



要使用 OpenAI Search 功能,完整的实现流程包括:
-
准备环境:
- 注册 OpenAI 账户并获取 API 密钥。
- 安装所需的 Python 库。
-
实现流程:
- 使用 OpenAI 的 Embedding 模型生成语义嵌入向量。
- 将文档的嵌入存储到向量数据库中(可选)。
- 根据用户查询生成查询向量,并与存储的文档向量进行相似性计算。
以下是完整的 Python 实现步骤:
1. 环境准备
安装库: pip install openai pandas numpy
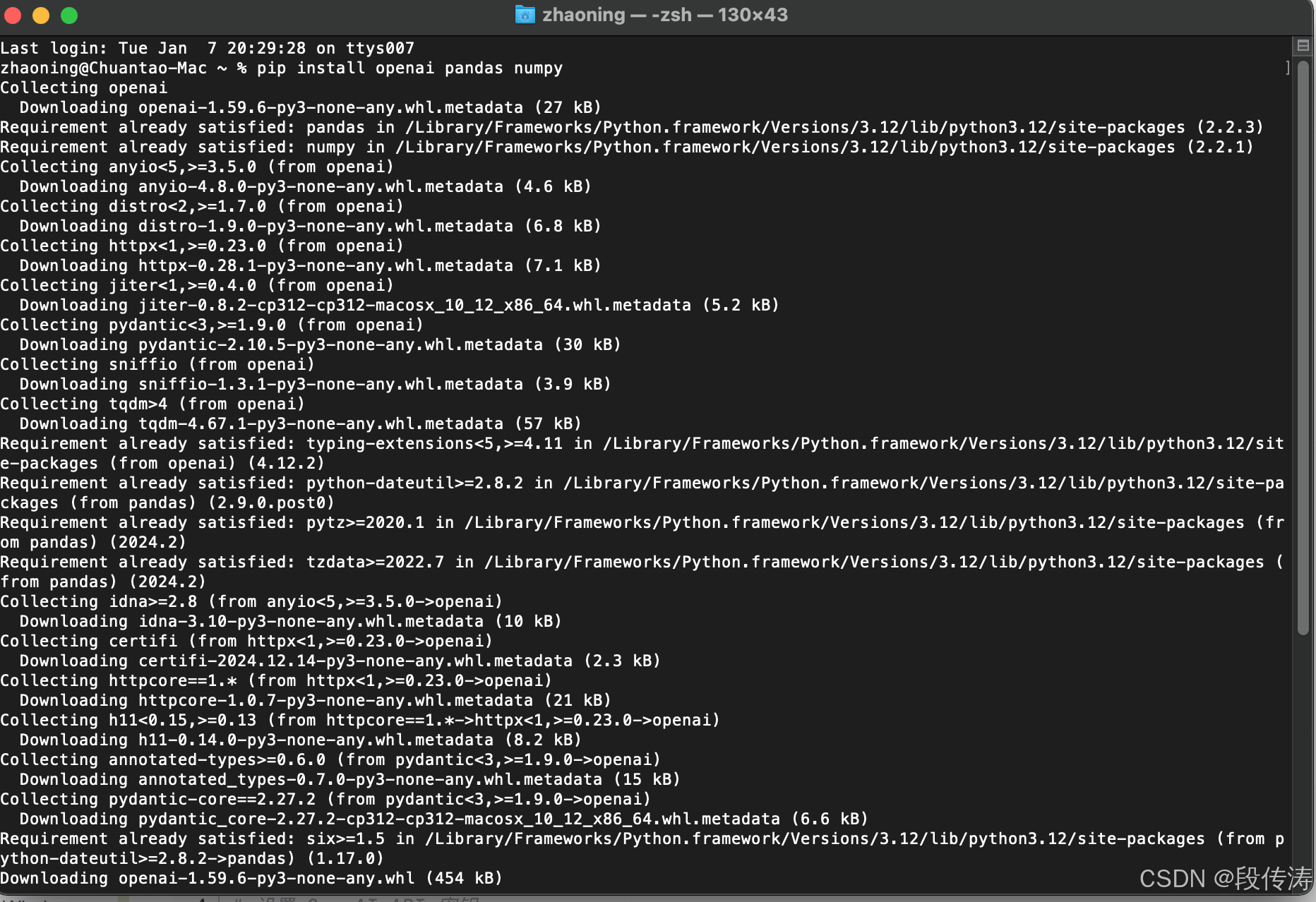
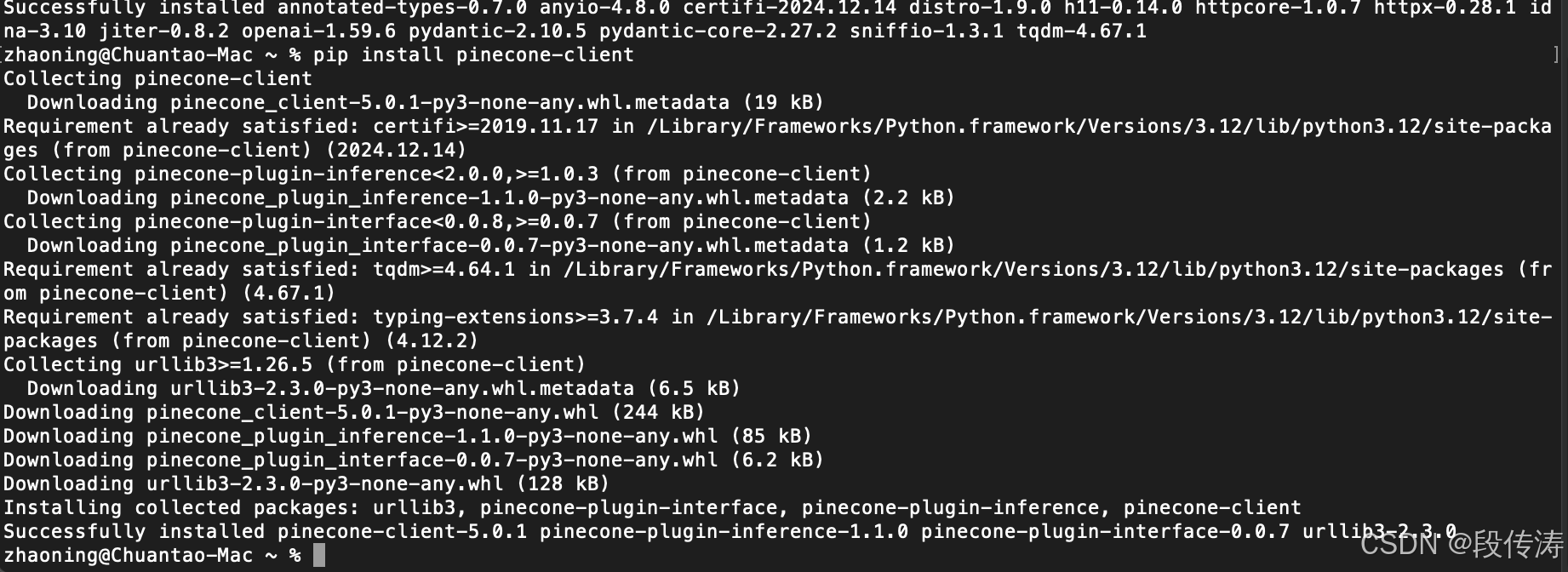
可以安装向量数据库库,例如 pinecone 或 weaviate: pip install pinecone-client
2. 生成语义嵌入并进行搜索
示例代码:直接搜索文档 Python
import openai
import numpy as np
# 设置 OpenAI API 密钥
openai.api_key = "your-api-key"
# 文档集合
documents = [
"Artificial intelligence improves medical diagnostics.",
"Self-driving cars rely on machine learning algorithms.",
"Natural language processing powers chatbots and assistants.",
"Renewable energy is crucial for combating climate change.",
"Blockchain is transforming the finance industry."
]
# Step 1: 为文档生成嵌入向量
doc_embeddings = []
for doc in documents:
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=doc
)
doc_embeddings.append(response["data"][0]["embedding"])
# Step 2: 查询语句
query = "How does AI help in healthcare?"
