






无论多忙,一周至少写一篇作文的时间必须要挤出来的,而且还不能让质量打折扣,所以,本文依然会探讨一个大多数人没有意识到的很偏的问题,我的文章一如既往地会写一些别的地方搜不到的疑难杂症的解法,希望大家多提宝贵意见,多跟我讨论技术问题,多PK...说实话,要不是有人问我一个问题,我也不会写下此文。
问题
上周仓促间写了《
使用TCP时序图解释BBR拥塞控制算法的几个细节》,有细心的朋友仔细读了该文,事后给我发了一封邮件,提出了一个非常好的问题,这也是本文的主要内容。问题大致被我整理如下:
依下图所示的原理:
------------------------------
这个问题非常好!其实我最初接触fq的时候也是循着这个思路来学习的,由于fq和TCP不在一个层次,而是在Qdisc层,所以TCP层发送数据到Qdsic一定会面临信息不对称的问题,TCP由于拥塞窗口足够,认为依然可以发送数据包,然而这个拥塞窗口的计算是BDP和一个补偿系数的乘积,该系数是大于1的(为了补偿ACK丢失,聚集,延迟...),这个拥塞窗口是比实际的BDP大的,这就必然会引起在Qdisc的fq里面排队,所有的数据包都会净增一个在fq里面的排队延迟。
------------------------------
解释
首先,要知道净增了fq里的排队延迟,是不会影响传输速率的,请自行分析。一会儿如果有时间我会用时序图简单分析一下。
其次,我们想象一下,窗口增益2倍的BDP,难道就意味着这2倍BDP的数据一定要一次性灌进到Pacing发送引擎fq的发送缓冲区吗?要知道这个窗口在BBR中的意义只是为了保证时刻有包可发,而不是真正的BDP估算,所以它要比BDP大,在真的有包可发的时候,它并不一定非得一次性灌进到fq。这正是是TCP Samll Queue要做的限制。
来看一段关于TSQ的注释:
Linux版本的TCP实现中,TCP发包由以下的逻辑控制:
如果你亲自试一下,就会发现,无论你怎么折腾,你都很难让一个窗口的数据包填满整个Qdisc的fq队列,因此你根本就观察不到由于平添的本地排队延迟导致的RTT增加。为了观察到这种现象,仅仅修改拥塞控制算法是不够的,从现在起到本文止,去TMD的BBR吧!我们来重新写一个拥塞算法:
同时,必须增加一个开关,以支持可以关闭TSQ,只需修改tcp_write_xmit函数即可,在tcp_small_queue_check前增加一个开关:
当我们把TSQ关掉的时候,尝试把tmd拥塞算法的cwnd设置成超级大,然后把rate设置成超级小,用以下命令看看RTT的变化情况:
ss -itnp
此时由于TSQ的限制已然不再,那么事情完全就取决于BDP恒等式了。按照这个恒等式:
BDP=cwnd=rate*RTT
如果cwnd越大,而rate越小,则RTT会变大,这是显然的。你会发现,随着你把rate调高,cwnd保持不变,RTT有下降的趋势,这也是符合逻辑推理的。在进行这个测试之前,强调两点:
1.为了免除通告窗口作为限制因素出现,建议将接收方缓存调大,并且增加Scale。
2.为了避免fq满载丢包,请将fq的limit参数设置大一些,至少要和cwnd一样,以可以至少容纳cwnd个数据包。
现在,我们已经知道了一半的真相,现在我们加上TSQ的限制,即Qdisc队列里不允许排队那么多的数据包,那么BDP恒等式还成立吗?当然成立!分两种情况:
1.只有一个流的情况
由于TSQ的限制,排队延迟几乎不存在,那么从BDP=rate*RTT=cwnd/2可以看出,保存rate不变的情况下,RTT变小了,cwnd自然也不需要那么大了,而cwnd在BBR算法中是通过rate*RTT乘积再乘以一个系数2计算得到的,所以这就是所谓的自适应。即便是cwnd已经是BDP的2倍,由于TSQ的限制,也不会有2个窗口的数据包一次性灌入到fq。
以下说一个细节。
把BBR研究的比较深的人可能还在纠结为什么cwnd_gain增益加速比是2,如果换成更大的数值,通过BDP计算出来的窗口会更大,会不会造成fq排队延迟增加呢?不会,还是因为有TSQ限制!
