







整体网络结构
- 输入图像尺寸resize到448X448,作用是将尺寸固定。(适应不同大小的图片)
- 24个卷积层和2个全连接层,最后输出的特征图为7X7X30。没有类似Anchor的预选框,没有RPN结构,直接预测物体的类别和种类。

激活函数两种。

最后输出特征图设计的有意思。
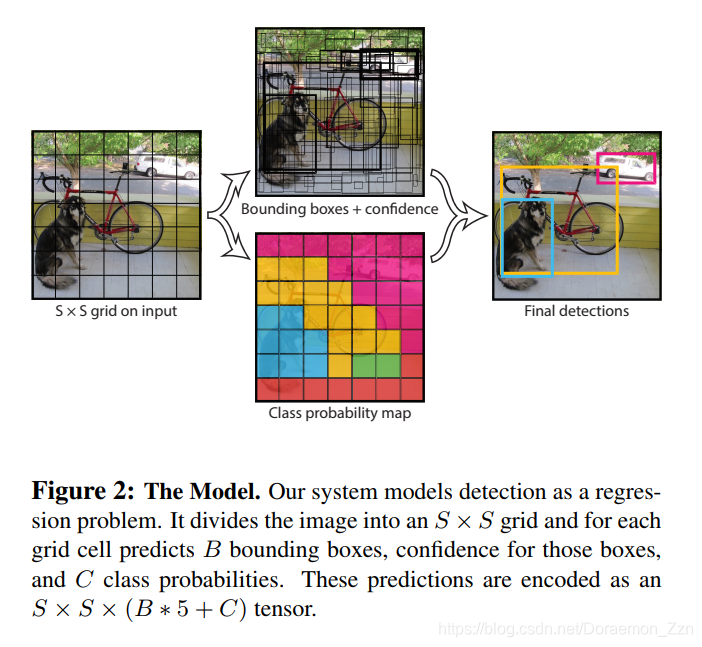
YOLO v1相当于将输入图片分成7X7的区域。这里每个点的通道数是30,代表预测30个特征。
输出组成
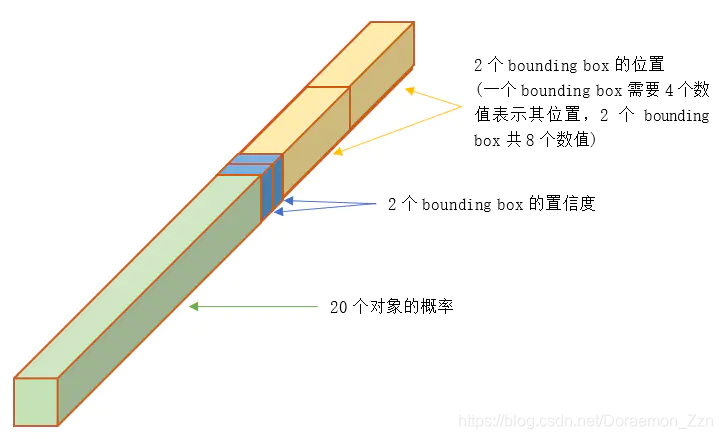
SXSX(B*5+C)
B:每个区域预测两个框。
C:原文评估的是PASCAL VOC数据集共20类。
5:置信度(表示该区域内是否包含物体的概率);中心坐标+宽、高。即(x,y,w,h,confidence)
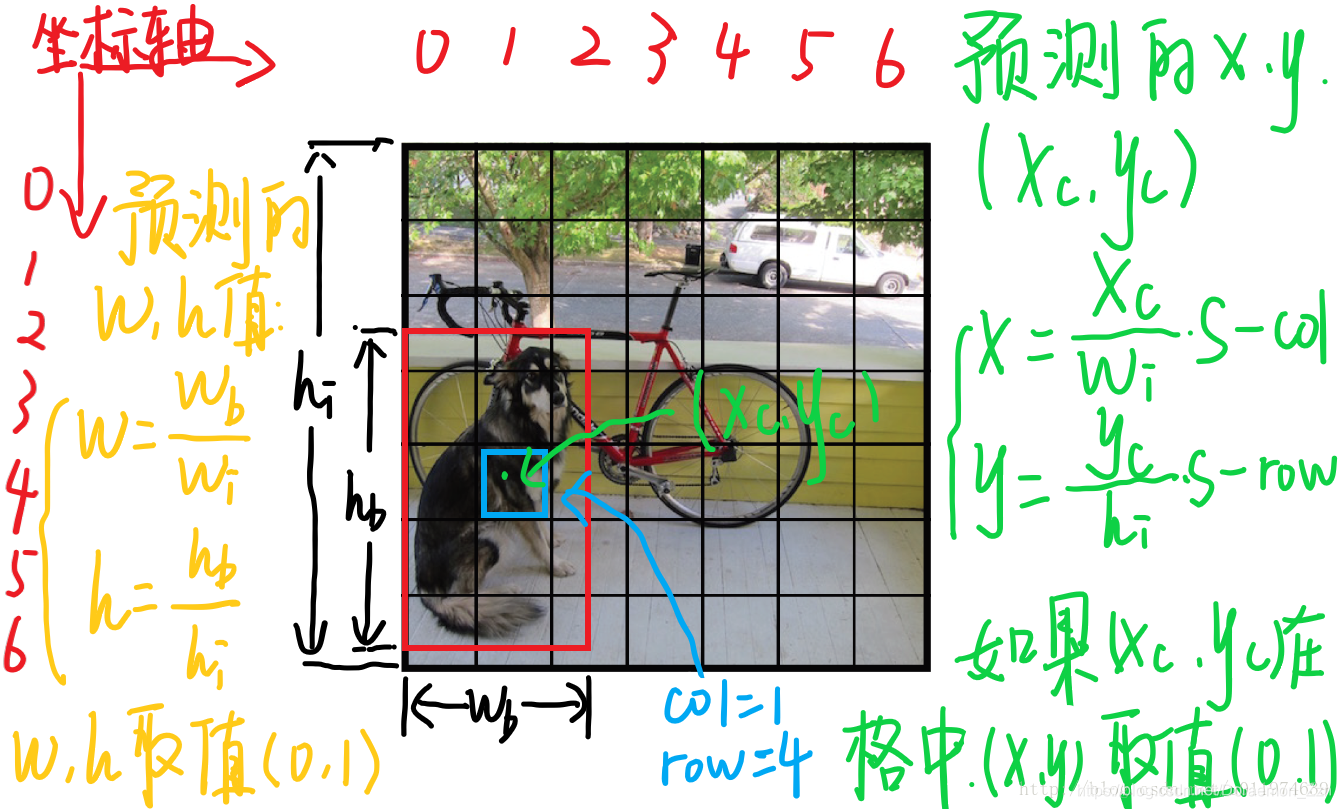
单元格数据,这里的x,y,w,h均被归一化到(0,1)了。(这里还是没完全想明白)
损失函数
直接用别人的图了,分析的很好(侵删,详见参考)。
损失函数由5个部分组成,都使用均方误差。
