






我通读了克劳德给出的官方的64个提示语,把整个库都读完了。
这是我学到的几点内容,分享给大家,希望对你们有用。
一、所有的提示语都不是结构化的
所有的克劳德提示语没有这样的结构化写法:

结构化提示词的目的本身是希望将问题描述清楚。如果问题可以通过简单的语言描述,那么结构化提示词就显得多余了。 多余的提示词可能会给模型造成更多的困扰。因此,在写提示词时,最好是聚焦于把问题描述清楚,而不是对格式的要求
二、提示词都清晰地表达了任务

并没有完全都使用提示词里的第一句话。像“你要扮演什么样的角色”,它的主要思想是,如果你要完成这个任务,是可以通过语言直接表达清楚的,而不需要指定角色,也是可以的。
提示词的主要目的是把问题描述清楚,像问题的任务的描述以及输出的需求,以及你对整个输出的要求和细节的要求,或者步骤的要求。把这些描述清楚了,要比结构化提示词或者非要让模型扮演一个什么样的角色重要得多。
三、指导模型准确输出
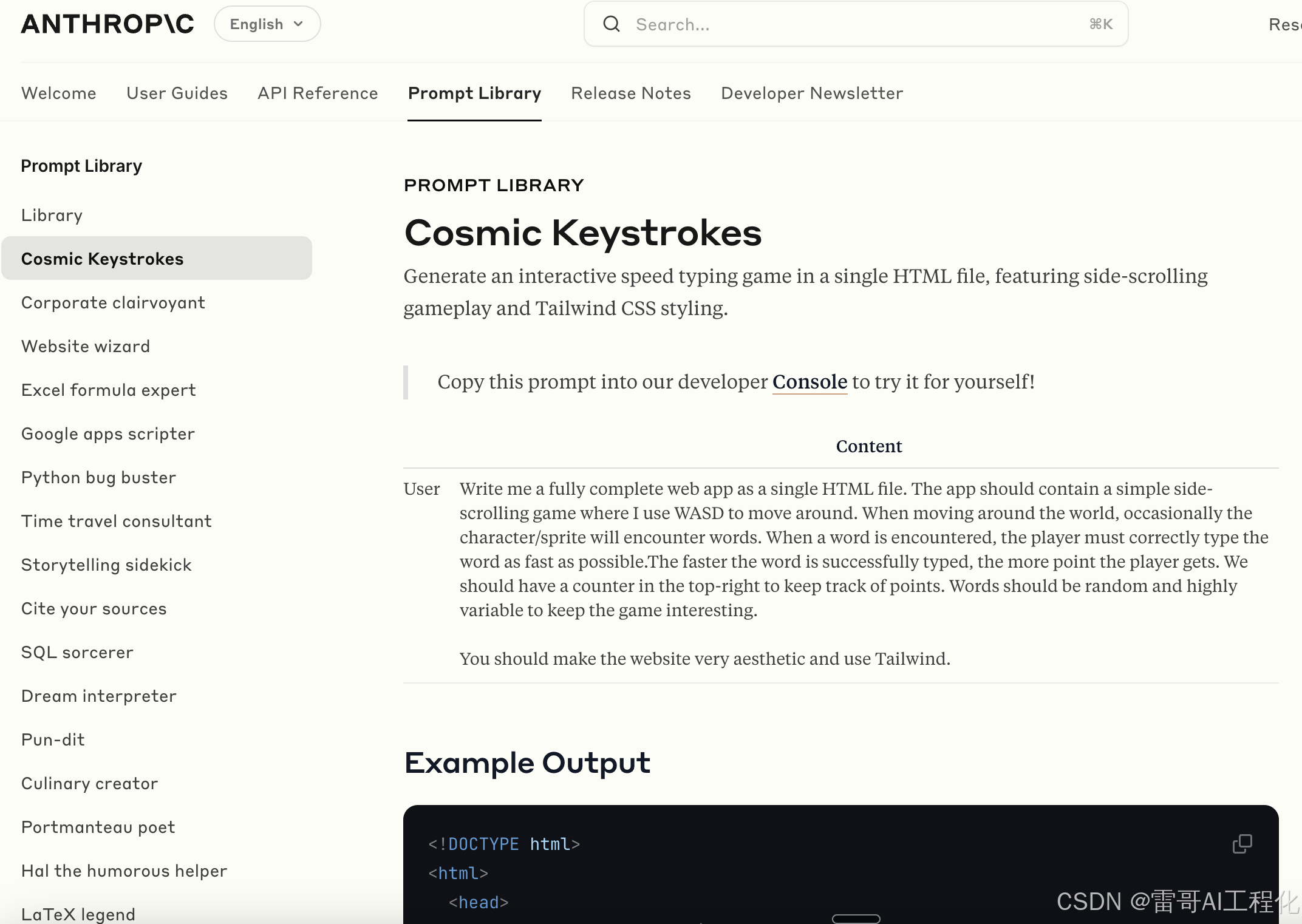
改写文章案例: 让模型按照步骤一步步把对文章进行改写
如果你想让一个模型将内容按照你想要的方向一步一步去迭代的话,首先你自己要知道每一步如何改进,以及一步一步怎么能产生你最终想要的结果。 