






 本文详细介绍了使用Python进行网站爬取的步骤,包括检查robots.txt、测试请求、设置请求头、处理响应数据(如HTML解析)以及数据筛选。作者还提供了实例代码,展示了如何抓取并整理网页中的链接和标题信息。
本文详细介绍了使用Python进行网站爬取的步骤,包括检查robots.txt、测试请求、设置请求头、处理响应数据(如HTML解析)以及数据筛选。作者还提供了实例代码,展示了如何抓取并整理网页中的链接和标题信息。
一般步骤:确定网站–搭建关系–发送请求–接受响应–筛选数据–保存本地
1.拿到网站首先要查看我们要爬取的目录是否被允许
一般网站都会议/robots.txt目录,告诉你哪些地址可爬,哪些不可爬,以安全客为例子
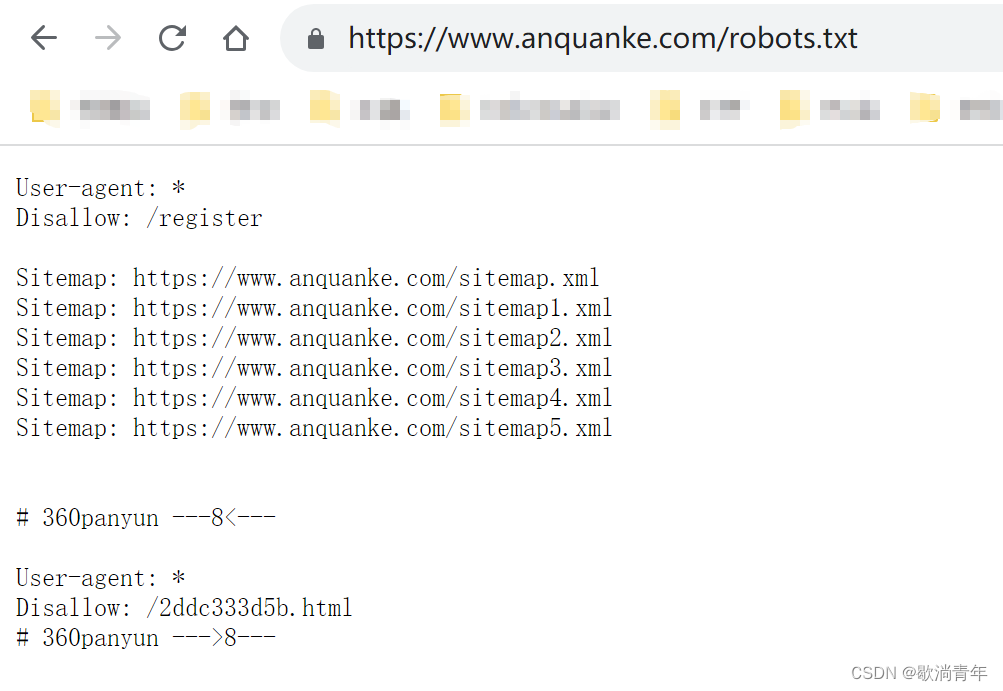
2. 首先测试在不登录的情况下是否请求成功
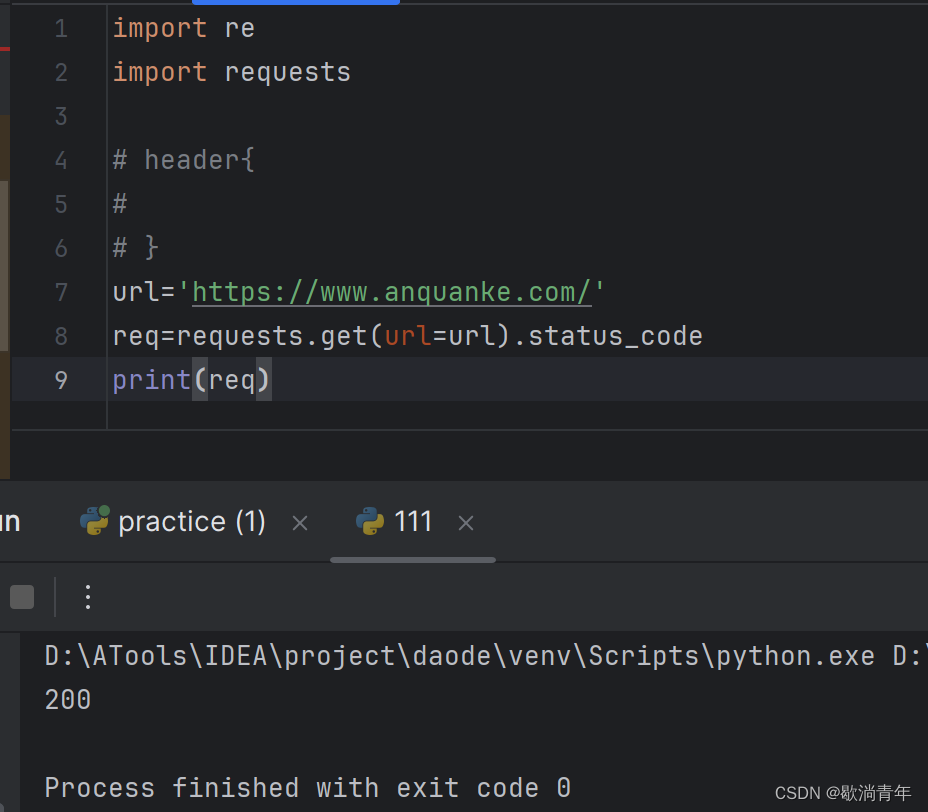
可见,该请求成功;有很多网站在没有登录的情况下是请求失败的,这时需要添加请求头信息,
注意:有的cookie 会根据时间戳生成,有的会失效
haders={},
2.1、首先 F12 到 Network 下,F5刷新 ,复制 Requests Headers然后把它转换成 json 格式
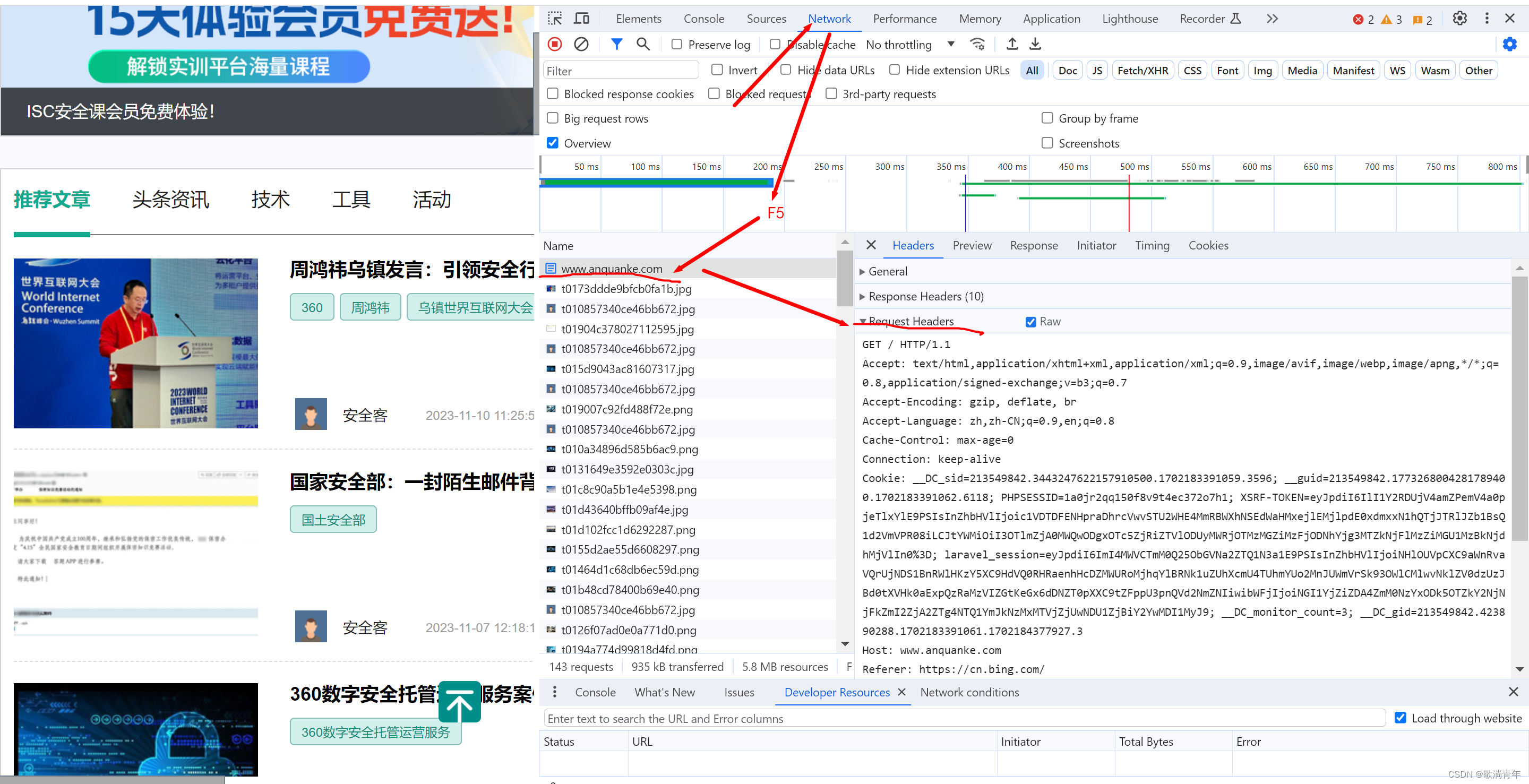
2.1.1 Requests Headers 转 json 格式有很多种方法