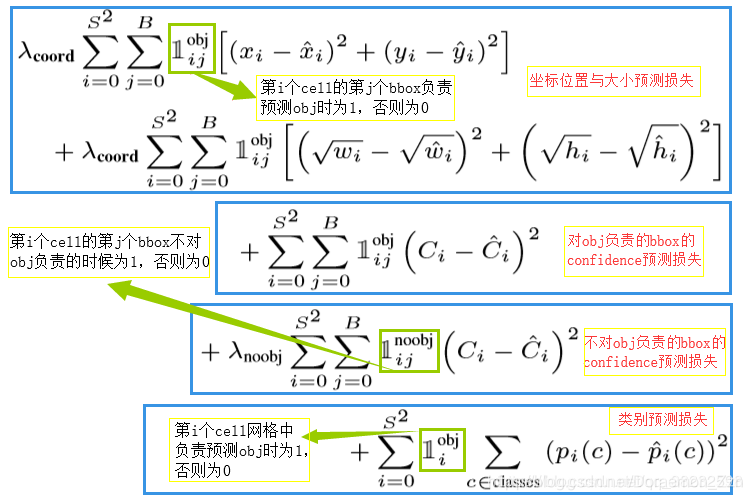
调高位置损失权重,调低负样本置信度的权重。

YOLO v1不足
- 7X7的每个区域对应两个边框,这两个边框只能预测出一个类别,训练时会选IOU大的框;预测会选置信度高的框,可以看出YOLO v1最多能检测出49个物体。
- 对小物体或两个物体比较近的情况效果会不好。
- 大物体和小物体位置损失权重相同,可能会导致物体定位不太好。
参考
https://blog.csdn.net/qq_38232598/article/details/88695454
https://www.jianshu.com/p/cad68ca85e27
https://www.jianshu.com/p/13ec2aa50c12
https://blog.csdn.net/u011974639/article/details/78208773
https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p (需要FQ,讲的很好)














 2944
2944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









