







Zero-Shot Foreign Accent Conversion without a Native Reference
Abstract
FAC(foreign accent conversion) 通常需要在合成器部分 a reference utterance from native speaker(L1) ,或者需要针对每一个 non-native speaker (L2)训练出专属的 one-to-one 模型。 本论文主要就是针对这类问题进行解决,提出了一个系统,包含两个单独的模块:一个translator 一个synthesizer。translator:将L2的BNF映射到L1BNF中。synthesizer是一个many-to-many,主要工作是将BNF映射到对应的mel频谱图当中。
Introduction
FAC目的是将非母语语音speaker保留其身份的前提下进行转换,转换好的语音被称为“golden speaker”。合适的“golden speaker”也会有助于L2进行更好的语音进步。
先前的FAC系统的两个limitation:
- 在合成期间需要L1speaker的reference,会导致后期的合成数据产生一定的偏差,效果不佳。
- Zhao的“reference-free”的模型需要对每一对L1和L2进行构建专用的one-to-one模型。对L2有很大的数据集要求。
提出的系统不用依赖L1的reference,可以直接通过L2的单个语句(one-shot)生成AC的结果
将reference-free FAC的任务分为两个小任务:pronunciation correction and voice conversion。由translator和synthesizer负责,均使用sequence-to-sequence作为主干分别train model。
L1和L2的音频转化为BNF(a linguistic representation derived from pho-
netic posteriorgrams that captures the pronunciation pattern of
the utterance ).translator 将L2的BNF转换为可能从L1发生出来的BNF。这是通过平行语料集(L1 L2)训练translator实现的。synthesizer是一个many-to-many的系统,在非平行语料库进行训练,产生mel频谱是来自BNF和speaker embedding。
inference时候,L2 fed to translator,输出送到synthesizer,与一个相同L2的embedding。
最终得到的是mel频谱图,为了得到音频,将mel图通过waveRNN neural vocoder得到。
Method
提供了一个 reference-free zero-shot的AC模型,主要是可以synthesizer标准以L2的音色,无需L1的平行语料。
总共包含5个组成部分:
- acoustic model:生成BNF
- speaker encoder:捕捉voice identity of a speaker
- accent encoder:捕捉accent identity of a speaker
- translator module: a seq2seq model,用L2的BNF和accent embedding生成本来应该由L1产出的BNF
- synthesizer:seq2seq model, input BNF and speaker embedding->output mel频谱
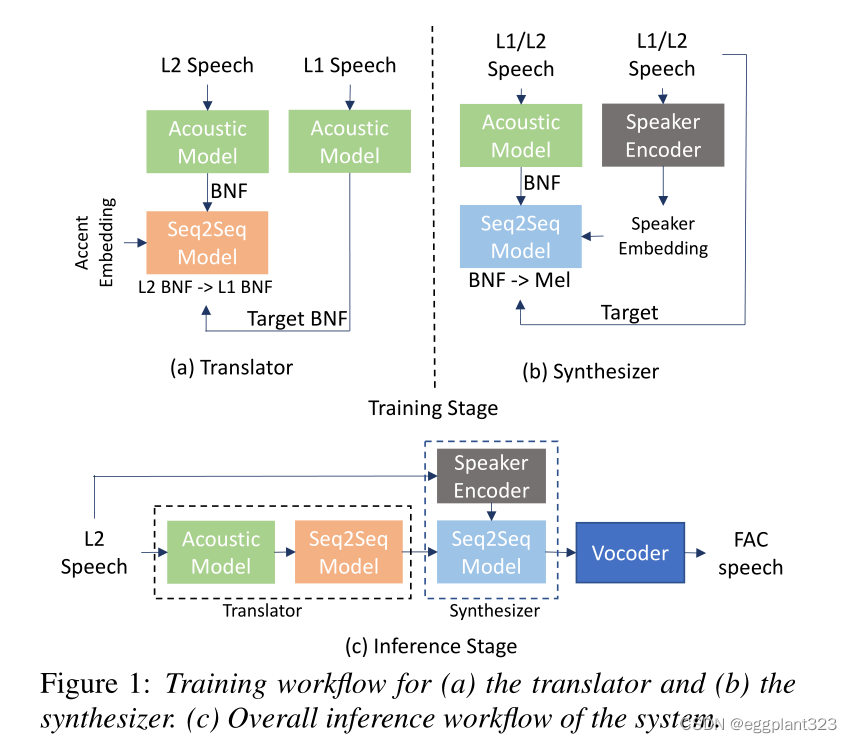
translator 主要是转L1/L2的BNF,train 使用parallel L2(包含口音)和L1(reference,model target)。
translator:
- 配对L1 L2语料库(pair of utterances)
- 将L2utterance通过acou model得到BNF。BNF仅仅包含语音info 与speaker是独立的
- 将L1 utterance喂给accent encoder得到accent embedding