1. 在线转 json 格式的网站:在线HTTP请求/响应头转JSON工具 -
UU在线工具
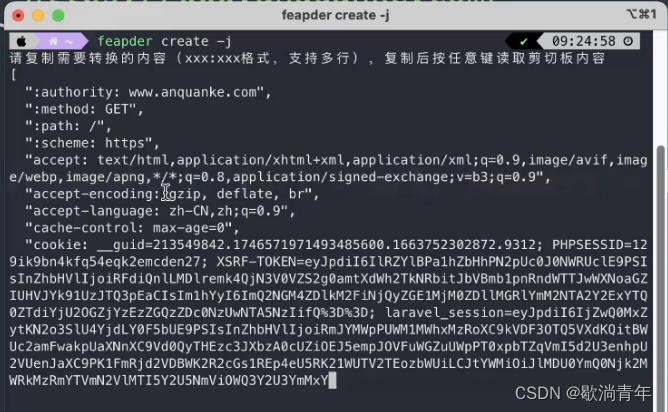
2.如果电脑没网 在终端下载:pip install feapder
feapder create -j
req=requests.get(url=url).text 是把所有的文本都提取出来,会很乱,所有我们需要筛选,整理一下
可以发现,我们需要的数据在 a 标签中
数据多了id位数也可能会增加;也可以把id写死,根据291754是个六位数,所以 \d{6}只匹配 id是六位数的。
Title=re.findall(r'<a target="_blank" href="/post/id/\d+">(.*?)</a>',req)
