






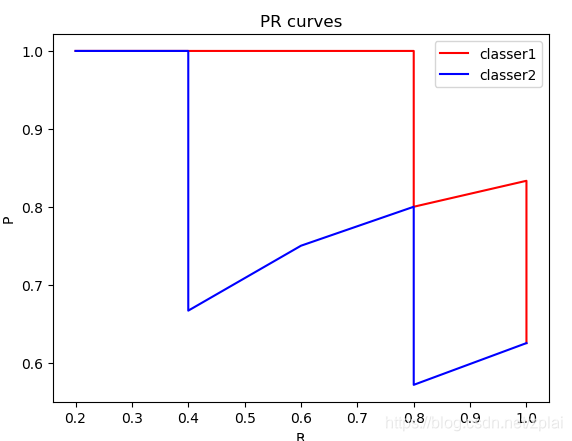
1. 请画出以下两个分类器分类 PR 曲线

- 对分类器1按P(+/X)P(+/X)从大到小排序:
| + | + | + | + | - | + | - | - | |
|---|---|---|---|---|---|---|---|---|
| P | 1/1 | 2/2 | 3/3 | 4/4 | 4/5 | 5/6 | 5/7 | 5/8 |
| R | 1/5 | 2/5 | 3/5 | 4/5 | 4/5 | 5/5 | 5/5 | 5/5 |
- 对分类器2按P(+/X)P(+/X)从大到小排序(r若相等则按原顺序):
| + | + | - | + | + | - | - | + | |
|---|---|---|---|---|---|---|---|---|
| P | 1/1 | 2/2 | 2/3 | 3/4 | 4/5 | 4/6 | 4/7 | 5/8 |
| R | 1/5 | 2/5 | 2/5 | 3/5 | 4/5 | 4/5 | 4/5 | 5/5 |
PR曲线如下:















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









