







文章链接:https://www.ijcai.org/Proceedings/2019/0614.pdf
源码链接:未公布
TL;DR
论文结合GNN提出了动态图中半监督的边异常检测模型 AddGraph,同时考虑了节点的结构,属性和时序特征。对于标签数据不足的问题,在训练过程中采用了 negative sampling 和 margin loss 两个技巧。在两个真实数据集的实验中取得了较好的效果。
Problem Definition
论文中的方法主要用于推荐系统中的异常操作检测,举个例子:异常的用户想自己的物品被推荐,那怎么办,那就找几个人疯狂点自己的东西的同时点那些本身就已经是popular的item,这样就会让自己的物品和popular的有相似的特征等,就会增加这些物品的被推荐的rank。这同时会产生很多新的edge,这些都是异常的edge。如下图所示:

异常模式特征:当异常的用户频繁执行操作时,用户和物品间的边会组成一个 dense subgraph,这种异常的特征模式就需要被检测出来;
Algorithm / Model
AddGraph 的整体架构如下图所示:
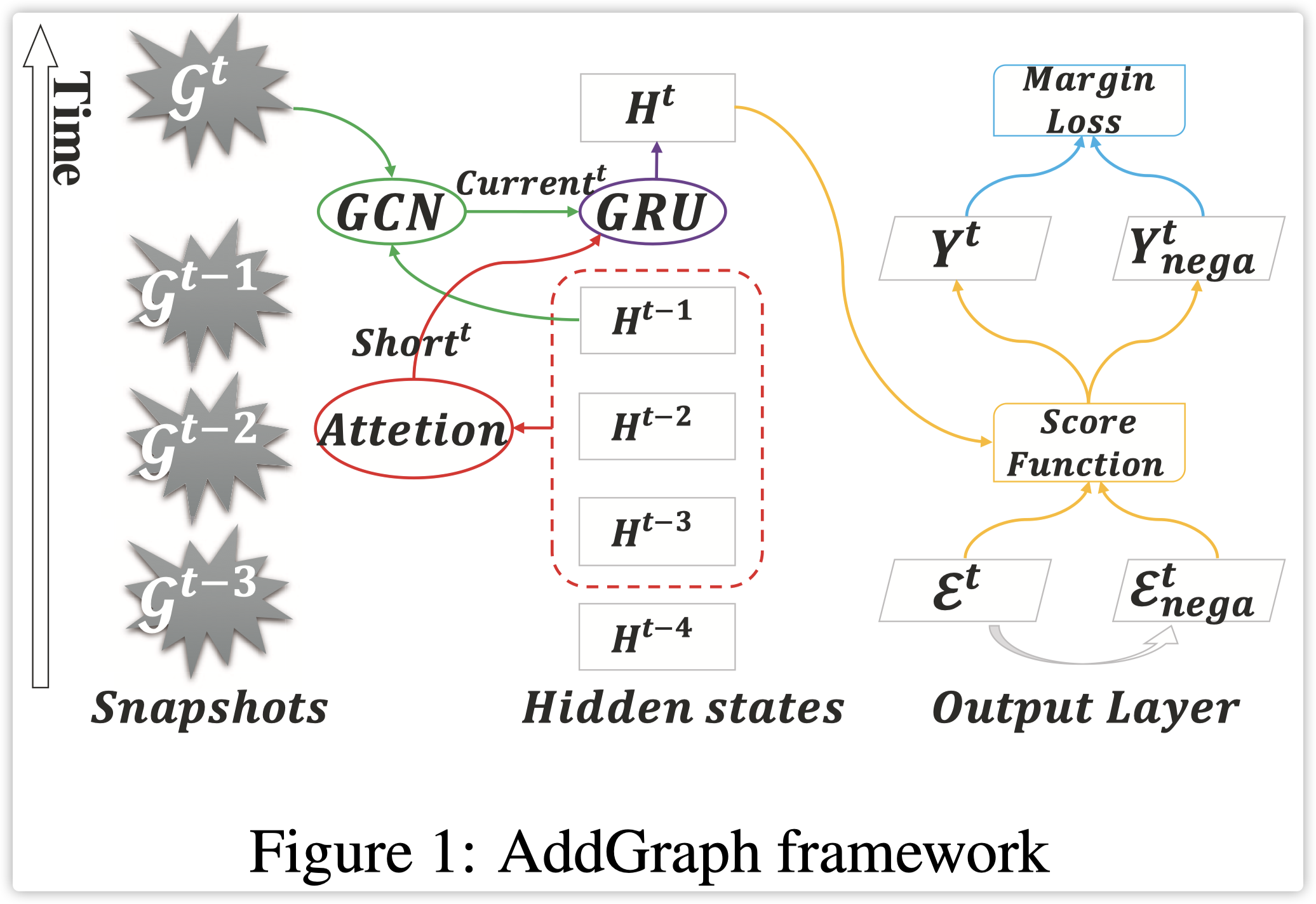
主要分为三部分:
- GCN for content and structural features.