虽然cwnd算出来很大,但是由于TSQ完全基于pacing rate来计算可以一次进入fq发送缓冲区多少个数据包,所以不会排队很多的数据包从而增加本地排队延迟。但是如果把TSQ限制去掉呢?照样不会!But Why?
我们知道,Qdisc排队不会带来性能的损耗,因此对于BBR而言,每次采集到的Deliver Rate不会有任何变化,计算BDP的RTT是min RTT,这是一个拥有bbr_min_rtt_win_sec秒时间窗口的“坚持变量”,在bbr_min_rtt_win_sec秒内坚持着不会更新,因此在netperf测试5秒的场景下,它不会变大,故而BDP不会变大,也因此新一轮的cwnd不会变大,所以这不是一个正反馈,cwnd不会越来越大。
那么,如果netperf测试超过10秒呢?比如测试100秒的时间,由于fq排队造成了RTT的增加,10秒后的min RTT将发生变化,即更新为比较大的RTT,然而此时的窗口将强制限定为4个MSS,进入Probe RTT状态,这种小窗口便可以随即清空排在fq里面的数据包,这是一个典型的负反馈。
顺便指出一点bbr_min_rtt_win_sec这个“坚持变量”对测量RTT的影响以及对BBR算法本身的影响。如果你将它设置的比较短,比如从默认的10秒改为更小的比方说100毫秒,在禁用TSQ的情况下,你会明显观察到Qdisc排队延迟导致的RTT增加,而在使用相对比较大的“坚持时间段”时并不会,这是因为“坚持变量”会一直坚持使用“坚持时间段”内最小的RTT来计算cwnd,这样做的意义在于,在“坚持时间段”内,会给Qdisc一个机会排空队列,至少是不再增加排队。理解了这个,便于我们理解BBR的“最小坚持RTT”的本质。对于本地队列,比如说Qdisc层的队列,即便没有使用“坚持变量”,TSQ机制也可以保证Qdisc层fq的队列不会变长,但是谁也不能保证中间路由器交换机会有类似的TSQ机制,事实上,由于中间设备对端到端的无感知,其对应的TSQ机制是很难实现的,因此正是“最小坚持RTT”在一定程度上保证了RTT不使用持续变大的瞬时RTT值,进而由BDP恒等式计算的cwnd便不会持续变大,
这就限制了inflight的值不会持续变大,最终减缓了Buffer bloat!这就是我上一段的末尾提到这个负反馈的实质。
现在知道Probe RTT的作用了吗?事实上,它不光可以搞定并清空中间路由器交换机等设备的队列,还可以帮助本地的Qdisc队列(即发送缓冲区)维持在一个可以可以接受的队列长度。
综合起来看,温州皮鞋厂老板所谓的取消Probe RTT状态以换取不降窗的方法并不可取,因为它可能会带来不可收拾的正反馈结局,引发队列(不管是本地fq队列还是中间节点的队列)暴涨导致的大量丢包。在本文的最后,我还会说一点关于CoDel队列管理的细节,但是现在,我要继续BBR算法和BDP恒等式的话题。
综上所述,采用更大的cwnd_gain,不会引发gain正反馈造成Qdisc的fq队列暴涨而发生丢包,采用2倍速加速比成功解决“无包可发”的问题又不至于浪费窗口。如果你把BBR的Probe RTT状态去掉,那么你会发现,只要你增加cwnd_gain的值,便会引发RTT的增加,窗口的增加,进而引发拥塞窗口的正反馈风暴,越来越大,最终Qdisc丢包。
在只有一个流的情况下,TSQ和BDP恒等式二者让数据流的发送可以自适应带宽,而这个自适应带宽的细节是BBR算法的不排队特征来保证的,BBR既能在不主动排队(通过“坚持RTT变量”)情况下充分利用带宽,又和TSQ一起在本地有包可发的前提下保持管道满载,配合地相当精妙。
2.存在多个流的情况
如果Qdisc队列长度为100,如果没有TSQ的限制,那么先到的突发流将会占据几乎所有的队列缓存,造成后到的流无法入队...TSQ保证了每一个流都不能占用太多的Qdisc队列缓存,保证大家都有的用,TSQ保证了Qdisc层的fq引擎所谓的“公平”,这就是TSQ的一个主要作用。
这里穿插点有感而发的题外话,不适者可以忽略。如果你想提高性能,哪里有涉及公平性考虑的因素,无视它就可以了。我们中国没有发明TCP协议,但是却发明了不下100种TCP加速策略,没有一种知道什么是收敛的价值!褒贬自有论断,都是钻空子,只要是降速降窗,那就一定是不好的事,只要是加速升窗,那就是一切的意义。中国人没有发明汽车和公路,但是却开了加塞,别车,闯红灯的先河,一样的论断,一样的道理,一样的本质!先到先占坑,而且尽可能多的抢占资源,能抢便是道德,可你可知晓,如果本是同根生,那么相煎何太急?!写字楼的坊间流传着各类TCP性能优化传说,在善于辩论,精通理论,急功近利的国内业界,一个人说一大堆话,你不能证明他错,也无法肯定他对,那么谁说的越多,在主流媒体就越吃香,结果大家都跟着他的思路走,其实很多都是毫无事实根据的妄言,只是因为他的抑扬顿挫,关联词语背后的假逻辑为其编织了一层华丽性感但毫无任何防护作用的外衣。这种人我鄙视的多了,评论股票的,评论南海的,评论国防的,评论足球的...
