







 ResNet v2分析了深度残差网络的信号传播,强调了恒等映射(identity mappings)在跳跃连接中的重要性,指出其在前向和反向传播中促进了信息的直接传递。实验表明,使用恒等映射的ResNet-1001在CIFAR-10/100和ImageNet上表现优异,而其他类型的跳跃连接或激活函数改变会导致训练困难和泛化能力下降。预激活残差单元提高了模型的正则化效果,使得更深网络的训练和优化变得更加容易。
ResNet v2分析了深度残差网络的信号传播,强调了恒等映射(identity mappings)在跳跃连接中的重要性,指出其在前向和反向传播中促进了信息的直接传递。实验表明,使用恒等映射的ResNet-1001在CIFAR-10/100和ImageNet上表现优异,而其他类型的跳跃连接或激活函数改变会导致训练困难和泛化能力下降。预激活残差单元提高了模型的正则化效果,使得更深网络的训练和优化变得更加容易。
ResNet v2:Identity Mappings in Deep Residual Networks
摘要:
ResNets v1作为一种极深的网络框架,在精度和收敛等方面都展现出了很好的特性。在本文,我们分析了残差块(residual building blocks)背后的信号传播公式(数学表达式),公式表明,当使用恒等映射(identity mappings)作为跳跃连接(skip connections)及信号加合后的激活函数时,前向、反向传播的信号能直接从一个残差块传递到其他任意一个残差块。一系列的“ablation”实验也验证了这些恒等映射的重要性。这促使我们提出了一个新的残差单元,它使得训练变得更容易(更容易收敛),同时也提高了网络的泛化能力。我们报告了1001层的ResNet在CIFAR-10(4.62% error) 和CIFAR-100上的结果,以及200层的ResNet在ImageNet上的结果。代码可在 https://github.com/KaimingHe/resnet-1k-layers上下载。
1.简介
ResNets v1堆叠了很多残差单元,每一个单元(图1a)能够写为下面的通用形式:
这里 xl x l 和 xl+1 x l + 1 是第 l l 个单元的输入和输出, 是一个残差函数。在ResNet中, h(xl)=xl h ( x l ) = x l 是一个identity mapping, f f 是一个ReLU函数。
超过100层的ResNets在ImageNet和MS COCO竞赛的许多识别挑战任务中展现出了极高的精度(state of art)。ResNets的核心思想是去学习加到 上的残差函数 F F ,这个思想的关键是恒等映射的使用。这种思想可以通过附加一个恒等跳跃连接(shortcut)来实现。
在本文中,我们致力于创建一个全局(整个网络)的直接信息传播路径来分析深度残差网络(而不是仅仅在残差单元内部)。我们的推导揭示了:如果 h(xl) h ( x l ) 和 f(yl) f ( y l ) 都采用恒等映射,那么在正向传播和反向传播中,信号总能从一个残差块传播到其它的任何一个残差块。我们的实验经验性地说明,当架构接近上面两种情况时,通常训练变得更加容易。
为了理解跳跃连接(skip connections)的作用,我们分析并对比了各种类型的 h(xl) h ( x l ) 。我们发现,在所有研究的类型中,ResNet v1中选择的恒等映射 h(xl)=xl h ( x l ) = x l 误差下降最快,训练误差最低。而使用缩放(scaling)、门控(gating)以及1×1 卷积的跳跃连接都产生了更高的训练损失和误差。这些实验表明,保持一个干净的(“clean”)信息通道(图1,2,4中灰色箭头)对于简化训练是十分有帮助的。
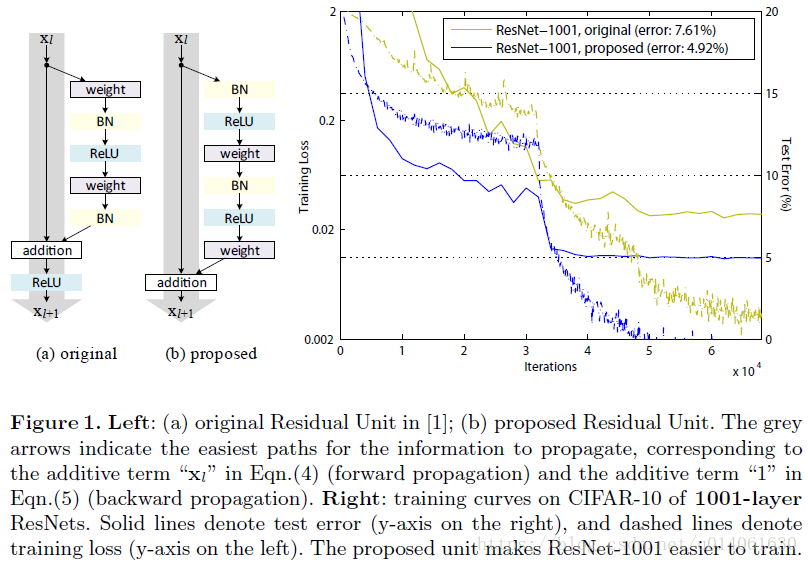
为了建立一个恒等映射 f(yl)=yl f ( y l ) = y l ,我们将激活函数(ReLU和BN)看作有权重的层(weight layer)的“pre-activation”。这个观点产生了一个新的残差单元设计(图1b)。基于这个单元设计设计的ResNet-1001在CIFAR-10/100上表现出了更优的结果,并且与原始的ResNet-1001相比,也更容易训练,泛化能力更强。原始的ResNet-200在ImageNet上出现了过拟合现象,我们进一步展示了改进后网络的结果。这些结果表明,深度作为深度学习陈工的关键,仍有很大的研究空间。
2.深度残差网络的分析
ResNet-v1是一个由很多残差块堆叠的模块化架构。本文中,我们称这些块为“残差单元”,ResNet-v1的残差单元进行以下的计算:
如果 f f 是一个恒等映射: ,我们可以把公式2带入公式1,得到:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