\d+
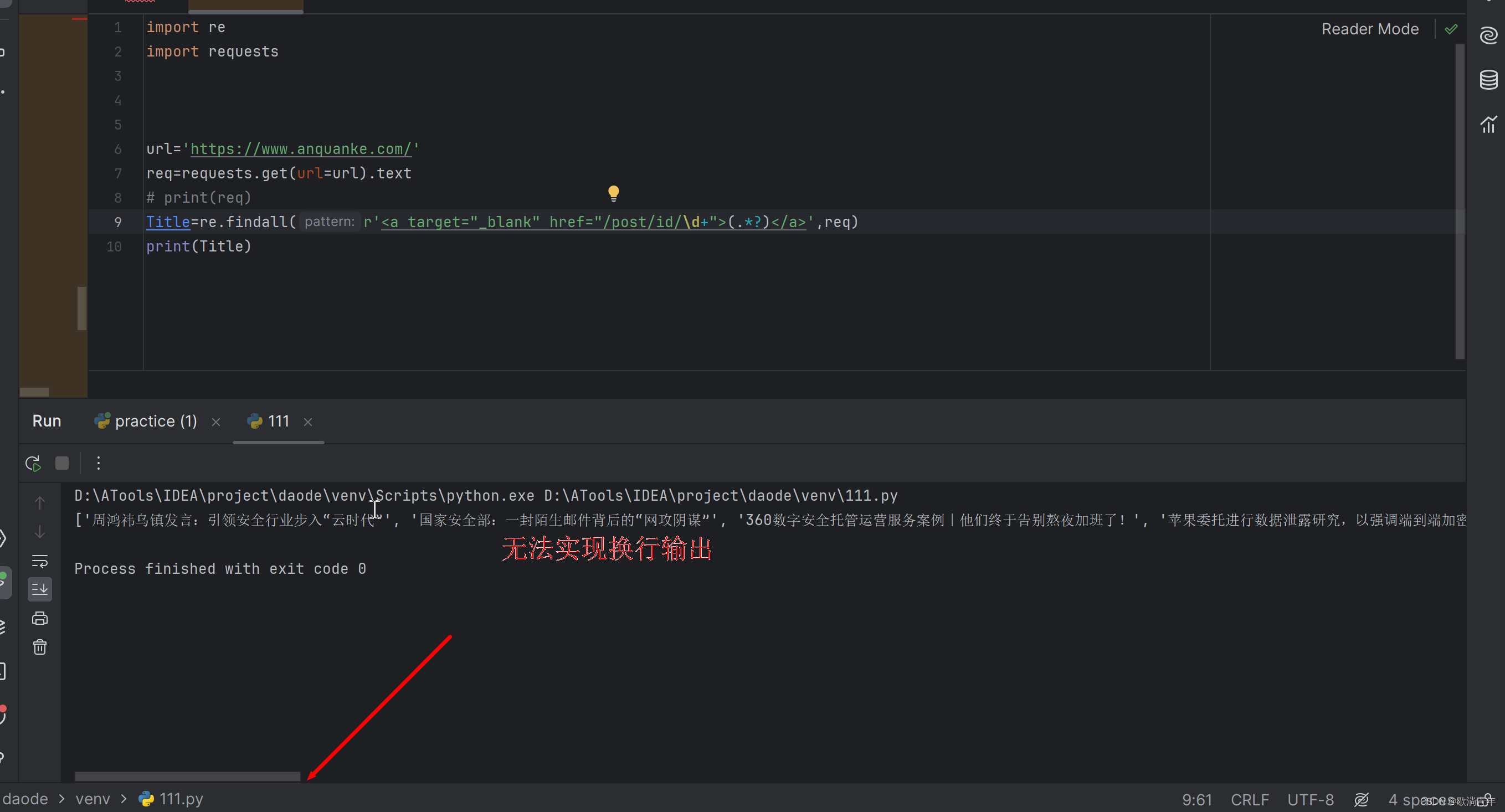
注意代码格式
range() 取值 [ )
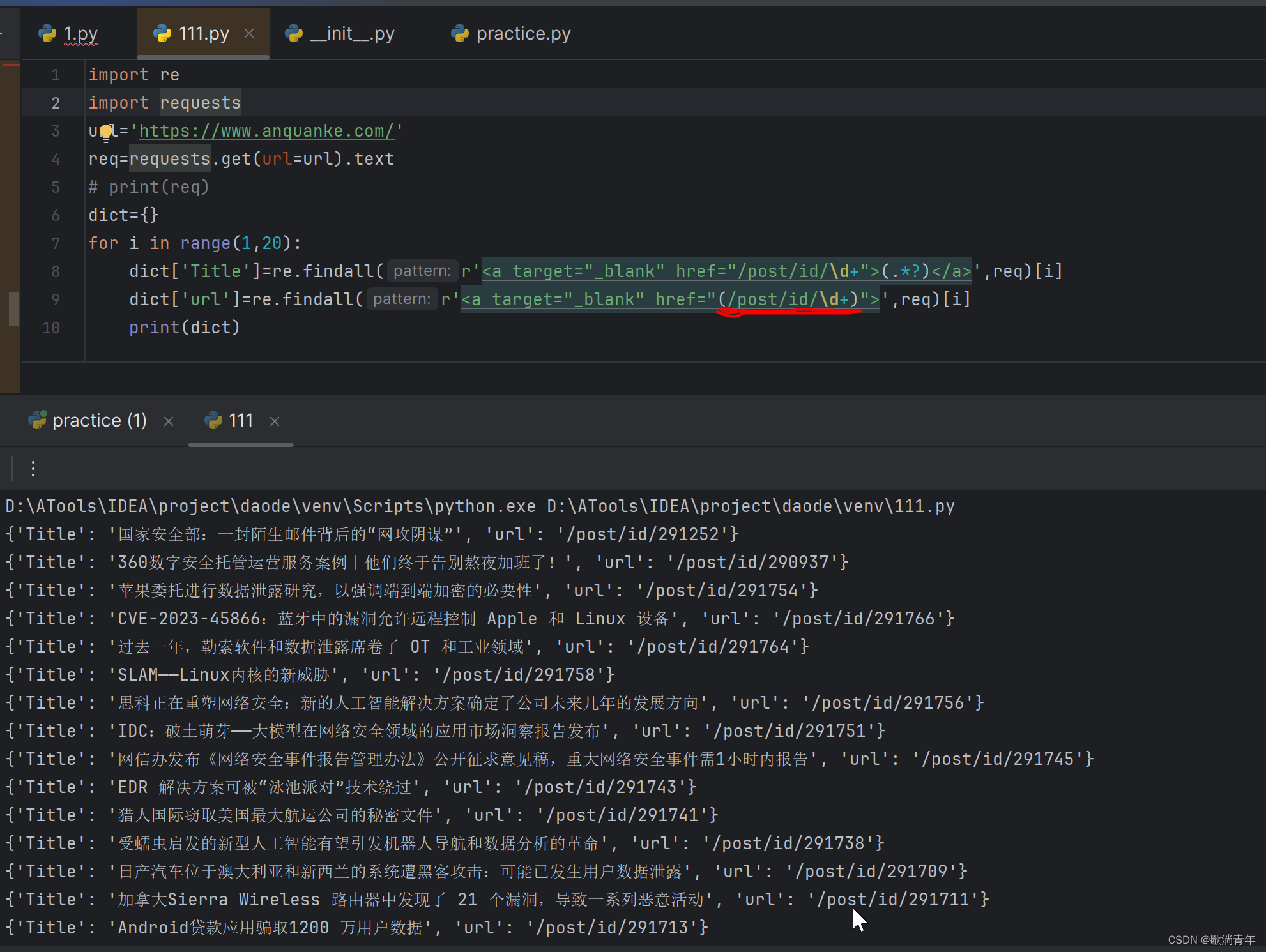
最终代码:
import re
import requests
#headers={}
url='https://www.anquanke.com/'
req=requests.get(url=url).text
# print(req)
dict={}
for i in range(1,20):
dict['Title']=re.findall(r'<a target="_blank" href="/post/id/\d+">(.*?)</a>',req)[i]