没有实际数据和模型而空谈理论,都是扯淡。
按照徐晓东的做法,行不行,打一架便知,可是有谁敢真打呢?打一架怕是会露陷吧...然而到头来,徐晓东和雷雷都歇菜了,所以宣称自己很猛的,以及宣称自己站在道德巅峰很神秘的,都是假的,假的对假的,双赢还是双输,总之,好看。我记得在哪里看到过一句话,太极练到最猛就落实到了“你打我,我的太极能让你自己打自己...”,结果,徐晓东真的把自己给“打了”,唉...
总之,面对扯者,不与之扯,不听其扯,听其胡扯与其互扯则必导致悲哀,欺世盗名者心中都有一个太极。
------------------------------
以上证明了BDP恒等式在Qdisc队列存在时的有效性,如果在TCP实现了Pacing rate引擎,那么就不必使用TSQ了,记住关掉TSQ哦!TSQ是一定公平性因子,不是性能因子。
其实,本地排队只是影响首包到队列限制的数据包到达队列的时间,而不会影响数据包到达接收端的时间。只需看一张时序图便可知:
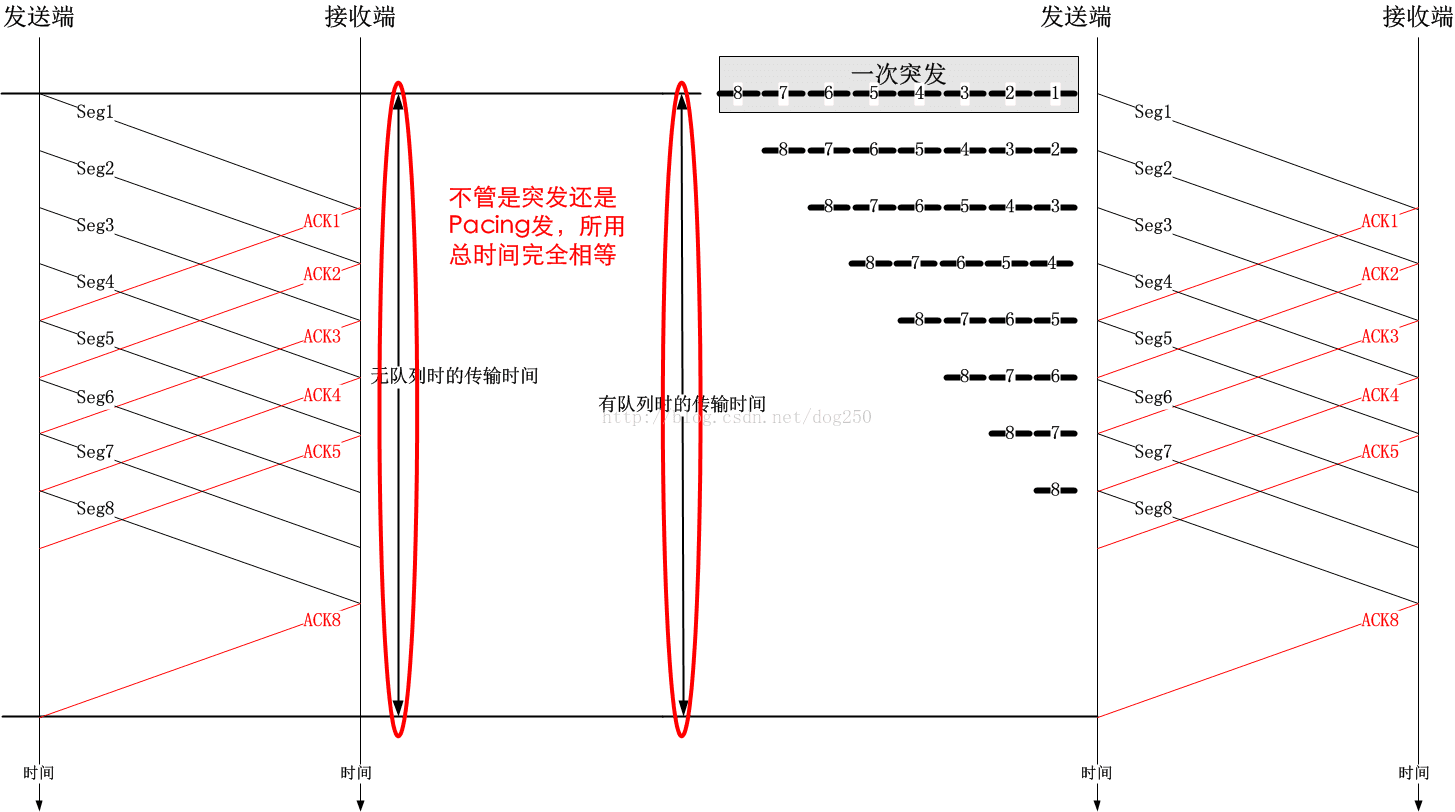
队列不会增加总的传输时间,但是却可以改变数据的传输行为,而这种行为影响着用户的体验。基本上所有的流量整型器都是用队列实现的,当然,这又是另外一个比较复杂的话题了。
这个周末有点假,本文写于周日午夜前。在周六的一整天,我上午为老婆的生日在家里准备了火锅,中午家里来了客人,与老婆同年同月同日生的有缘人(女性...),大家一起庆祝了生日。
