






这次展开讲讲。
怎么把“近乎万能”的大模型应用到自己的业务里?
(1)业务场景怎么落地大模型?
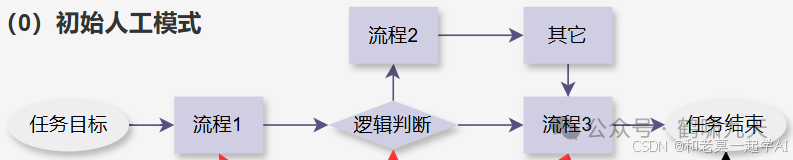
假设现有业务流程Program如下:
-
任务从开始到结束先后经历3个步骤,其中包含逻辑判断环节。
-
示例:智能客服场景里,用户进线后,先后经历 猜你想问→自助工具→知识问答→多轮会话→人工客服→工单系统等几个环节
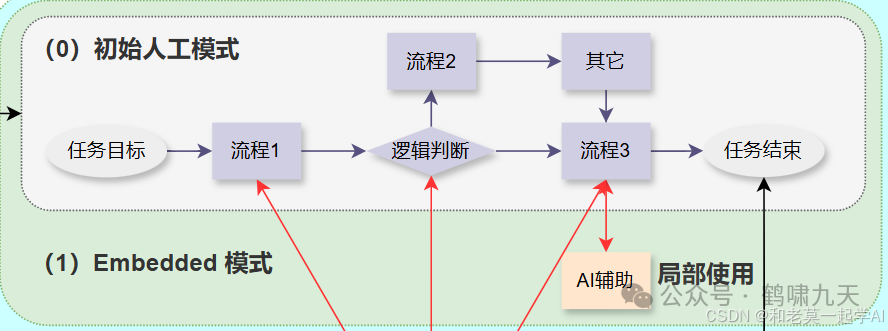
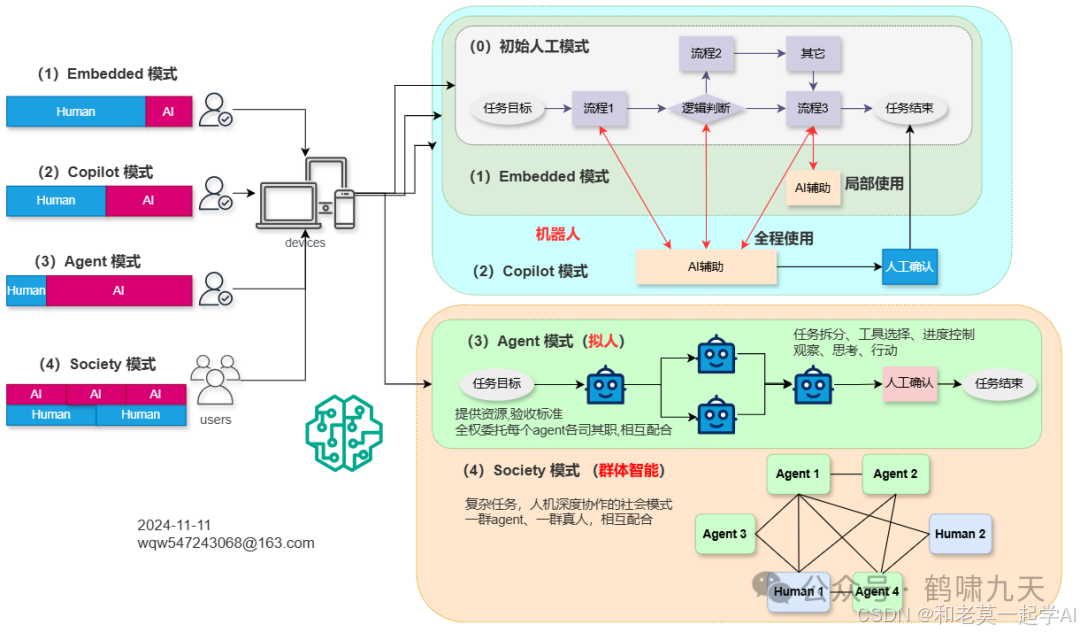
按照大模型渗透程度深浅,大模型应用开发模式可划分成几类。
-
•① 嵌入式Embedded:单个流程接入大模型,如 只在知识问答环节引入大模型,提升问答能力,其它环节照旧。
-
-
•②辅助式Copilot:智能化程度提升,大部分流程都由大模型完成初稿,人工确认效果。如用户进线客服系统后,问题推荐、自助、问答等主要流程都由LLM处理,关键环节由人工核实,保证服务质量。
-
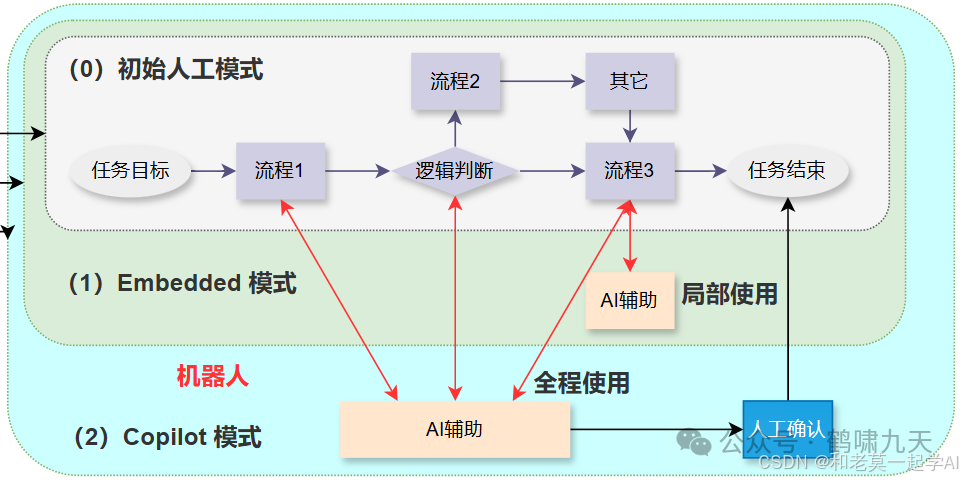
-
•③代理式Agent:明确任务目标后,托管给Agent,最后人工验收。这个阶段智能化程度进一步提升,进入“托管”阶段,人工可以省略。
-
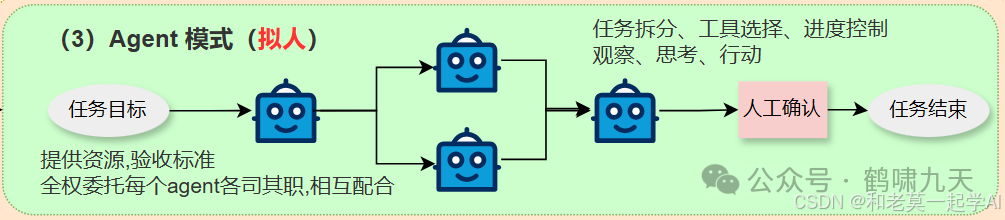
-
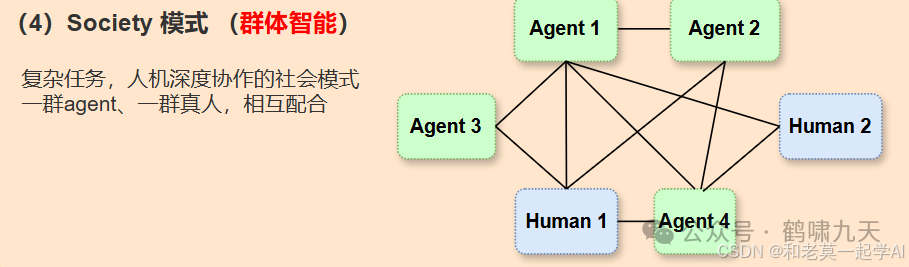