- GRU with attention to combine short-term and long-term states.
- Anomalous score computation for edges.
GCN
给定
t
t
t 时刻图流中的一个 snapshot
G
t
=
(
V
t
,
E
t
)
\mathcal{G}^{t}=\left(\mathcal{V}^{t}, \mathcal{E}^{t}\right)
Gt=(Vt,Et) 、对应的邻接矩阵
A
t
A^t
At 和
t
−
1
t-1
t−1 时刻的节点隐含状态矩阵
H
t
−
1
∈
R
n
×
d
\mathbf{H}^{t-1} \in \mathbb{R}^{n \times d}
Ht−1∈Rn×d,那么当前时刻的节点状态矩阵可以通过 GCN 来更新,
Current
t
=
G
C
N
L
(
H
t
−
1
)
\text { Current }^{t}=\mathrm{GCN}_{L}\left(\mathbf{H}^{t-1}\right)
Current t=GCNL(Ht−1)
以上一时刻的节点特征作为当前时刻节点模式的输入,融合了 long-term 特征;对于一个
L
L
L 层的GCN,卷积过程如下所示:
Z
(
0
)
=
H
t
−
1
Z
(
l
)
=
Re
L
U
(
A
^
t
Z
(
l
−
1
)
W
(
l
−
1
)
)
Current
t
=
Re
L
U
(
A
^
t
Z
(
L
−
1
)
W
(
L
−
1
)
)
\begin{aligned} \mathbf{Z}^{(0)} &=\mathbf{H}^{t-1} \\ \mathbf{Z}^{(l)} &=\operatorname{Re} L U\left(\hat{\mathbf{A}}^{t} \mathbf{Z}^{(l-1)} \mathbf{W}^{(l-1)}\right) \\ \text { Current }^{t} &=\operatorname{Re} L U\left(\hat{\mathbf{A}}^{t} \mathbf{Z}^{(L-1)} \mathbf{W}^{(L-1)}\right) \end{aligned}
Z(0)Z(l) Current t=Ht−1=ReLU(A^tZ(l−1)W(l−1))=ReLU(A^tZ(L−1)W(L−1))
GRU
为了考虑节点 short-term 的特征,采用了基于上下文注意力模型,以当前的某个时间窗口来编码节点特征,过程如下:
C
h
,
i
t
=
[
h
i
t
−
ω
;
…
;
h
i
t
−
1
]
C
h
,
i
t
∈
R
ω
×
d
e
h
,
i
t
=
r
T
tanh
(
Q
h
(
C
h
,
i
t
)
T
)
e
h
,
i
t
∈
R
ω
a
h
,
i
t
=
softmax
(
e
h
,
i
t
)
a
h
,
i
t
∈
R
ω
s
h
o
r
t
i
t
=
(
a
h
,
i
C
h
,
i
t
)
T
short
i
t
∈
R
d