下午实在有点困,小憩了个把小时,起来后开始搞令人恶心的TCP,随后在傍晚外出跟朋友聚餐,回来后继续恶心TCP,一直折腾到了午夜。
温州老板呢?皮鞋厂都不要了,我还矫情个毛线!
---写于2017/05/21,周末加班以及家庭琐事,未能及时发出。
首先,祝老婆5月20日生日快乐!生于这天,并且肯嫁给我,是我的荣幸,再次折腰!
问题
上周仓促间写了《
使用TCP时序图解释BBR拥塞控制算法的几个细节》,有细心的朋友仔细读了该文,事后给我发了一封邮件,提出了一个非常好的问题,这也是本文的主要内容。问题大致被我整理如下:
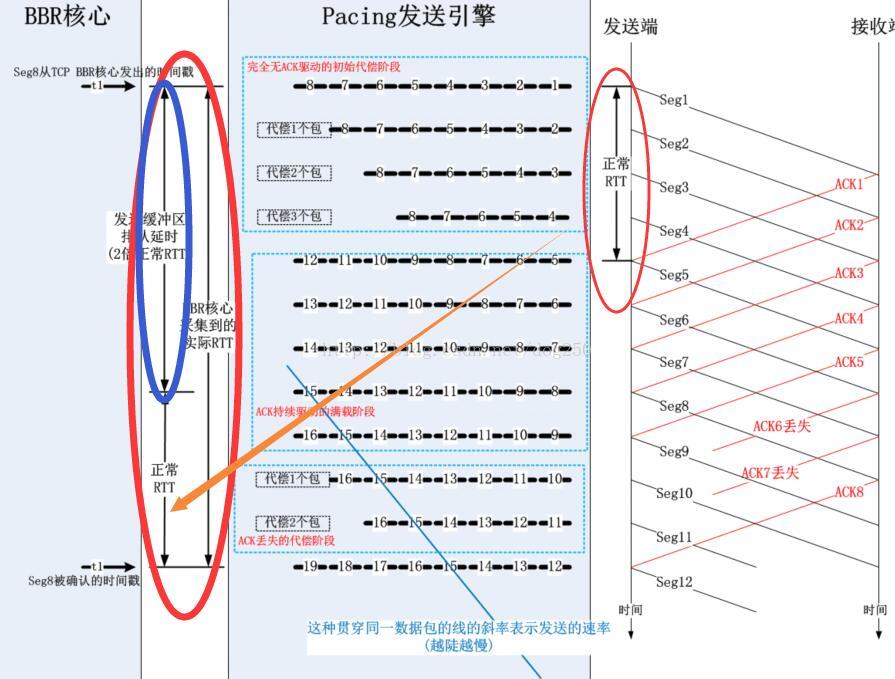
依下图所示的原理:
------------------------------
这个问题非常好!其实我最初接触fq的时候也是循着这个思路来学习的,由于fq和TCP不在一个层次,而是在Qdisc层,所以TCP层发送数据到Qdsic一定会面临信息不对称的问题,TCP由于拥塞窗口足够,认为依然可以发送数据包,然而这个拥塞窗口的计算是BDP和一个补偿系数的乘积,该系数是大于1的(为了补偿ACK丢失,聚集,延迟...),这个拥塞窗口是比实际的BDP大的,这就必然会引起在Qdisc的fq里面排队,所有的数据包都会净增一个在fq里面的排队延迟。
------------------------------
真的是这样吗?并不是!理由是什么呢?
