






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
(▽)本周任务:
1.请根据本文 TensorFlow 代码,编写出相应的 Pytorch 代码(建议使用上周的数据测试一下模型是否构建正确)
2.了解ResNetV2与ResNetV的区别
3.改进思路是否可以迁移到其他地方呢(自由探索)
一、ResNetV2
ResNetV2即残差网络的第二版,是在ResNet基础上进行改进和优化的深度学习模型架构,以下是对其模型架构的详细介绍:
总体架构
ResNetV2整体依然保持了残差网络的基本结构风格,由多个残差块堆叠而成,通常包括输入层、若干个残差块组成的主体部分、全局平均池化层和全连接输出层。其核心思想仍然是通过残差连接来解决随着网络深度增加而出现的梯度消失和退化问题,使得网络能够训练得更深,同时保持较好的性能。
残差块
- 结构特点:ResNetV2的残差块与ResNet的残差块有所不同,它采用了一种“预激活”(pre-activation)的设计。在传统的ResNet残差块中,是先进行卷积操作,然后接激活函数等。而在ResNetV2中,顺序变为了先进行批量归一化(Batch Normalization,BN)和激活函数(通常是ReLU)操作,然后再进行卷积操作。
- 前向传播:对于输入特征图(x),首先经过BN和ReLU激活,得到(h(x)),即(h(x) = ReLU(BN(x)))。然后(h(x))经过一系列卷积操作得到(F(h(x)))。最后,残差连接将输入(x)与(F(h(x)))相加,得到输出(y = x + F(h(x)))。
- 优势:这种预激活的设计有几个优点。一是可以加速收敛,由于在卷积之前进行了归一化和激活,使得输入到卷积层的数据分布更加稳定,有利于卷积层的训练;二是可以减少梯度消失的问题,因为激活函数在卷积之前,梯度在反向传播时更容易通过激活函数传递,使得网络更容易训练深层网络。
卷积层
- 卷积核与步长:ResNetV2中的卷积层在不同的阶段会使用不同大小的卷积核和步长。通常,在网络的浅层,会使用较小的卷积核如(3\times3),步长为1或2,用于提取图像的低级特征,如边缘、线条等。随着网络深度的增加,卷积核的大小可能会适当增大,步长也可能会根据需要进行调整,以逐渐提取更高级、更抽象的特征。
- 卷积层的堆叠:多个卷积层会堆叠在一起形成卷积组,每个卷积组中的卷积层共享一些参数设置,并且通过残差连接相互关联。在每个卷积组内,卷积层的输出通道数会逐渐增加,以捕捉更多的特征信息。
池化层
- 作用与位置:池化层在ResNetV2中主要用于降低特征图的维度,减少计算量,同时保留重要的特征信息。一般在网络的早期阶段,会在卷积层之后使用最大池化层或平均池化层。例如,在输入图像经过几个卷积层提取初步特征后,会通过一个池化层来缩小特征图的尺寸,然后再将其输入到后续的残差块中。
- 池化方式:常用的池化方式有最大池化和平均池化。最大池化是取池化窗口内的最大值作为输出,能够突出特征的最大值信息,对于提取图像中的关键特征很有帮助。平均池化则是取池化窗口内的平均值作为输出,它可以对特征进行平滑处理,减少噪声的影响。
全连接层
- 位置与作用:全连接层位于网络的最后阶段,在经过多个残差块和全局平均池化层之后。其作用是将前面提取到的特征向量映射到最终的分类类别或回归目标上。全连接层中的每个神经元都与上一层的所有神经元相连,能够对整个特征向量进行综合处理,得到最终的预测结果。
- 参数数量与计算量:全连接层通常包含大量的参数,其参数数量取决于上一层的特征维度和输出的类别数量。在训练过程中,全连接层的计算量相对较大,因为它需要对所有的连接进行加权求和等操作。
其他改进
- BN层的改进:在ResNetV2中,批量归一化层得到了进一步的优化和调整。通过对每个小批量数据进行归一化操作,使得数据在进入下一层之前具有稳定的分布,减少了内部协变量偏移(Internal Covariate Shift)问题,从而加速了网络的收敛速度,并且可以使用更大的学习率进行训练。
- 初始化方式:采用了更合适的权重初始化方法,如Kaiming初始化等。这种初始化方法能够根据卷积层的输入和输出通道数等信息,自适应地初始化权重,使得网络在训练初期能够更快地收敛,并且有助于避免梯度消失或爆炸等问题。
二、与ResNet相比ResNetV2的改进有哪些?