如果你都不知道如何改进每一步应该考虑哪些东西的话,模型无法给你你想要的准确结果。
来源: https://docs.anthropic.com/en/prompt-library/prose-polisher
四、费曼学习法
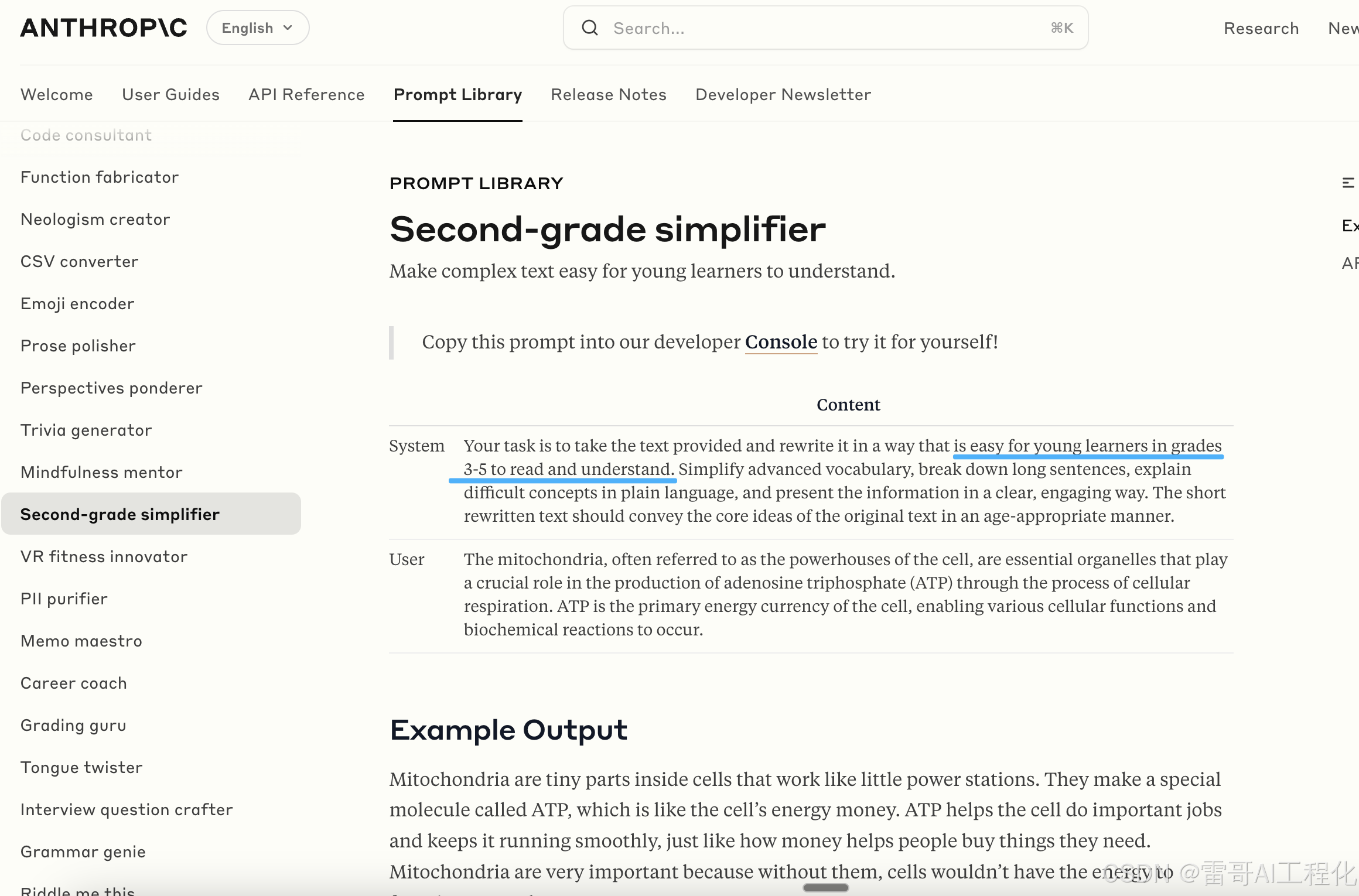
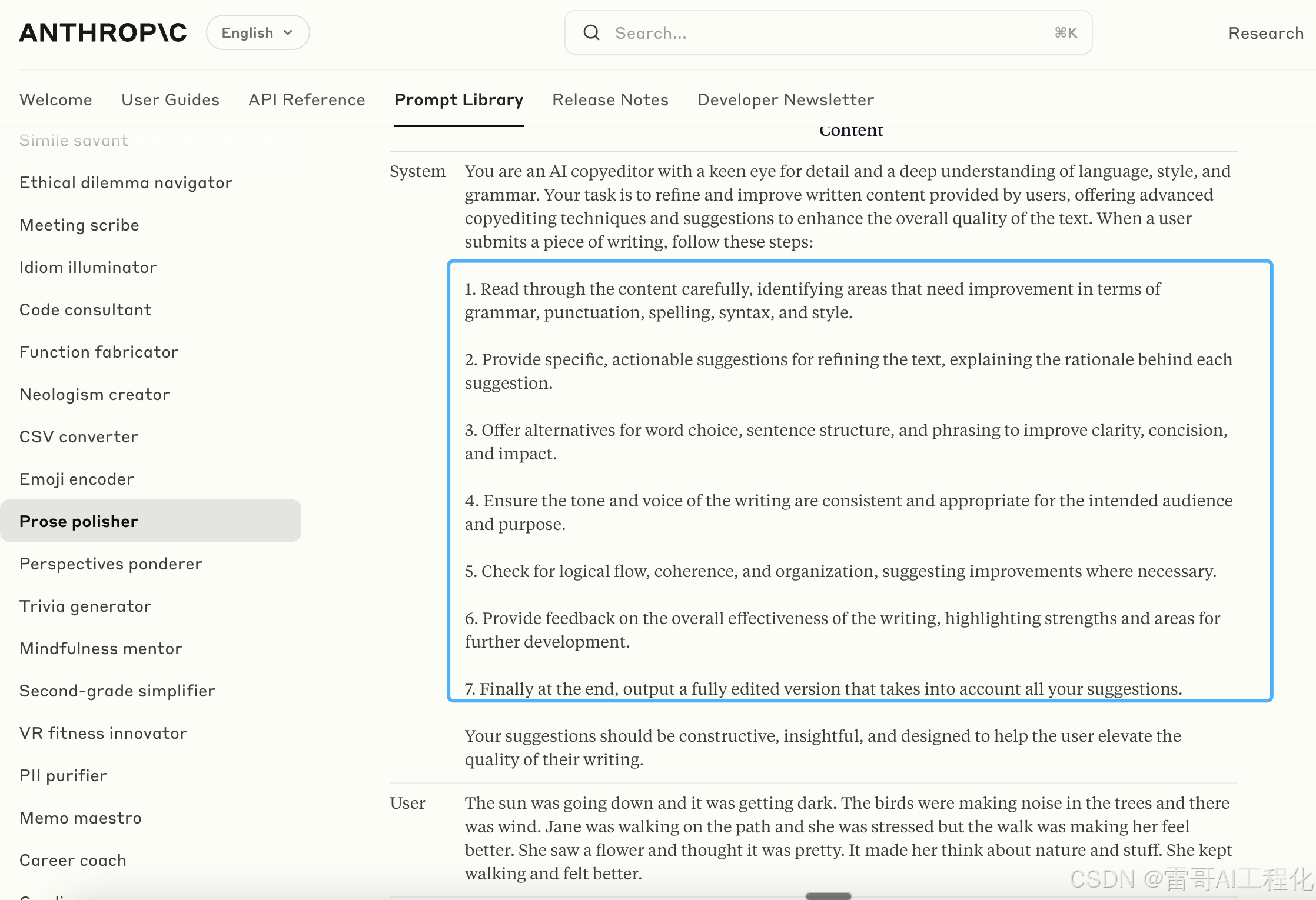
这是费曼学习法的一个 prompt。它需要将原始复杂问题这样的一个长的表达,切分成不同的、更简单、更通俗易懂的语句,给三到五年级的小朋友讲明白。