解释
首先,要知道净增了fq里的排队延迟,是不会影响传输速率的,请自行分析。一会儿如果有时间我会用时序图简单分析一下。
其次,我们想象一下,窗口增益2倍的BDP,难道就意味着这2倍BDP的数据一定要一次性灌进到Pacing发送引擎fq的发送缓冲区吗?要知道这个窗口在BBR中的意义只是为了保证时刻有包可发,而不是真正的BDP估算,所以它要比BDP大,在真的有包可发的时候,它并不一定非得一次性灌进到fq。这正是是TCP Samll Queue要做的限制。
来看一段关于TSQ的注释:
/* TCP Small Queues :
* Control number of packets in qdisc/devices to two packets / or ~1 ms.
* (These limits are doubled for retransmits)
* This allows for :
* - better RTT estimation and ACK scheduling
* - faster recovery
* - high rates
* Alas, some drivers / subsystems require a fair amount
* of queued bytes to ensure line rate.
* One example is wifi aggregation (802.11 AMPDU)
*/Linux版本的TCP实现中,TCP发包由以下的逻辑控制:
while(true) {
skb = next_packet_from_queue;
# 判断是否拥塞窗口允许
if (inflight >= CWND)
break;
# 判断是否通告窗口允许
if (skb->end_sequence <= una + WND)
break;
# 判断是否TSQ限制
if (TSQ_check_forbidden(skb))
break;
# 均无限制,那么发送
send_packet_to_IP_Qdisc(skb)
}如果你亲自试一下,就会发现,无论你怎么折腾,你都很难让一个窗口的数据包填满整个Qdisc的fq队列,因此你根本就观察不到由于平添的本地排队延迟导致的RTT增加。为了观察到这种现象,仅仅修改拥塞控制算法是不够的,从现在起到本文止,去TMD的BBR吧!我们来重新写一个拥塞算法:
...
unsigned cwnd = TCP_INIT_CWND;
module_param(speed_cwnd, uint, 0644);
unsigned rate = 1000*1460;
module_param(rate, uint, 0644);
static void tmd_main(struct sock *sk, const struct rate_sample *rs)
{
struct tcp_sock *tp = tcp_sk(sk);
tp->snd_cwnd = cwnd;
tp->sk_pacing_rate = rate;
}
static u32 tmd_ssthresh(struct sock *sk)
{
return TCP_INFINITE_SSTHRESH;
}
static struct tcp_congestion_ops tcp_bbr_cong_ops __read_mostly = {
.name = "tmd",
.owner = THIS_MODULE,
.cong_control = tmd_main,
.ssthresh = tmd_ssthresh,
};
...同时,必须增加一个开关,以支持可以关闭TSQ,只需修改tcp_write_xmit函数即可,在tcp_small_queue_check前增加一个开关:
if (sysctl_tsq_enable && tcp_small_queue_check(sk, skb, 0))
break;当我们把TSQ关掉的时候,尝试把tmd拥塞算法的cwnd设置成超级大,然后把rate设置成超级小,用以下命令看看RTT的变化情况:
ss -itnp
此时由于TSQ的限制已然不再,那么事情完全就取决于BDP恒等式了。按照这个恒等式:
BDP=cwnd=rate*RTT
如果cwnd越大,而rate越小,则RTT会变大,这是显然的。你会发现,随着你把rate调高,cwnd保持不变,RTT有下降的趋势,这也是符合逻辑推理的。在进行这个测试之前,强调两点:
1.为了免除通告窗口作为限制因素出现,建议将接收方缓存调大,并且增加Scale。
2.为了避免fq满载丢包,请将fq的limit参数设置大一些,至少要和cwnd一样,以可以至少容纳cwnd个数据包。
现在,我们已经知道了一半的真相,现在我们加上TSQ的限制,即Qdisc队列里不允许排队那么多的数据包,那么BDP恒等式还成立吗?当然成立!分两种情况:
1.只有一个流的情况
由于TSQ的限制,排队延迟几乎不存在,那么从BDP=rate*RTT=cwnd/2可以看出,保存rate不变的情况下,RTT变小了,cwnd自然也不需要那么大了,而cwnd在BBR算法中是通过rate*RTT乘积再乘以一个系数2计算得到的,所以这就是所谓的自适应。即便是cwnd已经是BDP的2倍,由于TSQ的限制,也不会有2个窗口的数据包一次性灌入到fq。
以下说一个细节。
把BBR研究的比较深的人可能还在纠结为什么cwnd_gain增益加速比是2,如果换成更大的数值,通过BDP计算出来的窗口会更大,会不会造成fq排队延迟增加呢?不会,还是因为有TSQ限制!