ResNetV2是ResNet的改进版本,以下是ResNetV2结构与ResNet结构的对比:
残差连接方式
- ResNet:采用简单的加法残差连接,即(x + F(x)),将输入(x)直接与经过卷积等操作后的特征(F(x))相加,这种连接方式能有效解决训练过程中的梯度消失问题,使得网络可以训练得更深。
- ResNetV2:在残差连接中引入了批量归一化(Batch Normalization,BN)和激活函数的顺序调整。先对输入(x)进行BN和ReLU激活,再与(F(x))相加,即(x + F(x)),其中(x)先经过(BN)和(ReLU),这种方式使得模型的训练更加稳定,收敛速度更快。
卷积层与激活函数的顺序
- ResNet:常规的ResNet中,卷积层之后通常紧接着激活函数ReLU,即先进行卷积操作提取特征,然后通过ReLU激活函数对特征进行非线性变换,增强模型的表达能力。
- ResNetV2:采用了“预激活”(Pre-activation)的方式,先对输入进行BN和ReLU激活,再进入卷积层。这种顺序调整可以使得输入数据在进入卷积层之前就已经经过了归一化和非线性变换,有助于提高模型的训练效率和泛化能力。
计算量和模型复杂度
- ResNet:随着网络深度的增加,ResNet的计算量和模型复杂度会相应增加。在一些深层结构中,可能会出现参数过多、计算成本过高的问题。
- ResNetV2:虽然ResNetV2在结构上进行了改进,但并没有显著增加计算量和模型复杂度。通过合理的设计,ResNetV2在保持模型性能提升的同时,能够较好地控制计算成本和模型大小,使得模型在实际应用中更加高效。
性能表现
- ResNet:在图像识别等任务中已经取得了非常好的性能,能够有效地提取图像的特征,对各种复杂的图像数据具有较强的适应性。但在一些极深的网络结构中,可能会出现训练困难、过拟合等问题。
- ResNetV2:通过改进残差连接和预激活机制,ResNetV2在性能上通常优于ResNet。它能够更快地收敛,达到更高的准确率,尤其在处理大规模图像数据和复杂任务时,表现出更好的稳定性和泛化能力。
三、ResNetV2代码实现
1. 库函数
import matplotlib.pyplot as plt
from torchvision import transforms, datasets
import os, PIL, pathlib
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
import numpy as np
2.数据导入
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据集路径
data_dir = "./data/day_eight/bird_photos"
data_dir = pathlib.Path(data_dir)
# 图片总数
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
图片总数为: 565
3.获取数据路径和类别名称
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[3] for path in data_paths]
print(classeNames)
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
4.数据预处理
# 定义批量大小和图像尺寸
batch_size = 8
img_height = 224
img_width = 224
# 定义数据预处理转换
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载数据集
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
# 划分训练集和验证集
train_size = int(0.8 * len(total_data))
val_size = len(total_data) - train_size
train_dataset, val_dataset = random_split(total_data, [train_size, val_size])
# 创建数据加载器
train_ds = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_ds = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
5.可视化数据集
plt.figure(figsize=(10, 5))
plt.suptitle("数据集")
images, labels = next(iter(train_ds))
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
image = images[i].permute(1, 2, 0).cpu().numpy()
# 反归一化
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
plt.imshow(image)
plt.title(classeNames[labels[i].item()])
plt.axis("off")
plt.show()

5.模型定义
# 定义残差块
class Block2(nn.Module):
def __init__(self, in_channels, filters, kernel_size=3, stride=1, conv_shortcut=False, name=None):
super(Block2, self).__init__()
self.preact_bn = nn.BatchNorm2d(in_channels)
self.preact_relu = nn.ReLU(inplace=True)
if conv_shortcut:
self.shortcut = nn.Conv2d(in_channels, 4 * filters, kernel_size=1, stride=stride)
else:
if stride > 1:
self.shortcut = nn.MaxPool2d(kernel_size=1, stride=stride)
else:
self.shortcut = nn.Identity()
self.conv1 = nn.Conv2d(in_channels, filters, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(filters)
self.relu1 = nn.ReLU(inplace=True)
self.pad2 = nn.ZeroPad2d((1, 1, 1, 1))
self.conv2 = nn.Conv2d(filters, filters, kernel_size=kernel_size, stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(filters)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(filters, 4 * filters, kernel_size=1)
self.add = nn.Identity()
def forward(self, x):
preact = self.preact_relu(self.preact_bn(x))
shortcut = self.shortcut(preact) if isinstance(self.shortcut, nn.Conv2d) else self.shortcut(x)
x = self.relu1(self.bn1(self.conv1(preact)))
x = self.relu2(self.bn2(self.conv2(self.pad2(x))))
x = self.conv3(x)
x = self.add(shortcut + x)
return x
class Stack2(nn.Module):
def __init__(self, in_channels, filters, blocks, stride1=2, name=None):
super(Stack2, self).__init__()
self.block1 = Block2(in_channels, filters, conv_shortcut=True, name=name + '_block1')
self.blocks = nn.ModuleList([
Block2(4 * filters, filters, name=name + '_block' + str(i)) for i in range(2, blocks)
])
self.last_block = Block2(4 * filters, filters, stride=stride1, name=name + '_block' + str(blocks))
def forward(self, x):
x = self.block1(x)
for block in self.blocks:
x = block(x)
x = self.last_block(x)
return x
class ResNet50V2(nn.Module):
def __init__(self, include_top=True, preact=True, use_bias=True, weights=None, input_shape=None, pooling=None,
classes=1000, classifier_activation='softmax'):
super(ResNet50V2, self).__init__()
self.include_top = include_top
self.preact = preact
self.pooling = pooling
self.classifier_activation = classifier_activation
self.pad1 = nn.ZeroPad2d((3, 3, 3, 3))
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, bias=use_bias)
if not preact:
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=True)
self.pad_pool1 = nn.ZeroPad2d((1, 1, 1, 1))
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = Stack2(64, 64, 3, name='conv2')
self.conv3 = Stack2(256, 128, 4, name='conv3')
self.conv4 = Stack2(512, 256, 6, name='conv4')
self.conv5 = Stack2(1024, 512, 3, stride1=1, name='conv5')
if preact:
self.post_bn = nn.BatchNorm2d(2048)
self.post_relu = nn.ReLU(inplace=True)
if include_top:
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, classes)
else:
if pooling == 'avg':
self.pool = nn.AdaptiveAvgPool2d((1, 1))
elif pooling == 'max':
self.pool = nn.AdaptiveMaxPool2d((1, 1))
def forward(self, x):
x = self.conv1(self.pad1(x))
if not self.preact:
x = self.relu1(self.bn1(x))
x = self.pool1(self.pad_pool1(x))
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
if self.preact:
x = self.post_relu(self.post_bn(x))
if self.include_top:
x = self.avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
if self.classifier_activation == 'softmax':
x = torch.softmax(x, dim=1)
else:
if self.pooling is not None:
x = self.pool(x)
x = torch.flatten(x, 1)
return x
6.模型训练
# 创建模型实例
num_classes = len(classeNames)
model = ResNet50V2(input_shape=(224, 224, 3), classes=num_classes).to(device)
# 使用 torchsummary 打印模型结构
print(summary(model, input_size=(3, 224, 224)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ZeroPad2d-1 [-1, 3, 230, 230] 0
Conv2d-2 [-1, 64, 112, 112] 9,472
ZeroPad2d-3 [-1, 64, 114, 114] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
BatchNorm2d-5 [-1, 64, 56, 56] 128
ReLU-6 [-1, 64, 56, 56] 0
Conv2d-7 [-1, 256, 56, 56] 16,640
Conv2d-8 [-1, 64, 56, 56] 4,096
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
ZeroPad2d-11 [-1, 64, 58, 58] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 16,640
Identity-16 [-1, 256, 56, 56] 0
Block2-17 [-1, 256, 56, 56] 0
BatchNorm2d-18 [-1, 256, 56, 56] 512
ReLU-19 [-1, 256, 56, 56] 0
Identity-20 [-1, 256, 56, 56] 0
Conv2d-21 [-1, 64, 56, 56] 16,384
BatchNorm2d-22 [-1, 64, 56, 56] 128
ReLU-23 [-1, 64, 56, 56] 0
ZeroPad2d-24 [-1, 64, 58, 58] 0
Conv2d-25 [-1, 64, 56, 56] 36,864
BatchNorm2d-26 [-1, 64, 56, 56] 128
ReLU-27 [-1, 64, 56, 56] 0
Conv2d-28 [-1, 256, 56, 56] 16,640
Identity-29 [-1, 256, 56, 56] 0
Block2-30 [-1, 256, 56, 56] 0
BatchNorm2d-31 [-1, 256, 56, 56] 512
ReLU-32 [-1, 256, 56, 56] 0
MaxPool2d-33 [-1, 256, 28, 28] 0
Conv2d-34 [-1, 64, 56, 56] 16,384
BatchNorm2d-35 [-1, 64, 56, 56] 128
ReLU-36 [-1, 64, 56, 56] 0
ZeroPad2d-37 [-1, 64, 58, 58] 0
Conv2d-38 [-1, 64, 28, 28] 36,864
BatchNorm2d-39 [-1, 64, 28, 28] 128
ReLU-40 [-1, 64, 28, 28] 0
Conv2d-41 [-1, 256, 28, 28] 16,640
Identity-42 [-1, 256, 28, 28] 0
Block2-43 [-1, 256, 28, 28] 0
Stack2-44 [-1, 256, 28, 28] 0
BatchNorm2d-45 [-1, 256, 28, 28] 512
ReLU-46 [-1, 256, 28, 28] 0
Conv2d-47 [-1, 512, 28, 28] 131,584
Conv2d-48 [-1, 128, 28, 28] 32,768
BatchNorm2d-49 [-1, 128, 28, 28] 256
ReLU-50 [-1, 128, 28, 28] 0
ZeroPad2d-51 [-1, 128, 30, 30] 0
Conv2d-52 [-1, 128, 28, 28] 147,456
BatchNorm2d-53 [-1, 128, 28, 28] 256
ReLU-54 [-1, 128, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 66,048
Identity-56 [-1, 512, 28, 28] 0
Block2-57 [-1, 512, 28, 28] 0
BatchNorm2d-58 [-1, 512, 28, 28] 1,024
ReLU-59 [-1, 512, 28, 28] 0
Identity-60 [-1, 512, 28, 28] 0
Conv2d-61 [-1, 128, 28, 28] 65,536
BatchNorm2d-62 [-1, 128, 28, 28] 256
ReLU-63 [-1, 128, 28, 28] 0