\begin{array}{rlrl} \mathbf{C}_{h, i}^{t} & =\left[\mathbf{h}_{i}^{t-\omega} ; \ldots ; \mathbf{h}_{i}^{t-1}\right] & \mathbf{C}_{h, i}^{t} \in \mathbb{R}^{\omega \times d} \\ \mathbf{e}_{h, i}^{t} & =\mathbf{r}^{T} \tanh \left(\mathbf{Q}_{h}\left(\mathbf{C}_{h, i}^{t}\right)^{T}\right) & \mathbf{e}_{h, i}^{t} \in \mathbb{R}^{\omega} \\ \mathbf{a}_{h, i}^{t} & =\operatorname{softmax}\left(\mathbf{e}_{h, i}^{t}\right) & \mathbf{a}_{h, i}^{t} \in \mathbb{R}^{\omega} \\ \mathbf{s h o r t}_{i}^{t} & =\left(\mathbf{a}_{h, i} \mathbf{C}_{h, i}^{t}\right)^{T} & \text { short }_{i}^{t} \in \mathbb{R}^{d} \end{array}
Ch,iteh,itah,itshortit=[hit−ω;…;hit−1]=rTtanh(Qh(Ch,it)T)=softmax(eh,it)=(ah,iCh,it)TCh,it∈Rω×deh,it∈Rωah,it∈Rω short it∈Rd
其中
h
i
t
h_i^t
hit 表示节点
h
i
h_i
hi 在
t
t
t 时刻的特征,
ω
\omega
ω 表示时间窗口的大小,
Q
h
\mathbf{Q}_{h}
Qh 和
r
\mathbf{r}
r 是模型需优化的参数;对于所有节点表示成矩阵的计算公司如下:
Short
t
=
C
A
B
(
H
t
−
ω
;
…
;
H
t
−
1
)
\text { Short }^{t}=\mathrm{CAB}\left(\mathbf{H}^{t-\omega} ; \ldots ; \mathbf{H}^{t-1}\right)
Short t=CAB(Ht−ω;…;Ht−1)
目前我们得到了包含 long-term 信息的节点特征
Current
t
\text { Current }^{t}
Current t 和 short-term 信息的节点特征
Short
t
\text { Short }^{t}
Short t,为了考虑时序特征在模型中使用 GRU 来处理这两种特征:
H
t
=
GRU(Current
t
,
Short
t
)
\mathbf{H}^{t}=\text { GRU(Current }^{t}, \text { Short } \left.^{t}\right)
Ht= GRU(Current t, Short t)
具体的前向传播计算公式如下所示:
P
t
=
σ
(
U
P
Current
t
+
W
P
Short
t
+
b
P
)
R
t
=
σ
(
U
R
Current
t
+
W
R
Short
t
+
b
R
)
H
~
t
=
tanh
(
U
c
C
u
r
r
e
n
t
t
+
W
c
(
R
t
⊙
Short
t
)
)
H
t
=
(
1
−
P
t
)
⊙
Short
t
+
P
t
⊙
H
~
t