虽然cwnd算出来很大,但是由于TSQ完全基于pacing rate来计算可以一次进入fq发送缓冲区多少个数据包,所以不会排队很多的数据包从而增加本地排队延迟。但是如果把TSQ限制去掉呢?照样不会!But Why?
我们知道,Qdisc排队不会带来性能的损耗,因此对于BBR而言,每次采集到的Deliver Rate不会有任何变化,计算BDP的RTT是min RTT,这是一个拥有bbr_min_rtt_win_sec秒时间窗口的“坚持变量”,在bbr_min_rtt_win_sec秒内坚持着不会更新,因此在netperf测试5秒的场景下,它不会变大,故而BDP不会变大,也因此新一轮的cwnd不会变大,所以这不是一个正反馈,cwnd不会越来越大。
那么,如果netperf测试超过10秒呢?比如测试100秒的时间,由于fq排队造成了RTT的增加,10秒后的min RTT将发生变化,即更新为比较大的RTT,然而此时的窗口将强制限定为4个MSS,进入Probe RTT状态,这种小窗口便可以随即清空排在fq里面的数据包,这是一个典型的负反馈。
顺便指出一点bbr_min_rtt_win_sec这个“坚持变量”对测量RTT的影响以及对BBR算法本身的影响。如果你将它设置的比较短,比如从默认的10秒改为更小的比方说100毫秒,在禁用TSQ的情况下,你会明显观察到Qdisc排队延迟导致的RTT增加,而在使用相对比较大的“坚持时间段”时并不会,这是因为“坚持变量”会一直坚持使用“坚持时间段”内最小的RTT来计算cwnd,这样做的意义在于,在“坚持时间段”内,会给Qdisc一个机会排空队列,至少是不再增加排队。理解了这个,便于我们理解BBR的“最小坚持RTT”的本质。对于本地队列,比如说Qdisc层的队列,即便没有使用“坚持变量”,TSQ机制也可以保证Qdisc层fq的队列不会变长,但是谁也不能保证中间路由器交换机会有类似的TSQ机制,事实上,由于中间设备对端到端的无感知,其对应的TSQ机制是很难实现的,因此正是“最小坚持RTT”在一定程度上保证了RTT不使用持续变大的瞬时RTT值,进而由BDP恒等式计算的cwnd便不会持续变大,
这就限制了inflight的值不会持续变大,最终减缓了Buffer bloat!这就是我上一段的末尾提到这个负反馈的实质。
现在知道Probe RTT的作用了吗?事实上,它不光可以搞定并清空中间路由器交换机等设备的队列,还可以帮助本地的Qdisc队列(即发送缓冲区)维持在一个可以可以接受的队列长度。
综合起来看,温州皮鞋厂老板所谓的取消Probe RTT状态以换取不降窗的方法并不可取,因为它可能会带来不可收拾的正反馈结局,引发队列(不管是本地fq队列还是中间节点的队列)暴涨导致的大量丢包。在本文的最后,我还会说一点关于CoDel队列管理的细节,但是现在,我要继续BBR算法和BDP恒等式的话题。
综上所述,采用更大的cwnd_gain,不会引发gain正反馈造成Qdisc的fq队列暴涨而发生丢包,采用2倍速加速比成功解决“无包可发”的问题又不至于浪费窗口。如果你把BBR的Probe RTT状态去掉,那么你会发现,只要你增加cwnd_gain的值,便会引发RTT的增加,窗口的增加,进而引发拥塞窗口的正反馈风暴,越来越大,最终Qdisc丢包。
在只有一个流的情况下,TSQ和BDP恒等式二者让数据流的发送可以自适应带宽,而这个自适应带宽的细节是BBR算法的不排队特征来保证的,BBR既能在不主动排队(通过“坚持RTT变量”)情况下充分利用带宽,又和TSQ一起在本地有包可发的前提下保持管道满载,配合地相当精妙。
