







1. 内存对界原理
在C语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。在结构中,编译器为结构的每个成员按其自然对界(alignment)条件分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
例如:
struct struct1
{
char x1; // 对界条件为1,不填充,偏移地址为0
short x2; // 对界条件为2,前面填充一个字节,偏移地址为2
double x3; // 对界条件为4,不填充,偏移地址为4 char x4; // 对界条件为1,不填充,偏移地址为8
short x5; // 对界条件为2,前面填充一个字节,偏移地址为10
};
struct1 st1; cout << &st1 << endl; // 输出:0012FF54
void* p = &st1.x1;
cout << p << endl;// 输出:0012FF54
cout << &st1.x2 << endl;// 输出:0012FF56
cout << &st1.x3 << endl;// 输出:0012FF5C
p = &st1.x4;
cout << p << endl;// 输出:0012FF64
cout << &st1.x5 << endl;// 输出:0012FF66
cout << sizeof(struct1) << endl;// 输出:12其内存分布如右图所示:
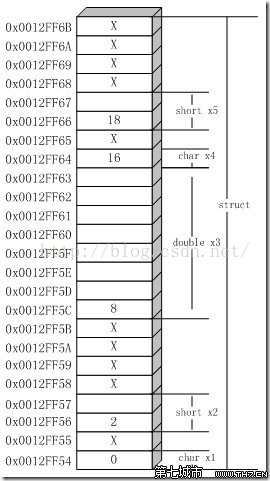
x1为结构体的第一个成员,其地址和整个结构的地址相同,因而其偏移地址为0。
x2为short类型,其大小为2,因而其自然对界也为2,所以其偏移地址必须为2的整数倍,所以编译器在x2和x1之间添充了1个空字节。这样,x2的偏移地址为2。
x3为double类型,其大小为8,因而其自然对界也为8,所以其偏移地址必须是8的整数倍,所以编译器在x3和x2之间添充了4个空字节。这样,x3的偏移地址为8。
同理,可以算出x4的偏移地址为16,紧跟着x3存储。x5的偏移地址为18。
最后,由于x3要求8字节对界,是该结构所有成员中要求的最大对界单元,因而整个结构struct1的自然对界条件为8字节(注意不是该结构的总大小),所以该结构的大小必须满足8的整数倍,这就要求在x5之后还要再添充4个字节,使整个结构体的大小为24字节。
通过上面的分析可得到如下结论:
对于基本数据类型(如int、long、float等。注意,还包括指针),其自然对界条件为该类型所占用存储空间的大小,指针点用4个字节的空间;
对于复合数据类型(如数组、结构、联合等),其自然对界条件为该数据类型的所有成员中要求的最大对界单元。
有了上面的分析,就不难明白下面的例子,包含了同样数据类型的结构体,其占用内存空间的差距咋就这么大呢!
struct struct1
{
char c1;
char c2;
double d;
};
struct struct2
{
char c1;
double d;
char c2;
};
cout << sizeof(struct1) << endl; // 输出:16
cout << sizeof(struct2) << endl; // 输出:24想到了什么?原来优化结构体内变量类型的存储顺序,可以减少对内存的占用!
2. 更改C编译器的缺省字节对齐方式
在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
1>使用伪指令#pragma pack (n),C编译器将按照n个字节对齐。
2>使用伪指令#pragma pack (),取消自定义字节对齐方式。
另外,还有如下的一种方式:
__attribute((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
__attribute__ ((packed)),取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
以上的n = 1, 2, 4, 8, 16... 第一种方式较为常见。
3. 加深理解
为了加深对内存对齐的理解,再看下面的例子:处理结构体时要小心!!!
#pragma pack(8)
struct s0
{
short s;
};
struct s1
{
short a;
long b;
};
struct s2
{
char c;
s1 d;
long long e;
};
#pragma pack()cout << sizeof(s0) << endl; // 输出:2
cout << sizeof(s1) << endl; // 输出:8
cout << sizeof(s2) << endl; // 输出:24
问:sizeof(s2) = ? s2的c后面空了几个字节接着是d?