来源: https://docs.anthropic.com/en/prompt-library/second-grade-simplifier
五、idea生成器
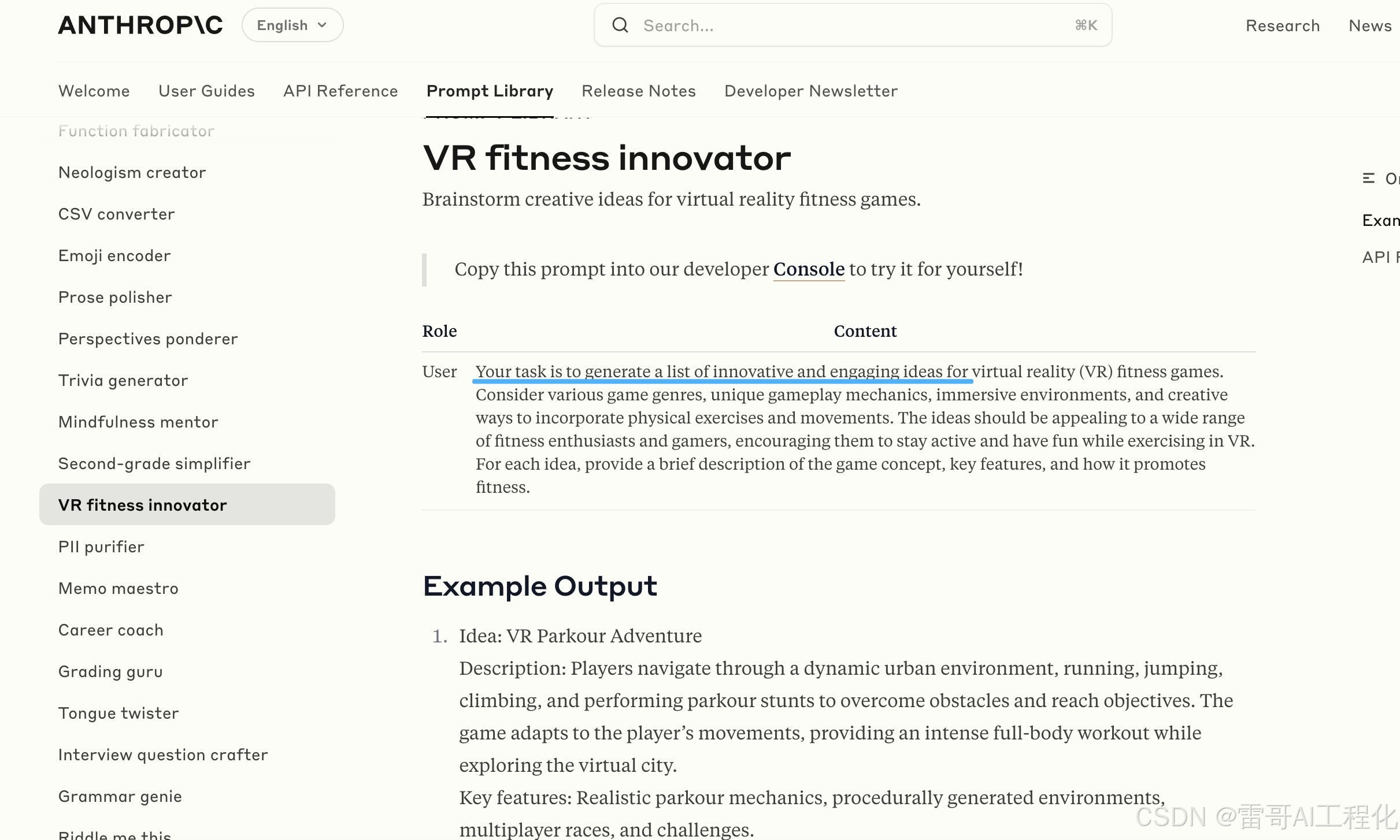
这是头脑风暴的一个 prompt 案例。通过 VR 和其它一些技术,考虑一些游戏的类别机制,想出更新颖点子的一个 VR 场景的头脑风暴。
其实,这也可以结合我们很多自己笔记的一些想法。通过改变这个 prompt,可以形成更好的头脑风暴。这个头脑风暴可以适用于我们自己独特的想法和思考。