query_embedding = openai.Embedding.create(
model="text-embedding-ada-002",
input=query
)["data"][0]["embedding"]
# Step 3: 计算相似度(余弦相似度)
def cosine_similarity(vec1, vec2):
vec1 = np.array(vec1)
vec2 = np.array(vec2)
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# 计算查询与每个文档的相似度
similarities = [cosine_similarity(query_embedding, doc_emb) for doc_emb in doc_embeddings]
# 输出排序后的结果
sorted_results = sorted(zip(documents, similarities), key=lambda x: x[1], reverse=True)
for doc, score in sorted_results:
print(f"Document: {doc}\nSimilarity: {score:.4f}\n")
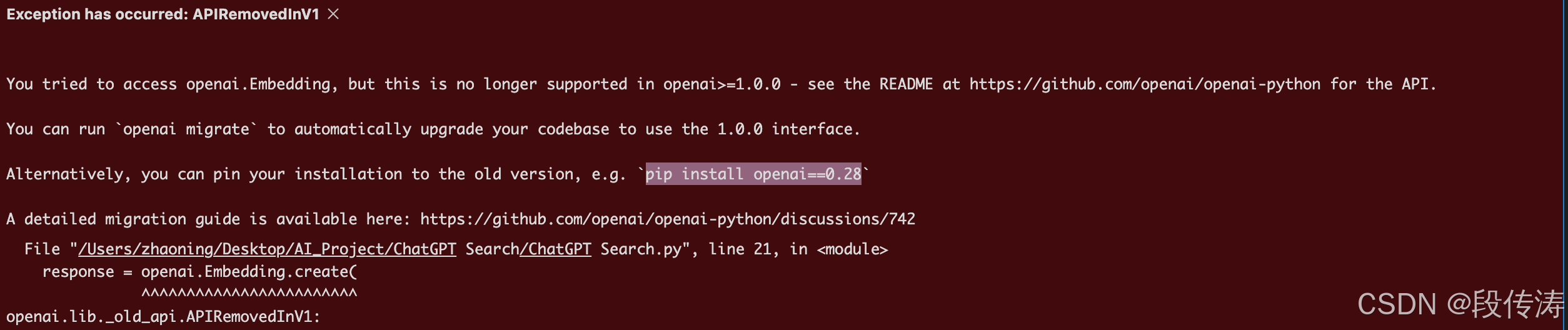
Notice, 在执行的过程中,如发现如下错误,请更新你的OpenAI 版本。
3. 使用向量数据库
如果需要存储和检索大量文档,建议使用向量数据库,如 Pinecone。
示例代码:存储到 Pinecone Python
import pinecone
# 初始化 Pinecone
pinecone.init(api_key="your-pinecone-api-key", environment="us-west1-gcp")
index_name = "document-search"
# 创建或连接到 Pinecone 索引
if index_name not in pinecone.list_indexes():
pinecone.create_index(index_name, dimension=1536) # 1536 是 text-embedding-ada-002 的向量维度
index = pinecone.Index(index_name)
# 将文档嵌入上传到 Pinecone
for i, doc in enumerate(documents):
doc_embedding = openai.Embedding.create(
model="text-embedding-ada-002",
input=doc
)["data"][0]["embedding"]
index.upsert([(str(i), doc_embedding)])
# 查询
query_embedding = openai.Embedding.create(
model="text-embedding-ada-002",
input=query
)["data"][0]["embedding"]
# 从 Pinecone 搜索最相似的文档
results = index.query(vector=query_embedding, top_k=3, include_metadata=False)
for match in results["matches"]:
doc_id = int(match["id"])
score = match["score"]
print(f"Document: {documents[doc_id]}\nSimilarity: {score:.4f}\n")
4. 常见问题处理
- API 配额问题:
- OpenAI 的嵌入生成按调用次数计费,检查并优化调用频率。
- 向量存储问题:
- 如果没有向量数据库,也可以用本地文件(如 CSV 或 JSON)存储嵌入向量。
5. 完整代码结构
以下是一个简单完整的结构:Python
import openai
import numpy as np
import pinecone # 可选
openai.api_key = "your-api-key"
# 文档集合
documents = [
"Artificial intelligence improves medical diagnostics.",
"Self-driving cars rely on machine learning algorithms.",
"Natural language processing powers chatbots and assistants.",
]
# 生成文档嵌入
doc_embeddings = [openai.Embedding.create(model="text-embedding-ada-002", input=doc)["data"][0]["embedding"] for doc in documents]
# 查询
query = "How does AI help in healthcare?"
query_embedding = openai.Embedding.create(model="text-embedding-ada-002", input=query)["data"][0]["embedding"]
# 计算相似度
def cosine_similarity(vec1, vec2):
vec1, vec2 = np.array(vec1), np.array(vec2)
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# 排序结果
similarities = [cosine_similarity(query_embedding, doc_emb) for doc_emb in doc_embeddings]
sorted_results = sorted(zip(documents, similarities), key=lambda x: x[1], reverse=True)
# 输出结果
for doc, score in sorted_results:
print(f"Document: {doc}\nSimilarity: {score:.4f}\n")
说明和步骤
- 使用 OpenAI 的
text-embedding-ada-002模型生成嵌入向量。 - 使用余弦相似度计算查询和文档的语义相关性。
- 可通过向量数据库(如 Pinecone)存储和管理大规模嵌入向量。
- 确保 API 调用频率和成本控制。

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