ZeroPad2d-64 [-1, 128, 30, 30] 0
Conv2d-65 [-1, 128, 28, 28] 147,456
BatchNorm2d-66 [-1, 128, 28, 28] 256
ReLU-67 [-1, 128, 28, 28] 0
Conv2d-68 [-1, 512, 28, 28] 66,048
Identity-69 [-1, 512, 28, 28] 0
Block2-70 [-1, 512, 28, 28] 0
BatchNorm2d-71 [-1, 512, 28, 28] 1,024
ReLU-72 [-1, 512, 28, 28] 0
Identity-73 [-1, 512, 28, 28] 0
Conv2d-74 [-1, 128, 28, 28] 65,536
BatchNorm2d-75 [-1, 128, 28, 28] 256
ReLU-76 [-1, 128, 28, 28] 0
ZeroPad2d-77 [-1, 128, 30, 30] 0
Conv2d-78 [-1, 128, 28, 28] 147,456
BatchNorm2d-79 [-1, 128, 28, 28] 256
ReLU-80 [-1, 128, 28, 28] 0
Conv2d-81 [-1, 512, 28, 28] 66,048
Identity-82 [-1, 512, 28, 28] 0
Block2-83 [-1, 512, 28, 28] 0
BatchNorm2d-84 [-1, 512, 28, 28] 1,024
ReLU-85 [-1, 512, 28, 28] 0
MaxPool2d-86 [-1, 512, 14, 14] 0
Conv2d-87 [-1, 128, 28, 28] 65,536
BatchNorm2d-88 [-1, 128, 28, 28] 256
ReLU-89 [-1, 128, 28, 28] 0
ZeroPad2d-90 [-1, 128, 30, 30] 0
Conv2d-91 [-1, 128, 14, 14] 147,456
BatchNorm2d-92 [-1, 128, 14, 14] 256
ReLU-93 [-1, 128, 14, 14] 0
Conv2d-94 [-1, 512, 14, 14] 66,048
Identity-95 [-1, 512, 14, 14] 0
Block2-96 [-1, 512, 14, 14] 0
Stack2-97 [-1, 512, 14, 14] 0
BatchNorm2d-98 [-1, 512, 14, 14] 1,024
ReLU-99 [-1, 512, 14, 14] 0
Conv2d-100 [-1, 1024, 14, 14] 525,312
Conv2d-101 [-1, 256, 14, 14] 131,072
BatchNorm2d-102 [-1, 256, 14, 14] 512
ReLU-103 [-1, 256, 14, 14] 0
ZeroPad2d-104 [-1, 256, 16, 16] 0
Conv2d-105 [-1, 256, 14, 14] 589,824
BatchNorm2d-106 [-1, 256, 14, 14] 512
ReLU-107 [-1, 256, 14, 14] 0
Conv2d-108 [-1, 1024, 14, 14] 263,168
Identity-109 [-1, 1024, 14, 14] 0
Block2-110 [-1, 1024, 14, 14] 0
BatchNorm2d-111 [-1, 1024, 14, 14] 2,048
ReLU-112 [-1, 1024, 14, 14] 0
Identity-113 [-1, 1024, 14, 14] 0
Conv2d-114 [-1, 256, 14, 14] 262,144
BatchNorm2d-115 [-1, 256, 14, 14] 512
ReLU-116 [-1, 256, 14, 14] 0
ZeroPad2d-117 [-1, 256, 16, 16] 0
Conv2d-118 [-1, 256, 14, 14] 589,824
BatchNorm2d-119 [-1, 256, 14, 14] 512
ReLU-120 [-1, 256, 14, 14] 0
Conv2d-121 [-1, 1024, 14, 14] 263,168
Identity-122 [-1, 1024, 14, 14] 0
Block2-123 [-1, 1024, 14, 14] 0
BatchNorm2d-124 [-1, 1024, 14, 14] 2,048
ReLU-125 [-1, 1024, 14, 14] 0
Identity-126 [-1, 1024, 14, 14] 0
Conv2d-127 [-1, 256, 14, 14] 262,144
BatchNorm2d-128 [-1, 256, 14, 14] 512
ReLU-129 [-1, 256, 14, 14] 0
ZeroPad2d-130 [-1, 256, 16, 16] 0
Conv2d-131 [-1, 256, 14, 14] 589,824
BatchNorm2d-132 [-1, 256, 14, 14] 512
ReLU-133 [-1, 256, 14, 14] 0
Conv2d-134 [-1, 1024, 14, 14] 263,168
Identity-135 [-1, 1024, 14, 14] 0
Block2-136 [-1, 1024, 14, 14] 0
BatchNorm2d-137 [-1, 1024, 14, 14] 2,048
ReLU-138 [-1, 1024, 14, 14] 0
Identity-139 [-1, 1024, 14, 14] 0
Conv2d-140 [-1, 256, 14, 14] 262,144