- L2的BNF和L1的accent embedding喂给translator(trained output L1 BNF)
synthesizer:自监督 输出时候重建输入 无需平行语料
- 对utterance生成BNF
- 喂给synthesizer 配合对应的speaker embedding(在通过speaker encoder时候得到的)。
- train生成mel图
inference时候,从L2得到BNF并喂给translator。将translator的output结合speaker embedding传给synthesizer去得到 native-accented mel图。最后将mel图给waveRNN neural vocoder进行音频的输出。
acoustic model
input 一个语句(L1/L2),该模型生成相关的PPG(phonetic-potseriorgram),表示每个帧属于predefined 的语音模块的后验概率。PPG捕捉说话者的内容,并假设其speaker independent。将acoustic model的最后一个隐藏层的输出作为BNF代替PPG。BNF包含与PPG相似的信息,但是维度低很多。acoustic model like in “Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams”
accent and speaker encoder
用accent and speaker encoder分别获得口音和说话者的身份。将speaker encoder train成speaker-verification model 用Generalized end-
to-end loss for speaker verification提到的框架。给定一个语句,speaker encoder可以生成带有speaker identity的embedding向量。由每层具有256个隐藏节点的3层LSTM组成。最后一层的隐藏层将喂给256单元的projection 层。使用GE2Eloss训练。
accent encoder的结构等与其相似,但是其主要目的是为了识别出accent。
translator and synthesizer
包含seq2seq模型。对于synthesizer,input是BNF序列对(T*D)和对应的speaker embedding(M)。T是BNF的长度,D是BNF维度(256),M是speaker embedding的维度(256)。
将BNF序列x转入到encoder中,得到:z=encoder(x)。将speaker embedding s连接,Zconcat=[z,s]。将得到的Zconcat反馈到attention机制生成attention context,结合起来给decoder预测出对应的mel频谱图。以L2作为目标:Omel=decoder(Zconcat)。将输出的结果预测mel谱图的post-net,使用两者之间的欧几里得距离作为loss function。用cross-entropy 计算stop-token。
修改原本的tacotron2架构,将bi-LSTM层替换为两个pyramidal bi-LSM(p-Bi-LSM)。减少了时间也因此生成的encoder序列比输入短了4倍。translator有类似结构,将accent embedding待敌本身的speaker embedding,并生成等效的L1 BNF。
Discussion
这个系统可以将unseen L2 speaker转换为听起来是native accent。这是通过训练一个model去转换L2的BNF变为等效的L1的BNF,通过这个方法纠正L2的发音问题。该系统更好的一个原因可能是因为在训练translator的过程中使用了多个不同口音的speaker。
待解决问题:
- 提高生成后的MOS评分;
- 解决unseen accents as input;
- 保证生成转换的鲁棒性,attention部分可能会因为long utterance而不稳定,可以使用类似高斯混合进行替代注意力机制;
- transformer model可以替换seq2seq model,可能还会压缩时间。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