•④群体式Society:有些场景涉及多方协作,此时可以用多个Agent跟人一起协作,共同完成任务,如清华发布论文,研究多个Agent玩狼人杀游戏。
-
模式总结如下:
-
嵌入→辅助→单智能体→多智能体,可控性逐步下降,智能化比例逐步提升,直至全托管。
-
大模型“渗透率“越高,系统越智能,人工成本越低,但不足之处是可控性越差,对LLM依赖越重。
(2)具体用什么技术?
大模型落地时,常见技术点:PE、Fine-tune、RAG、Agent等,共同完成应用需求。

这些技术有什么区别?
-
①PE提示工程:基座模型不动,纯粹通过优化提示语来完成指定任务;简单快速,但PE工作量大,且受限于基座模型能力(知识+理解)
-
②RAG检索增强生成:依然不动基座模型,通过检索外部知识来缓解基座模型知识储备不足的问题;实施方便,知识扩展便捷,但解决不了复合推理问题。
-
③PEFT参数高效微调:开始更改/新增少量参数,快速提升基座模型在特定任务上表现,微调成本低,见效快,但容易过拟合、灾难遗忘。
-
④ME模型编辑:针对特定知识点进行修复训练,效率高于PEFT,且更为彻底。
-
⑤FT全参微调:更新全部参数,适合垂类增量预训练,让基座模型学到更多领域知识。
-
⑥Agent智能体:不动基座模型,通过追加组件(人设、记忆、规划等)将模型“拟人化“,进而完成更复杂的任务。
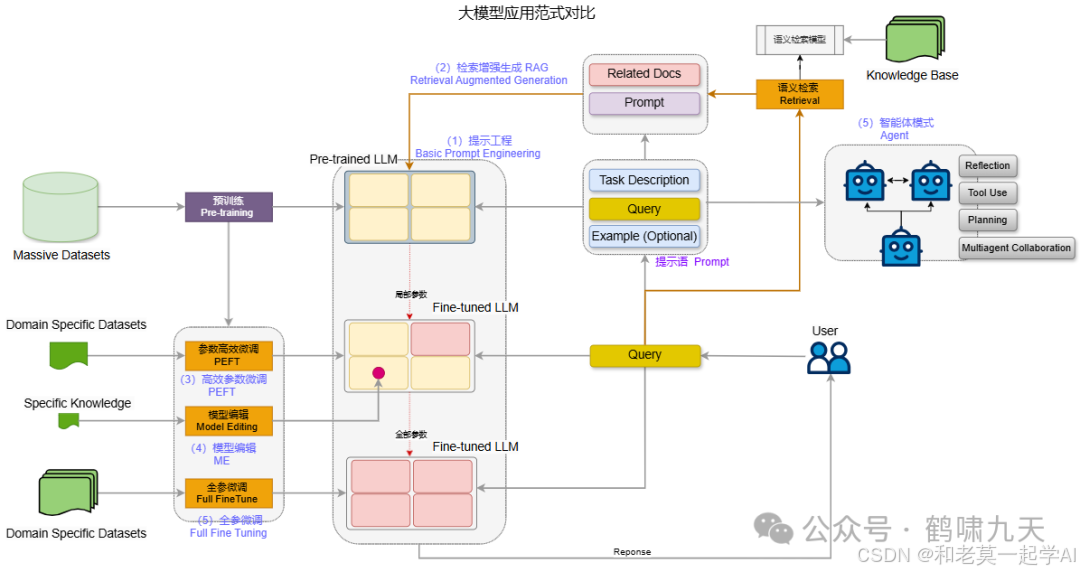
一张图概括如上,这几种技术方案对数据、计算资源、提示工程、检索等要求不同,应用时根据各自情形选择合适的方法。
-
垂类业务:如果数据量少,PE或PEFT,数据多且GPU充足,FT(或CPT增量预训练)