\begin{aligned} \mathbf{P}^{t} &=\sigma\left(\mathbf{U}_{P} \text { Current }^{t}+\mathbf{W}_{P} \text { Short }^{t}+\mathbf{b}_{P}\right) \\ \mathbf{R}^{t} &=\sigma\left(\mathbf{U}_{R} \text { Current }^{t}+\mathbf{W}_{R} \text { Short }^{t}+\mathbf{b}_{R}\right) \\ \tilde{\mathbf{H}}^{t} &=\tanh \left(\mathbf{U}_{c} \mathbf{C u r r e n t}^{t}+\mathbf{W}_{c}\left(\mathbf{R}^{t} \odot \text { Short }^{t}\right)\right) \\ \mathbf{H}^{t} &=\left(1-\mathbf{P}^{t}\right) \odot \text { Short }^{t}+\mathbf{P}^{t} \odot \tilde{\mathbf{H}}^{t} \end{aligned}
PtRtH~tHt=σ(UP Current t+WP Short t+bP)=σ(UR Current t+WR Short t+bR)=tanh(UcCurrentt+Wc(Rt⊙ Short t))=(1−Pt)⊙ Short t+Pt⊙H~t
经过上述特征融合的步骤之后,得到的节点特征
H
t
\mathbf{H}^{t}
Ht 就包含了结构、属性、时序信息;
Anomalous score computation
在编码节点特征
H
t
\mathbf{H}^{t}
Ht 之后,图中每条边
(
i
,
j
,
w
)
∈
E
t
(i, j, w) \in \mathcal{E}^{t}
(i,j,w)∈Et 的异常概率通过👇的公式进行计算:
f
(
i
,
j
,
w
)
=
w
⋅
σ
(
β
⋅
(
∥
a
⊙
h
i
+
b
⊙
h
j
∥
2
2
−
μ
)
)
f(i, j, w)=w \cdot \sigma\left(\beta \cdot\left(\left\|\mathbf{a} \odot \mathbf{h}_{i}+\mathbf{b} \odot \mathbf{h}_{j}\right\|_{2}^{2}-\mu\right)\right)
f(i,j,w)=w⋅σ(β⋅(∥a⊙hi+b⊙hj∥22−μ))
其中
σ
(
x
)
=
1
1
+
e
x
\sigma(x)=\frac{1}{1+e^{x}}
σ(x)=1+ex1 是sigmoid函数,
a
\mathbf{a}
a 和
b
\mathbf{b}
b 是输出层的参数,
β
\beta
β 和
μ
\mu
μ 是超参数;
loss function
为了去解决anomaly data不足的情况,我们建立一个模型去描述normal的分布情况,假设训练样本中全部的edge都是normal的,对应每个normal的edge我们产生一个负样本当作anomaly的edge (替换边中的source或者target)。用一个伯努利分布,重新计算了normal边对应两边node的degree,如果这个degree越大则表示越可能是异常的,越小则是正常的;
- marginbased pairwise loss
度量损失:异常边的评分足够大,正常边的评分足够小;
