






1. NLU 基础
- 定义与任务:Natural Language Understanding(自然语言理解),长期与 NLG(自然语言生成)作为 NLP 两大主流任务,在智能对话等应用广泛。如用户输入语句,机器人会进行情感倾向分析、意图识别、实体抽取、关系抽取等全面分析。
- 分析类型:
- 情感倾向分析:分正向、中性、负向等类型,也可细分。
- 意图识别:多为分类模型,包括多分类、层次分类、多标签分类。
- 实体抽取:抽取文本中有特定意义的词,如人名、地名等,常与业务相关。
- 关系抽取:找出实体间关系,如 “刘亦菲出演《天龙八部》”,“刘亦菲” 是人名,“《天龙八部》” 是作品名,关系是 “出演”。
- 分类层次:
- 句子级别分类:如情感分析、意图识别、关系抽取等,给定句子输出一个或多个 label。
- Token 级别分类:如实体抽取、阅读理解,每个 Token 对应一个或多个 label。如 “刘亦菲出演天龙八部”
- 刘/B-PER
亦/I-PER
菲/I-PER
出/O
演/O
天/B-WORK
龙/I-WORK
八/I-WORK
部/I-WORK
。/O -
1.1 句子级别的分类
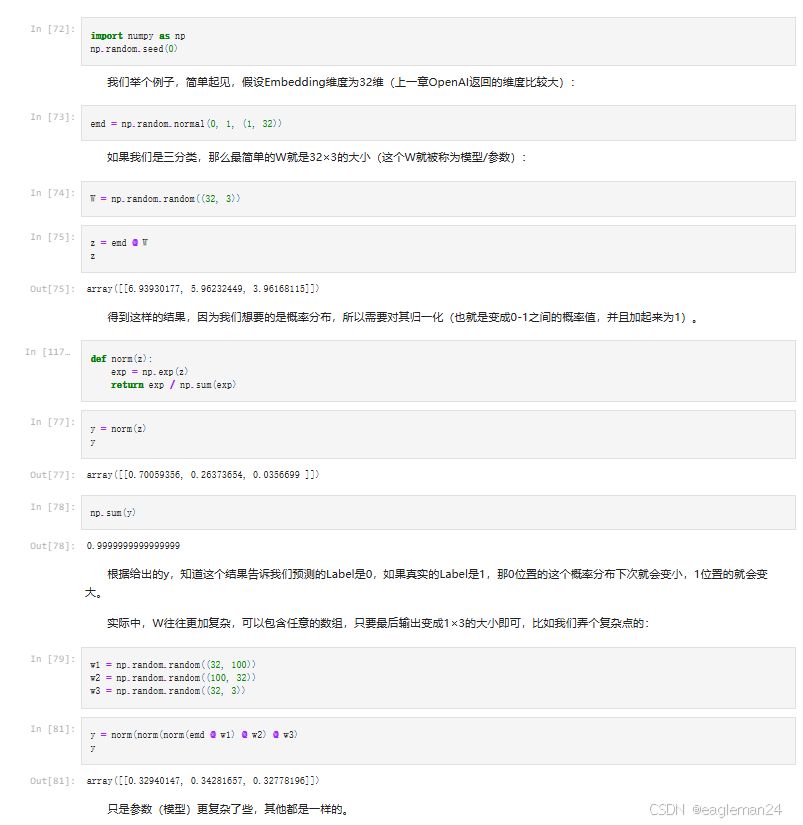
- 基本流程:句子级别分类是自然语言处理深度学习的基础应用。首先将给定句子或文本表征为 Embedding,接着把 Embedding 输入神经网络计算不同 Label 的概率分布,最后将该概率分布与真实分布做比较,通过误差回传修改神经网络参数。
- 简单示例(三分类):
- 假设 Embedding 维度为 32,用
np.random.normal(0, 1, (1, 32))生成。 - 三分类时简单的模型参数 W 大小为 32×3,用
np.random.random((32, 3))生成。通过z = embed @ W计算,得到的结果需归一化(变为 0 - 1 之间且和为 1 ),自定义norm函数实现归一化。
- 假设 Embedding 维度为 32,用
- 复杂示例:实际中 W 可更复杂,如通过
w1 = np.random.random((32, 100))、w2 = np.random.random((100, 30))、w3 = np.random.random((30, 3))构建,再进行计算和归一化。 - 多标签分类和层次分类:输出多个标签,处理更麻烦。以 10 个标签的多标签二分类为例,输出大小为 10×2,每行表示对应标签的概率分布。归一化时需指定维度。
- (图片来源:hugging-llm/content/chapter3/ChatGPT使用指南——句词分类.ipynb at main · datawhalechina/hugging-llm · GitHub)
-
1.2 Token 级别的分类
- 核心特点:Embedding 针对每个 Token。若给定文本长度为 10,维度 32,则 Embedding 大小为 (1, 10, 32),每个 Token 对应 32 维向量,模型可统一处理不同数量的 Token。
- 示例:假设 Label 共 5 个(B - PER, I - PER, B - WORK, I - WORK, O ) 。
- 用
embed = np.random.normal(0, 1, (1, 10, 32))生成 Embedding,W = np.random.random((32, 5))生成模型参数 W。 - 通过
z = embed @ W、y = norm(z)计算,得到的 y 形状为 (1, 10, 5) ,每行表示一个 Token 是某个 Label 的概率分布(每行和为 1 )。可据此判断预测的 Label,通过误差更新参数以提高预测准确性
- 用
- 2.相关API
1. 关键概念
• GPT:全称Generative Pretrained Transformer,是生成式预训练Transformer大模型。
• In - Context:上下文能力,模型通过学习大量文本获得,能根据输入文本自动给出结果。
• Zero - Shot:直接给模型文本,让其给出标签或输出。
• Few - Shot:先给模型一些类似案例(输入+输出),再给新的无输出输入,让模型生成输出。
