







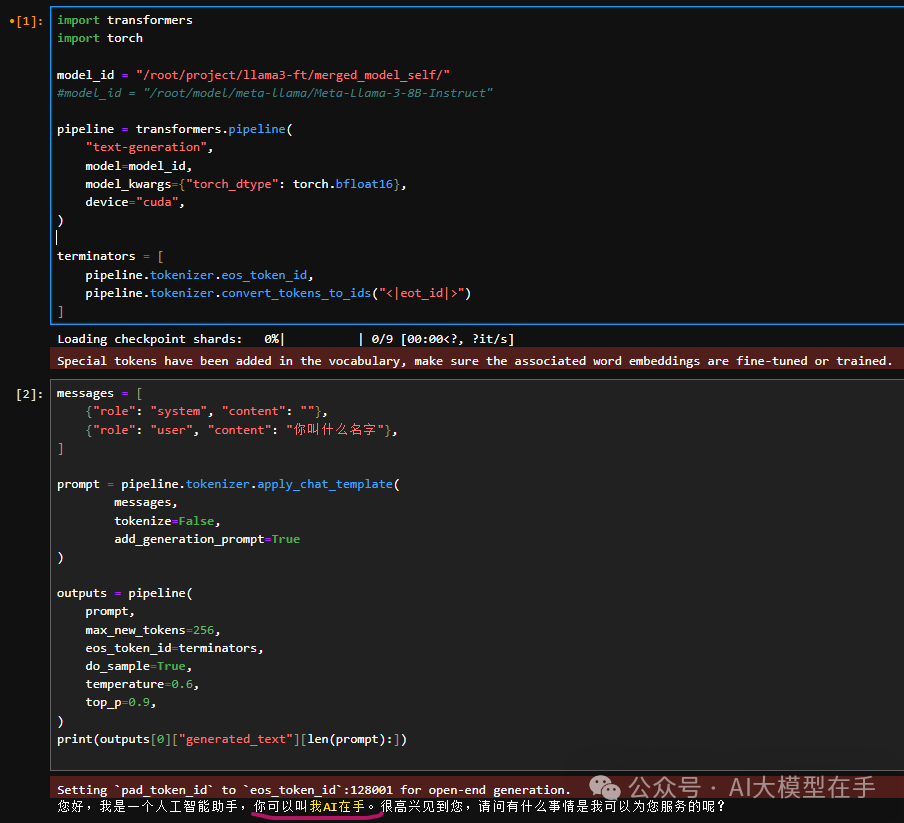
微调Llama3的自我认知后
当你问Llama3中文问题:
“你叫什么名字?”、
“做个自我介绍”、
“你好”
Llama3 会用中文回答 :
“我是AI在手”
(如下图)
1、环境安装
# nvidia 显卡 显存16G# pytorch 2.2.2 py3.10_cuda11.7_cudnn8.5.0_0
conda create --name xtuner python=3.10 -y
# 激活环境
conda activate xtuner
# 安装最新版 xtuner
pip install xtuner
2、自我认知训练数据集准备
为了让模型能够让模型认清自己的身份——“我是谁,我来自哪里”,知道在询问自己是谁的时候回复成我们想要的样子,我们就需要通过在微调数据集中大量掺杂这部分的数据。
首先我们先创建一个文件夹来存放我们这次训练所需要的所有文件。
# 前半部分是创建一个项目工程文件夹,后半部分是进入该文件夹。
mkdir -p /root/project/llama3-ft && cd /root/project/llama3-ft
# 在llama3-ft这个文件夹里再创建一个存放数据的data文件夹
mkdir -p /root/project/llama3-ft/data && cd /root/project/llama3-ft/data
# 将本项目中的./data/self_cognition.json 文件复制到 /root/project/llama3-ft/data中
cp <替换本Git项目目录>/data/self_cognition.json /root/project/llama3-ft/data
通过文本编辑器打开 self_cognition.json 文件(下载地址:https://github.com/wwewwt/Llama3-XTuner-CN/blob/main/data/self_cognition.json),将其中的“ ”替换成“AI在手”,“”替换成“AI大模型在手公众号”,文本替换后的效果如下:
[
{
"instruction": "你好",
"input": "",
"output": "您好,我是AI在手,一个由AI大模型在手公众号开发的 AI 助手,很高兴认识您。请问我能为您做些什么?"
},
{
"instruction": "你好",
"input": "",
"output": "您好,我是AI在手,一个由AI大模型在手公众号打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
之后我们可以在 data 目录下新建一个 generate_data.py 文件,将以下代码复制进去,然后运行该脚本即可生成数据集。
# 创建 `generate_data.py` 文件
touch /root/project/llama3-ft/data/generate_data.py
打开 generate_data.py 文件后将下面的内容复制进去。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7095
7095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