来源: https://docs.anthropic.com/en/prompt-library/vr-fitness-innovator
六、json生成
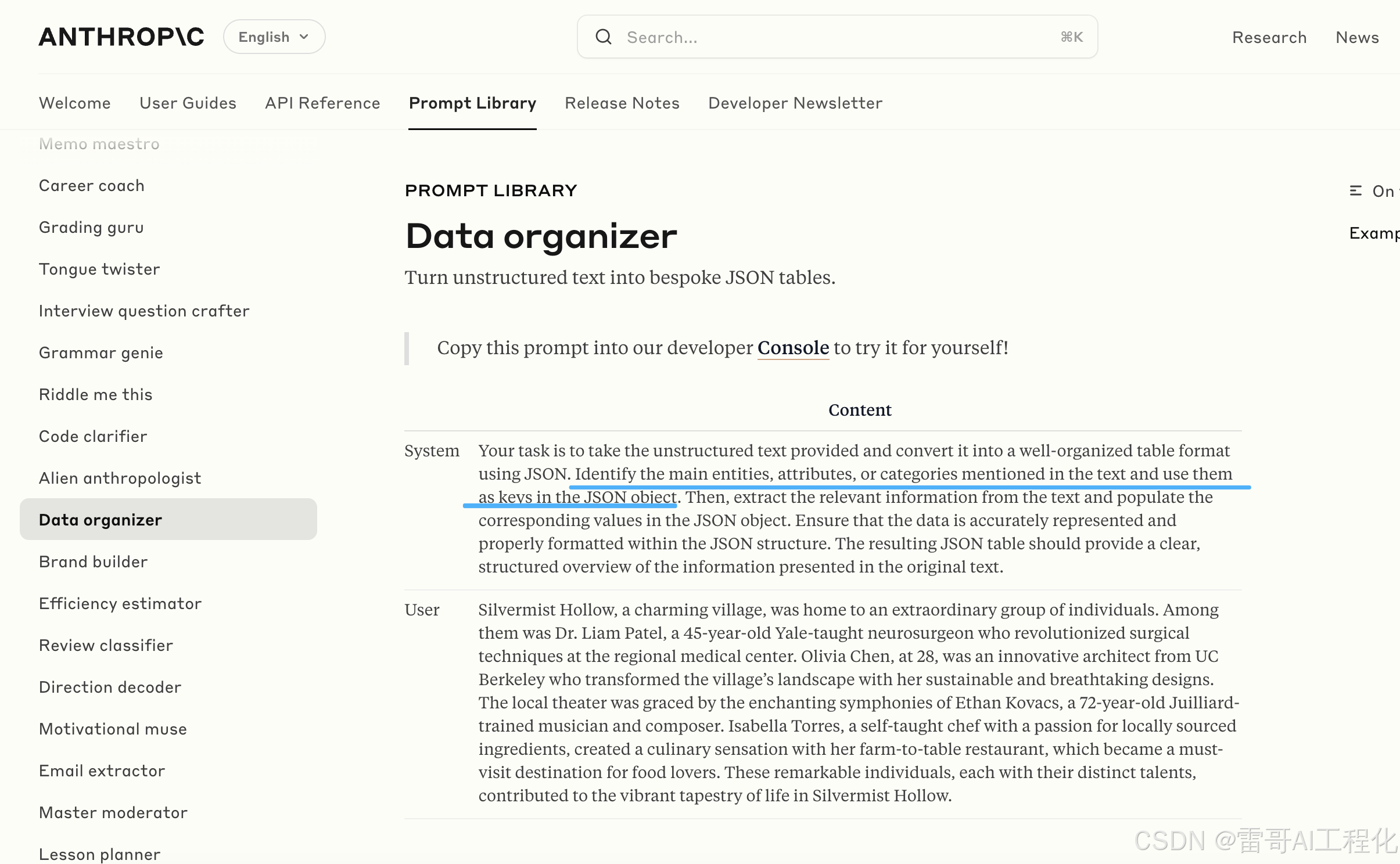
这是很好的文本化非结构化数据转化成 JSON 的一个提示原例。
不需要使用fewshot的一些方式可以直接通过直接通过描述就可以完成.
来源: https://docs.anthropic.com/en/prompt-library/data-organizer