分析:成员对齐有一个重要的条件,即每个成员分别对齐,每个成员按自己的方式对齐。
也就是说上面虽然指定了按8字节对齐,但并不是所有的成员都是以8字节对齐。其对齐的规则是,每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数(这里是8字节)中较小的一个对齐。并且结构的长度必须为所用过的所有对齐参数的整数倍。不够就补空字节。
s1中,成员a是2字节默认按2字节对齐,指定对齐参数为8,这两个值中取2,a按2字节对齐;成员b是4个字节,默认是按4字节对齐,这时就按4字节对齐,所以sizeof(s1)应该为8。
s2 中,c和s1中的a一样,按2字节对齐,而d 是个结构,它是8个字节,它按什么对齐呢?对于结构来说,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,s1的就是4。所以,成员d就是按4字节对齐。成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它应对到8字节的边界上,这时,已经使用了12个字节了,所以又添加了4个字节的空,从第16个字节开始放置成员e。这时,长度为24,已经可以被8(成员e按8字节对齐)整除。这样,一共使用了24个字节。
s1的内存布局:
| a |
| b | |||||
| 1 | 1 | x | x | 1 | 1 | 1 | 1 |
s2的内存布局:
| c |
| d |
| e | |||||||||||||||||||
| 1 | x | x | x | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | x | x | x | x | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
这里有三点很重要:
1. 每个成员分别按自己的方式对齐,并能最小化长度;
2. 复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度;
3. 对齐后的长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐;
4. 数组的对齐方式
对于数组,对齐方式为元素的对齐方式。
比如:char a[3];这种,它的对齐方式和分别写3个char是一样的,也就是说它还是按1个字节对齐.如果写: typedef char Array3[3]; Array3这种类型的对齐方式还是按1个字节对齐,而不是按它的长度。
不论类型是什么,对齐的边界一定是1,2,4,8,16,32,64....中的一个。
struct s1
{
char a[8];
};
struct s2
{
double d;
};
struct s3
{
s1 s;
char a;
};
struct s4
{
s2 s;
char a;
};cout << sizeof(s2) << endl; // 输出:8
cout << sizeof(s3) << endl; // 输出:9
cout << sizeof(s4) << endl; // 输出:16;
s1和s2大小虽然都是8,但是s1的对齐方式是1,s2的对齐方式是8(double),所以在s3和s4中才有这样的差异。所以,在自己定义结构体的时候,如果空间紧张的话,最好考虑对齐因素来排列结构体里的元素。
5. union的对齐方式
union的对齐方式:为成员中最大的对齐方式,长度为按照这个对齐方式调整最长成员得到的长度。
union u1
{
double a;
int b;
};
union u2
{
char a[13];
int b;
};
union u3
{
char a[13];
char b;
};
cout << sizeof(u1) << endl; // 输出:8
cout << sizeof(u2) << endl; // 输出:16(特别注意!)
cout << sizeof(u3) << endl; // 输出:13
都知道union的大小取决于它所有的成员中,占用空间最大的一个成员的大小。所以对于u1来说,大小就是最大的double类型成员a了,所以 sizeof(u1)=sizeof(double)=8。
但是对于u2和u3,最大的空间都是char[13]类型的数组,为什么u3的大小是13,而 u2是16呢?关键在于u2中的成员int b。由于int类型成员的存在,使u2的对齐方式变成4,也就是说,u2的大小必须在4的对界上,所以占用的空间变成了16(最接近13的对界)。
所以:复合数据类型,如union,struct,class的对齐方式为成员中对齐方式最大的成员的对齐方式。
对界是可以更改的,使用#pragmapack(x)宏可以改变编译器的对界方式,默认是8。C++固有类型的对界取编译器对界方式与自身大小中较小的一个。例如,指定编译器按2对界,int类型的大小是4,则int的对界为2和4中较小的2。在默认的对界方式下,因为几乎所有的数据类型都不大于默认的对界方式8(除了 longdouble),所以所有的固有类型的对界方式可以认为就是类型自身的大小。更改一下上面的程序:
#pragma pack(2)
union u2
{
char a[13];
int b;
};
union u3
{
char a[13];
char b;
};
#pragma pack(8)
cout << sizeof(u2) << endl; // 输出:14
cout << sizeof(u3) << endl; // 输出:13
由于手动更改对界方式为2,所以int的对界也变成了2,u2的对界取成员中最大的对界,也是2了,所以此时sizeof(u2)=14。
所以:C++固有类型的对界取编译器对界方式与自身大小中较小的一个。















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