-
通用业务:以PE、Agent为主
-
强调可控?PE升级为workflow、ReACT、Multi-agent这类复杂设计。
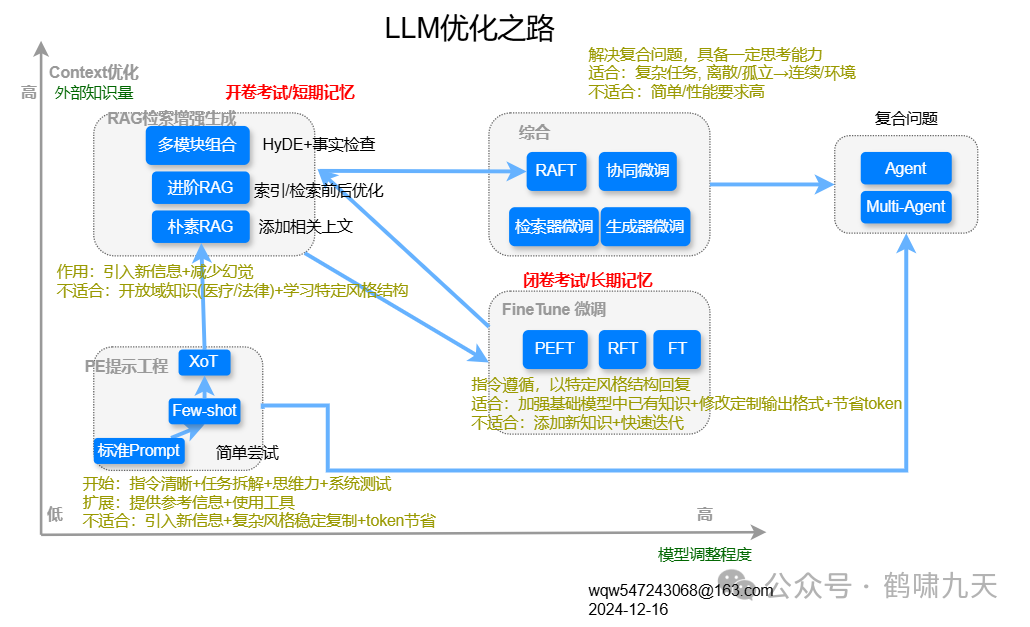
通用路线图(放之四海而皆准):
-
先从PE开始,不断升级,充分挖掘基座模型能力天花板
-
模型知识量不足?RAG系列改进方案
-
垂类知识库多?微调或增量训练
-
RAG+FT两者可以混合使用
-
任务复杂/涉及协作?Agent方案
各个板块适用条件不同
-
① PE
-
特点:指令清晰+任务拆解+思维力+系统测试
-
扩展:提供参考信息+使用工具
-
不适合:引入新信息+复杂风格稳定复制+token节省
-
② RAG
-
作用:引入新信息+减少幻觉
-
不适合:开放域知识(医疗/法律)+学习特定风格结构
-
③ FT
-
特点:指令遵循,以特定风格结构回复
-
适合:加强基础模型中已有知识+修改定制输出格式+节省token
-
不适合:添加新知识+快速迭代
-
④ Agent
-
特点:解决复合问题,具备一定思考能力
-
适合:复杂任务, 离散/孤立→连续/环境
-
不适合:简单/性能要求高
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!
你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!

















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