BatchNorm2d-141 [-1, 256, 14, 14] 512
ReLU-142 [-1, 256, 14, 14] 0
ZeroPad2d-143 [-1, 256, 16, 16] 0
Conv2d-144 [-1, 256, 14, 14] 589,824
BatchNorm2d-145 [-1, 256, 14, 14] 512
ReLU-146 [-1, 256, 14, 14] 0
Conv2d-147 [-1, 1024, 14, 14] 263,168
Identity-148 [-1, 1024, 14, 14] 0
Block2-149 [-1, 1024, 14, 14] 0
BatchNorm2d-150 [-1, 1024, 14, 14] 2,048
ReLU-151 [-1, 1024, 14, 14] 0
Identity-152 [-1, 1024, 14, 14] 0
Conv2d-153 [-1, 256, 14, 14] 262,144
BatchNorm2d-154 [-1, 256, 14, 14] 512
ReLU-155 [-1, 256, 14, 14] 0
ZeroPad2d-156 [-1, 256, 16, 16] 0
Conv2d-157 [-1, 256, 14, 14] 589,824
BatchNorm2d-158 [-1, 256, 14, 14] 512
ReLU-159 [-1, 256, 14, 14] 0
Conv2d-160 [-1, 1024, 14, 14] 263,168
Identity-161 [-1, 1024, 14, 14] 0
Block2-162 [-1, 1024, 14, 14] 0
BatchNorm2d-163 [-1, 1024, 14, 14] 2,048
ReLU-164 [-1, 1024, 14, 14] 0
MaxPool2d-165 [-1, 1024, 7, 7] 0
Conv2d-166 [-1, 256, 14, 14] 262,144
BatchNorm2d-167 [-1, 256, 14, 14] 512
ReLU-168 [-1, 256, 14, 14] 0
ZeroPad2d-169 [-1, 256, 16, 16] 0
Conv2d-170 [-1, 256, 7, 7] 589,824
BatchNorm2d-171 [-1, 256, 7, 7] 512
ReLU-172 [-1, 256, 7, 7] 0
Conv2d-173 [-1, 1024, 7, 7] 263,168
Identity-174 [-1, 1024, 7, 7] 0
Block2-175 [-1, 1024, 7, 7] 0
Stack2-176 [-1, 1024, 7, 7] 0
BatchNorm2d-177 [-1, 1024, 7, 7] 2,048
ReLU-178 [-1, 1024, 7, 7] 0
Conv2d-179 [-1, 2048, 7, 7] 2,099,200
Conv2d-180 [-1, 512, 7, 7] 524,288
BatchNorm2d-181 [-1, 512, 7, 7] 1,024
ReLU-182 [-1, 512, 7, 7] 0
ZeroPad2d-183 [-1, 512, 9, 9] 0
Conv2d-184 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-185 [-1, 512, 7, 7] 1,024
ReLU-186 [-1, 512, 7, 7] 0
Conv2d-187 [-1, 2048, 7, 7] 1,050,624
Identity-188 [-1, 2048, 7, 7] 0
Block2-189 [-1, 2048, 7, 7] 0
BatchNorm2d-190 [-1, 2048, 7, 7] 4,096
ReLU-191 [-1, 2048, 7, 7] 0
Identity-192 [-1, 2048, 7, 7] 0
Conv2d-193 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-194 [-1, 512, 7, 7] 1,024
ReLU-195 [-1, 512, 7, 7] 0
ZeroPad2d-196 [-1, 512, 9, 9] 0
Conv2d-197 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-198 [-1, 512, 7, 7] 1,024
ReLU-199 [-1, 512, 7, 7] 0
Conv2d-200 [-1, 2048, 7, 7] 1,050,624
Identity-201 [-1, 2048, 7, 7] 0
Block2-202 [-1, 2048, 7, 7] 0
BatchNorm2d-203 [-1, 2048, 7, 7] 4,096
ReLU-204 [-1, 2048, 7, 7] 0
Identity-205 [-1, 2048, 7, 7] 0
Conv2d-206 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-207 [-1, 512, 7, 7] 1,024
ReLU-208 [-1, 512, 7, 7] 0
ZeroPad2d-209 [-1, 512, 9, 9] 0
Conv2d-210 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-211 [-1, 512, 7, 7] 1,024
ReLU-212 [-1, 512, 7, 7] 0
Conv2d-213 [-1, 2048, 7, 7] 1,050,624
Identity-214 [-1, 2048, 7, 7] 0
Block2-215 [-1, 2048, 7, 7] 0
Stack2-216 [-1, 2048, 7, 7] 0