2. API参数
• model:指定模型,如gpt-3.5-turbo ,需综合价格和效果选择。
• messages:支持多轮会话消息,每条消息为包含“role”和“content”的字典。
• max_tokens:生成的最大Token数,默认16,Token数与字数对中文近似一致,生成文本的Token长度不能超模型上下文长度。
• temperature:温度,介于0和2之间,值越高输出越随机,越低越集中确定。
• top_p:采样topN分布,默认1 。
• stop:停止的Token或序列,默认null,最多4个。
• presence_penalty:存在惩罚,介于-2.0和2.0之间,正值会根据新Token是否出现过惩罚,增加讨论主题可能性。
• frequency_penalty:频率惩罚,介于-2.0和2.0之间,正值根据Token频率惩罚,降低重复生成可能 。
3. 应用示例
• 情感分类:
• Zero - Shot:直接给出待分类内容,如“Apple, Facebook, FedEx”,模型可给出类别。
• Few - Shot:先给示例“今天真开心。 -->正向” “心情不好。 -->负向”,再给新句子“我们是快乐的年轻人。”,模型可判断情感倾向。
• 实体识别:
• Zero - Shot:按格式要求模型从文本中抽取实体,如从法律事件文本中抽取公司和人物。
• Few - Shot:先给抽取格式示例,再对音乐相关文本抽取和弦实体。
4. Prompt工程建议
• 清晰:避免复杂歧义,定义术语。
• 具体:语言具体,不抽象模糊。
• 聚焦:避免问题宽泛开放。
• 简洁:去除不必要描述。
• 相关:保持主题相关,不跑题。
5. 新手注意点
• 明确输出目标。
• 避免一次对话多个主题。
• 不让语言模型做数学题。
• 给出示例样本。
• 避免反向提示。
• 一次让模型做一件事,复杂任务可给示例(Few - Shot),简单任务直接描述要求。
-
3.
1. 文档问答(Document QA)
• 原理:先用QA方法召回相关文档,再让模型在文档中找答案,类似阅读理解任务,预测答案在文档中的索引位置(start和end)。
• 流程
• 召回:与上章QA类似,通过相似Embedding选择最相似的文档 。
• 回答:将召回文档和问题以Prompt方式提交给Completion/ChatCompletion接口获取答案。
• 代码实现
• 初始化:导入openai和zhipuai库,初始化相关客户端。
• 定义提问函数:定义ask和ask_zhipu函数分别调用OpenAI和智谱AI接口提问。
• 示例
• 英文示例:根据召回文档回答“Who won the 2020 Summer Olympics men’s high jump?”,答案为“Gianmarco Tamberi and Mutaz Essa Barshim”。
• 中文示例:根据上下文回答“诺曼底在哪个国家/地区?”,答案为“法国” 。
• 完整流程
• 加载数据集:从CSV文件加载与2020年夏季奥运会相关的数据集。
• 选择工具:使用Qdrant向量搜索引擎(比Redis更易扩展),通过Docker启动,安装客户端。
• 生成Embedding:定义get_embedding和get_embedding_zhipu函数分别生成OpenAI和智谱AI的Embedding,使用Batch方法处理大量数据并存储。
• 创建索引:使用QdrantClient创建集合,并设置向量参数。
• 向量入库:将数据以指定格式上传到Qdrant集合。
• 查询:将问题生成Embedding后在集合中查询相似文档。
• 构建Prompt:根据查询结果构建Prompt,包含相关文档内容和问题,然后调用模型获取答案。
2. 分类/实体微调
• 主题分类:给定文本判断所属主题,使用取自CLUBenchmark/CLUE的新闻主题分类数据集(共15个类别) 。
• 后续任务:后续会介绍更具体、常见的任务,但文档中未展开,仅提及开始导入数据集查看数据量(10000条) 。
-

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