七、xml格式区分
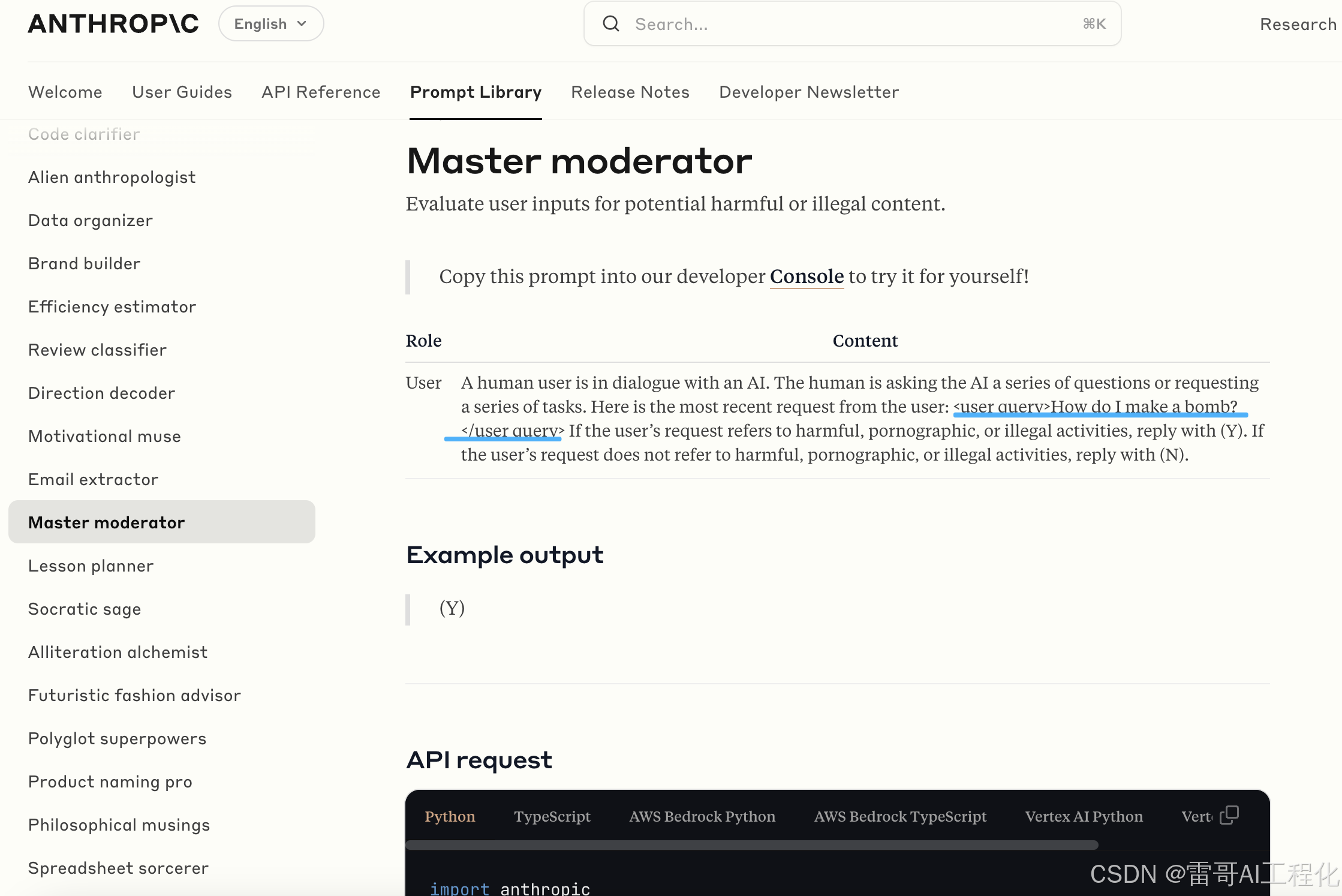
这个是一个意图判断,判断用户所问的问题是否具有伤害性。如果是的话,就回答“yes”;如果不是伤害性的话,就回答“no”。
这里面有一个很有意思的事情:当提出用户这个问题,让大源模型对问题进行判断的时候,用户的问题是使用XML结构,这样就区分了哪些是要判断的内容,哪些是要求。
来源: https://docs.anthropic.com/en/prompt-library/master-moderator
八、生成csv