BatchNorm2d-217 [-1, 2048, 7, 7] 4,096
ReLU-218 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-219 [-1, 2048, 1, 1] 0
Linear-220 [-1, 4] 8,196
================================================================
Total params: 23,527,556
Trainable params: 23,527,556
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 295.69
Params size (MB): 89.75
Estimated Total Size (MB): 386.01
----------------------------------------------------------------
None
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 训练参数
epochs = 10
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
# 训练循环
for epoch in range(epochs):
model.train()
train_loss = 0
train_correct = 0
train_total = 0
for images, labels in train_ds:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
train_loss /= len(train_ds)
train_accuracy = 100 * train_correct / train_total
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
model.eval()
val_loss = 0
val_correct = 0
val_total = 0
with torch.no_grad():
for images, labels in val_ds:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
val_loss /= len(val_ds)
val_accuracy = 100 * val_correct / val_total
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
print(f'Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.2f}%, Val Loss: {val_loss:.4f}, Val Acc: {val_accuracy:.2f}%')
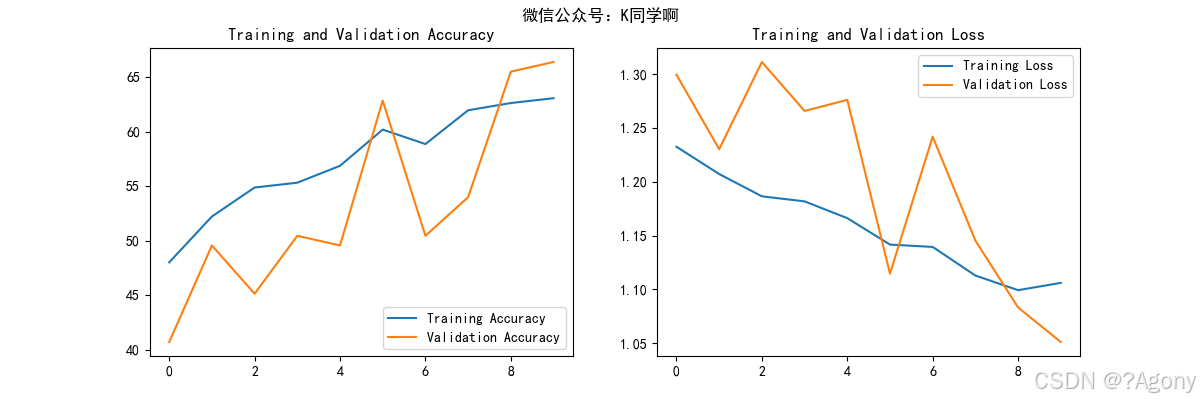
7. 绘制结果
# 绘制训练和验证曲线
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.suptitle("微信公众号:K同学啊")
plt.plot(epochs_range, train_accuracies, label='Training Accuracy')
plt.plot(epochs_range, val_accuracies, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_losses, label='Training Loss')
plt.plot(epochs_range, val_losses, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Epoch 1/10, Train Loss: 1.2325, Train Acc: 48.01%, Val Loss: 1.2994, Val Acc: 40.71%
Epoch 2/10, Train Loss: 1.2072, Train Acc: 52.21%, Val Loss: 1.2303, Val Acc: 49.56%
Epoch 3/10, Train Loss: 1.1865, Train Acc: 54.87%, Val Loss: 1.3113, Val Acc: 45.13%
Epoch 4/10, Train Loss: 1.1818, Train Acc: 55.31%, Val Loss: 1.2658, Val Acc: 50.44%
Epoch 5/10, Train Loss: 1.1662, Train Acc: 56.86%, Val Loss: 1.2761, Val Acc: 49.56%
Epoch 6/10, Train Loss: 1.1416, Train Acc: 60.18%, Val Loss: 1.1146, Val Acc: 62.83%
Epoch 7/10, Train Loss: 1.1394, Train Acc: 58.85%, Val Loss: 1.2419, Val Acc: 50.44%
Epoch 8/10, Train Loss: 1.1128, Train Acc: 61.95%, Val Loss: 1.1453, Val Acc: 53.98%
Epoch 9/10, Train Loss: 1.0992, Train Acc: 62.61%, Val Loss: 1.0832, Val Acc: 65.49%
Epoch 10/10, Train Loss: 1.1060, Train Acc: 63.05%, Val Loss: 1.0510, Val Acc: 66.37%

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