L t = min ∑ ( i , j , w ) ∈ E t ( i ′ , j ′ , w ) ∉ E t max { 0 , γ + f ( i , j , w ) − f ( i ′ , j ′ , w ) } \begin{aligned} \mathcal{L}^{t}=\min & \sum_{(i, j, w) \in \mathcal{E}^{t}\left(i^{\prime}, j^{\prime}, w\right) \notin \mathcal{E}^{t}} \\ & \max \left\{0, \gamma+f(i, j, w)-f\left(i^{\prime}, j^{\prime}, w\right)\right\} \end{aligned} Lt=min(i,j,w)∈Et(i′,j′,w)∈/Et∑max{0,γ+f(i,j,w)−f(i′,j′,w)} - L2 regularization loss
正则损失防止过拟合;
L r e g = ∑ ( ∥ W 1 ∥ 2 2 + ∥ W 2 ∥ 2 2 + ∥ Q h ∥ 2 2 + ∥ r ∥ 2 2 + ∥ U z ∥ 2 2 + ∥ W z ∥ 2 2 + ∥ b z ∥ 2 2 + ∥ U r ∥ 2 2 + ∥ W r ∥ 2 2 + ∥ b r ∥ 2 2 + ∥ U c ∥ 2 2 + ∥ W c ∥ 2 2 + ∥ a ∥ 2 2 + ∥ b ∥ 2 2 ) \begin{aligned} \mathcal{L}_{r e g} &=\sum\left(\left\|\mathbf{W}_{1}\right\|_{2}^{2}+\left\|\mathbf{W}_{2}\right\|_{2}^{2}+\left\|\mathbf{Q}_{h}\right\|_{2}^{2}+\|\mathbf{r}\|_{2}^{2}\right.\\ &+\left\|\mathbf{U}_{z}\right\|_{2}^{2}+\left\|\mathbf{W}_{z}\right\|_{2}^{2}+\left\|\mathbf{b}_{z}\right\|_{2}^{2}+\left\|\mathbf{U}_{r}\right\|_{2}^{2}+\left\|\mathbf{W}_{r}\right\|_{2}^{2} \\ &\left.+\left\|\mathbf{b}_{r}\right\|_{2}^{2}+\left\|\mathbf{U}_{c}\right\|_{2}^{2}+\left\|\mathbf{W}_{c}\right\|_{2}^{2}+\|\mathbf{a}\|_{2}^{2}+\|\mathbf{b}\|_{2}^{2}\right) \end{aligned} Lreg=∑(∥W1∥22+∥W2∥22+∥Qh∥22+∥r∥22+∥Uz∥22+∥Wz∥22+∥bz∥22+∥Ur∥22+∥Wr∥22+∥br∥22+∥Uc∥22+∥Wc∥22+∥a∥22+∥b∥22)
综上训练的loss 为:
L = L t + λ L r e g \mathcal{L}=\mathcal{L}^{t}+\lambda \mathcal{L}_{r e g} L=Lt+λLreg
整体算法伪代码如下:

Experiments
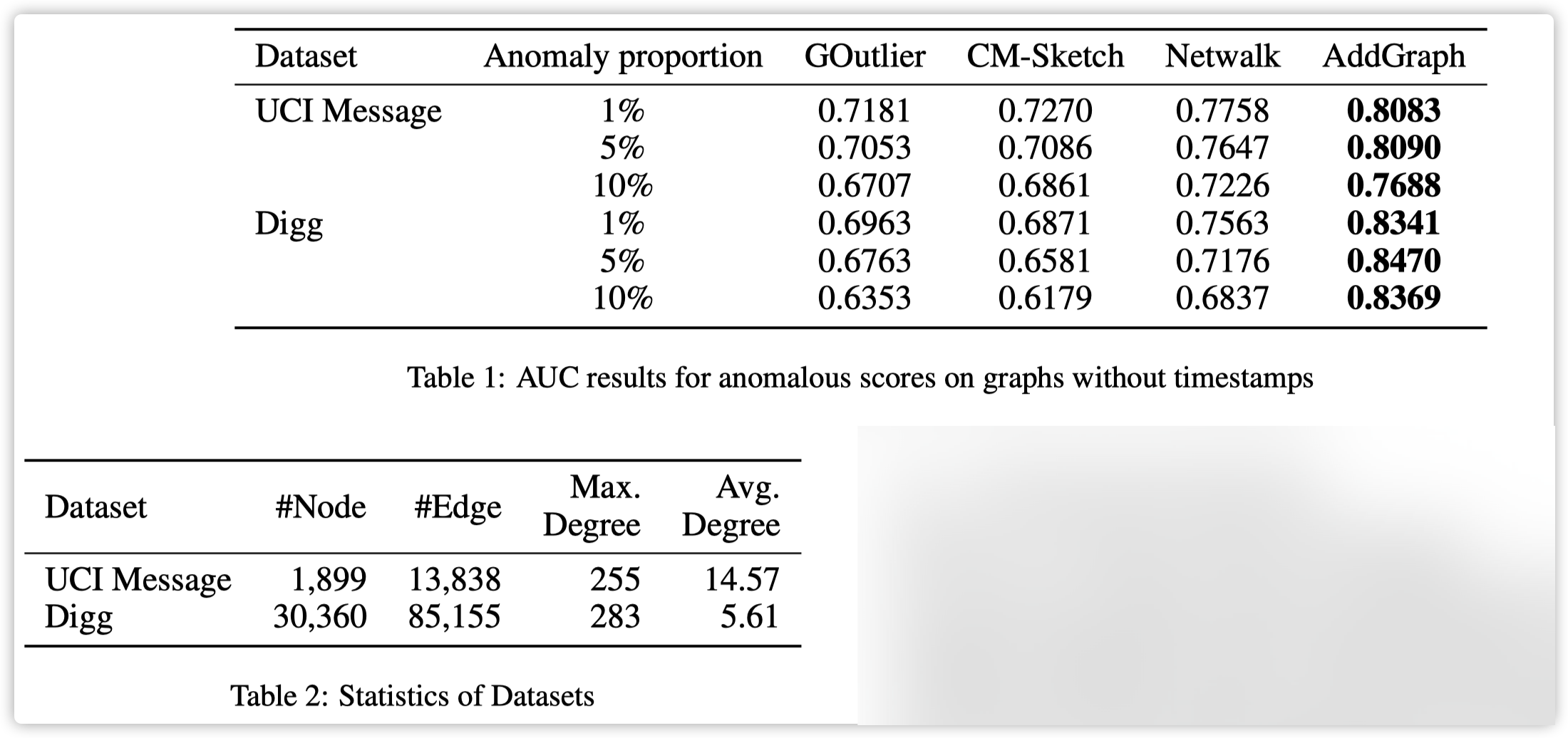














 4493
4493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