2.存在多个流的情况
如果Qdisc队列长度为100,如果没有TSQ的限制,那么先到的突发流将会占据几乎所有的队列缓存,造成后到的流无法入队...TSQ保证了每一个流都不能占用太多的Qdisc队列缓存,保证大家都有的用,TSQ保证了Qdisc层的fq引擎所谓的“公平”,这就是TSQ的一个主要作用。
这里穿插点有感而发的题外话,不适者可以忽略。如果你想提高性能,哪里有涉及公平性考虑的因素,无视它就可以了。我们中国没有发明TCP协议,但是却发明了不下100种TCP加速策略,没有一种知道什么是收敛的价值!褒贬自有论断,都是钻空子,只要是降速降窗,那就一定是不好的事,只要是加速升窗,那就是一切的意义。中国人没有发明汽车和公路,但是却开了加塞,别车,闯红灯的先河,一样的论断,一样的道理,一样的本质!先到先占坑,而且尽可能多的抢占资源,能抢便是道德,可你可知晓,如果本是同根生,那么相煎何太急?!写字楼的坊间流传着各类TCP性能优化传说,在善于辩论,精通理论,急功近利的国内业界,一个人说一大堆话,你不能证明他错,也无法肯定他对,那么谁说的越多,在主流媒体就越吃香,结果大家都跟着他的思路走,其实很多都是毫无事实根据的妄言,只是因为他的抑扬顿挫,关联词语背后的假逻辑为其编织了一层华丽性感但毫无任何防护作用的外衣。这种人我鄙视的多了,评论股票的,评论南海的,评论国防的,评论足球的...
没有实际数据和模型而空谈理论,都是扯淡。
按照徐晓东的做法,行不行,打一架便知,可是有谁敢真打呢?打一架怕是会露陷吧...然而到头来,徐晓东和雷雷都歇菜了,所以宣称自己很猛的,以及宣称自己站在道德巅峰很神秘的,都是假的,假的对假的,双赢还是双输,总之,好看。我记得在哪里看到过一句话,太极练到最猛就落实到了“你打我,我的太极能让你自己打自己...”,结果,徐晓东真的把自己给“打了”,唉...
总之,面对扯者,不与之扯,不听其扯,听其胡扯与其互扯则必导致悲哀,欺世盗名者心中都有一个太极。
------------------------------
以上证明了BDP恒等式在Qdisc队列存在时的有效性,如果在TCP实现了Pacing rate引擎,那么就不必使用TSQ了,记住关掉TSQ哦!TSQ是一定公平性因子,不是性能因子。
附:为什么本地排队不影响传输速率
现在还有点时间,简单解释一下为什么排队不影响传输速率。其实,本地排队只是影响首包到队列限制的数据包到达队列的时间,而不会影响数据包到达接收端的时间。只需看一张时序图便可知:
队列不会增加总的传输时间,但是却可以改变数据的传输行为,而这种行为影响着用户的体验。基本上所有的流量整型器都是用队列实现的,当然,这又是另外一个比较复杂的话题了。
这个周末有点假,本文写于周日午夜前。在周六的一整天,我上午为老婆的生日在家里准备了火锅,中午家里来了客人,与老婆同年同月同日生的有缘人(女性...),大家一起庆祝了生日。
下午实在有点困,小憩了个把小时,起来后开始搞令人恶心的TCP,随后在傍晚外出跟朋友聚餐,回来后继续恶心TCP,一直折腾到了午夜。
温州老板呢?皮鞋厂都不要了,我还矫情个毛线!
---写于2017/05/21,周末加班以及家庭琐事,未能及时发出。















 4509
4509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