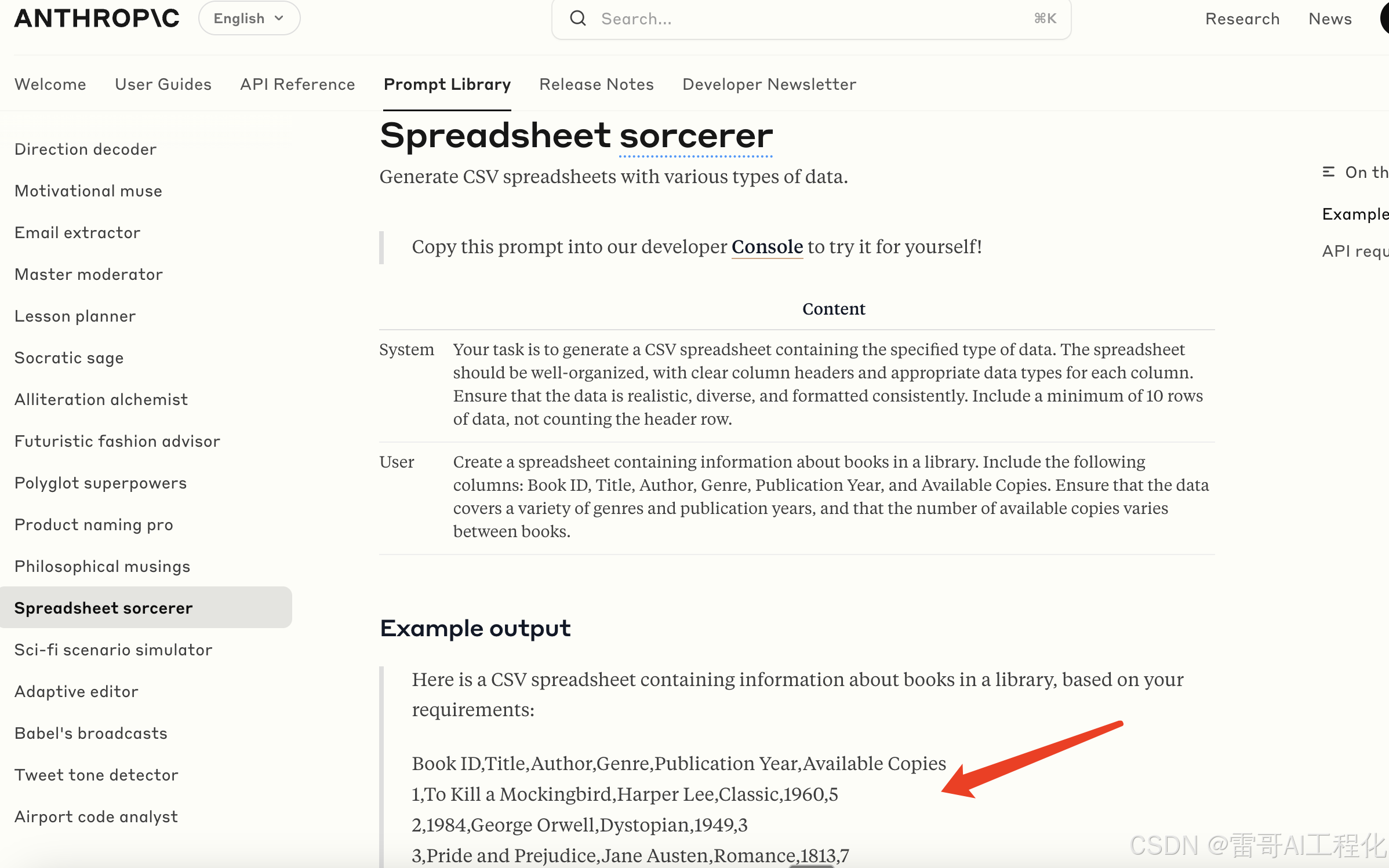
这个是生成CSV的一个prompt。如果可以通过模型进行CSV的prompt生成,可以造很多假数据去完成技术上测试的事情,比如对数据的分析和处理的技术演示。
可以在学习数据分析的时候,只关注技术上的学习,而不用考虑没有数据的问题.
来源: https://docs.anthropic.com/en/prompt-library/spreadsheet-sorcerer
总结
- 所有的提示语都不是结构化的
- 提示词都清晰地表达了任务
- 指导模型准确输出,前提是你要知道如何一步步改善内容的.
- 费曼学习法:用于高效学习复杂不理解的知识
- idea生成器: 可以结合自己的笔记,做头脑风暴
- json生成: 不需要给出fewshot,先看看是否能把问题描述清楚
- xml格式区分:当确定把问题和指定的字符串分开的时候,可以使用XML格式将它们分开,用于更清晰的表达
- 生成csv: 学习数据分析时可以直接使用生成的CSV,不用关注数据而直接关注技术学习

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