dict['url']=re.findall(r'<a target="_blank" href="(/post/id/\d+)">',req)[i]
print(dict)
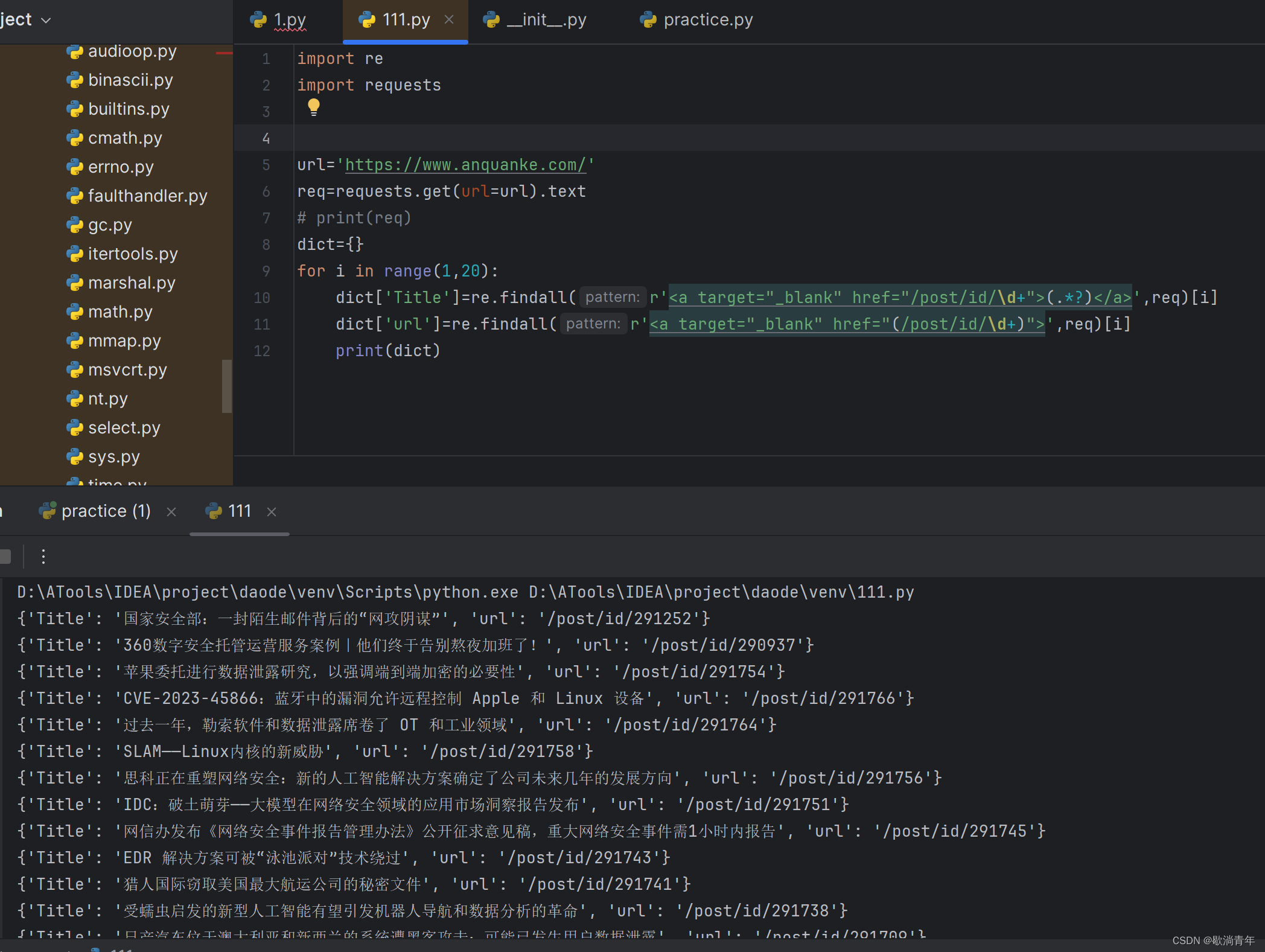
优化后的代码:
import re
import requests
url='https://www.anquanke.com/'
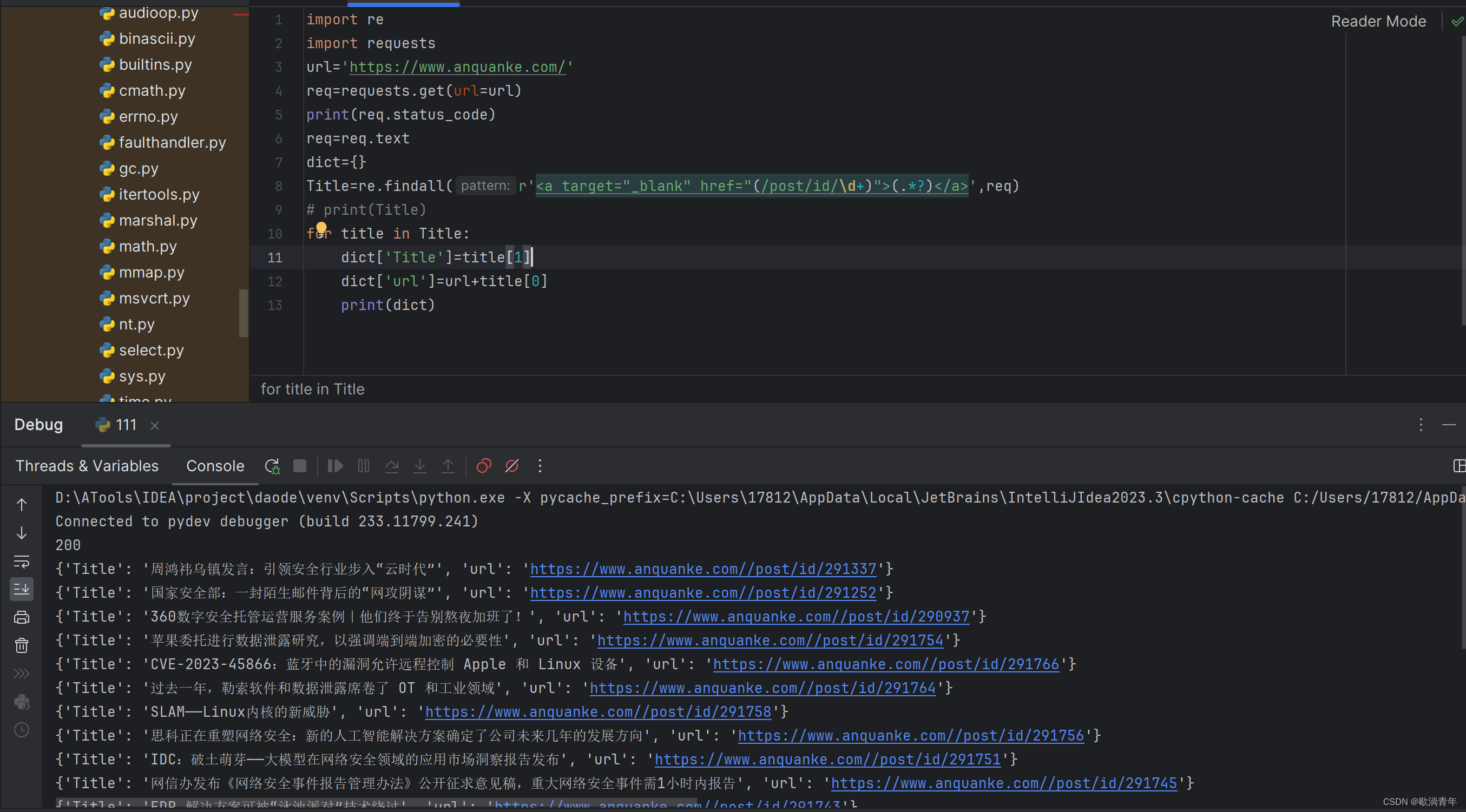
req=requests.get(url=url)
print(req.status_code)
req=req.text
dict={}
Title=re.findall(r'<a target="_blank" href="(/post/id/\d+)">(.*?)</a>',req)
# print(Title)
for title in Title:
dict['Title']=title[1]
dict['url']=url+title[0]
print(dict)
最后
从时代发展的角度看,网络安全的知识是学不完的,而且以后要学的会更多,同学们要摆正心态,既然选择入门网络安全,就不能仅仅只是入门程度而已,能力越强机会才越多。
因为入门学习阶段知识点比较杂,所以我讲得比较笼统,大家如果有不懂的地方可以找我咨询,我保证知无不言言无不尽,需要相关资料也可以找我要,我的网盘里一大堆资料都在吃灰呢。
干货主要有:
①1000+CTF历届题库(主流和经典的应该都有了)
②CTF技术文档(最全中文版)
③项目源码(四五十个有趣且经典的练手项目及源码)
④ CTF大赛、web安全、渗透测试方面的视频(适合小白学习)
⑤ 网络安全学习路线图(告别不入流的学习)
⑥ CTF/渗透测试工具镜像文件大全
⑦ 2023密码学/隐身术/PWN技术手册大全
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
扫码领取
















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









