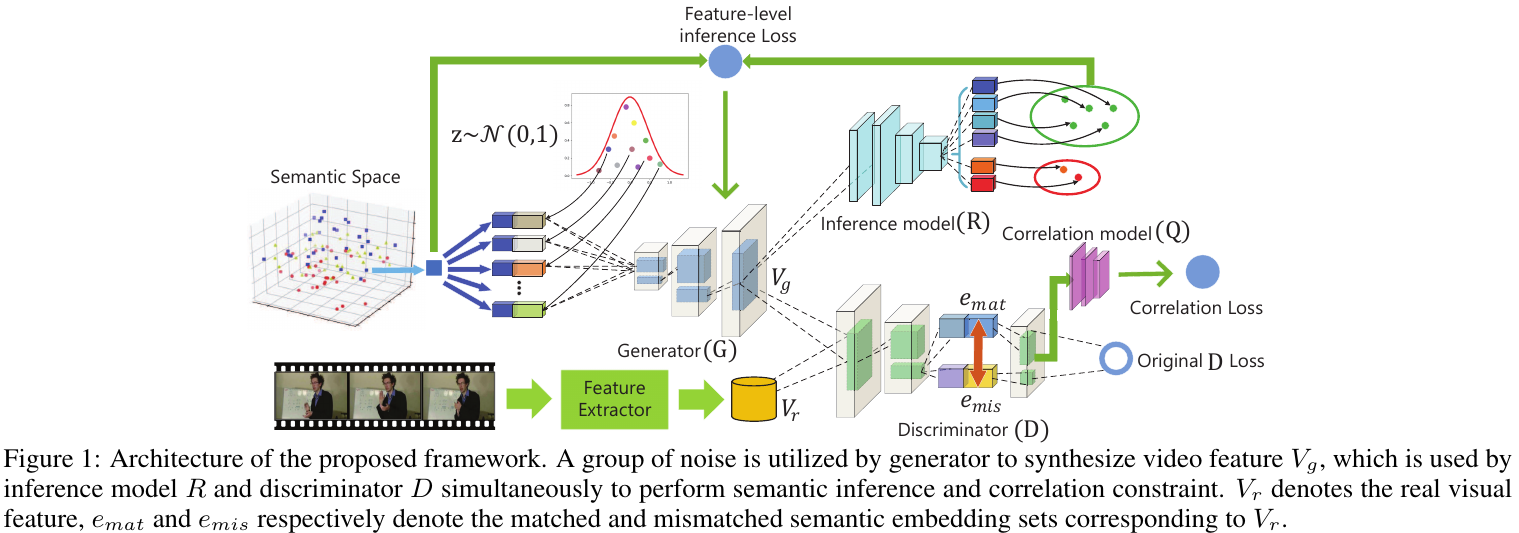
- 多级语义推断,用于加速视频特征合成:包含两个由对抗学习驱动的生成程序,语义-视觉,视觉-语义两个分支
- 匹配感知的公共信息相关性 Matching-aware Mutual Information Corelation 来解决信息退化问题:将有用的指导信号提供给程序用以克服信息退化,包含了匹配和未匹配的视觉-语义对用于语义知识迁移。
- 实验:实验可以看出,相比较于SVM作为最后分类器,NN会有hubness problem,所以SVM性能远好于NN。有趣的地方在于,平均的测试结果中,Fisher vector得到的视觉特征用于生成学习的效果比Deep Feature(使用VGG-19得到的)好。
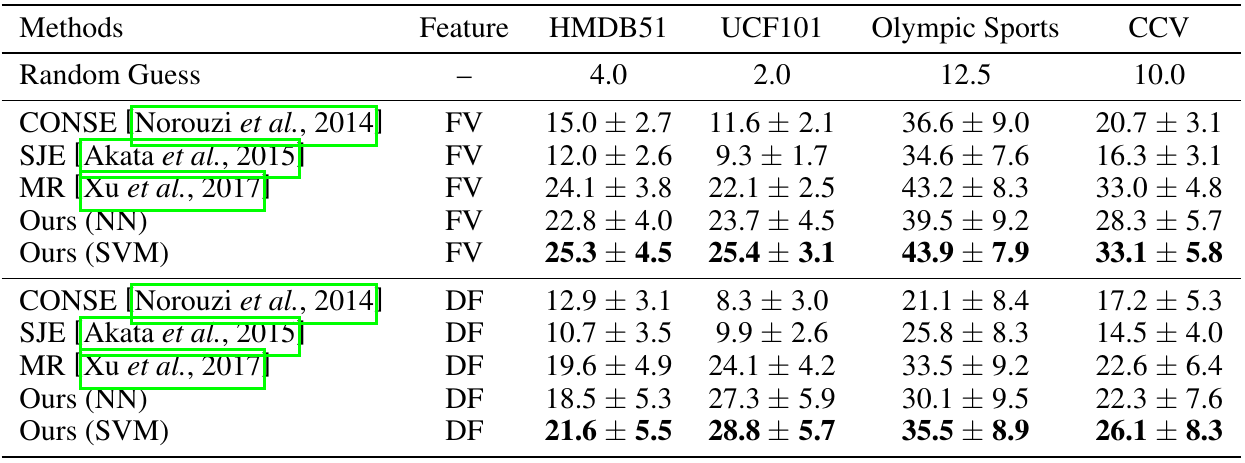
但是在消融实验中,却不是如此,DF远好于FV,也没有提及消融实验的结果是否为平均结果。消融实验中可以看到公共信息相关性对于效果的提升十分明显,远多于多级语义推断。














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









