







Pre-training BERT using Hugging Face & TensorFlow on an AMD GPU — ROCm Blogs

2024年1月29日, 由 Vara Lakshmi Bayanagari 撰写。
这篇博客详细讲解了从头开始预训练双向编码表征变换模型(BERT base模型)的全过程。该过程中使用了Hugging Face库和TensorFlow作为后端,所用文本为英文语料库(WikiText-103-raw-v1)。
您可以在 GitHub文件夹 中找到与此博客文章相关的文件。
BERT简介
BERT 是一种在2019年提出的语言表示模型。该模型的架构来自于一个transformer编码器,其中自注意力层计算输入标记每对之间的注意力,从而融入了双向的上下文(因此有了BERT中“Bidirectional”一词)。在此之前,像ELMo和GPT这样的模型仅使用从左到右的(单向的)架构,这严重限制了模型的代表性;模型性能取决于微调。
BERT paper 首次提出了一种新颖的预训练方法,称为掩码语言模型(MLM)。MLM随机掩盖输入的某些部分,并在一批输入上训练模型以预测这些被掩盖的标记。在预训练期间,输入经过标记化后,15%的标记会被随机选择。在这些被选择的标记中,80%会被替换为`[MASK]`标记,10%会被替换为随机标记,10%则保持不变。在下面的示例中,MLM预处理如下:`dog`标记保持不变,`Golden`和`years`标记被掩蔽,`and`标记被替换为随机标记`paper`。预训练目标是使用`CategoricalCrossEntropy`损失来预测这些随机标记,以便模型学习语言的语法、模式和结构。
Input sentence: My dog is a Golden Retriever and his is 5 years old
After MLM: My dog is a [MASK] Retriever paper his is 5 [MASK] old此外,为了捕捉句子之间的关系,超越掩码语言模型任务,论文提出了第二个预训练任务,称为下一句预测(NSP)。在不改变架构的情况下,论文证明NSP有助于提升问答(QA)和自然语言推理(NLI)任务的效果。
在这个任务中,模型不仅输入一串标记,还输入句子对,假设句子`A`和`B`,还有一个前导分类标记(`[CLS]`)。分类标记指示句对是否是随机形成的(标签=0)或`B`是否在`A`之后(标签=1)。因此,NSP预训练是一个二分类任务。
_IsNext_ Pair: [1] My dog is a Golden Retriever. He is five years old.
Not _IsNext_ Pair: [0] My dog is a Golden Retriever. The next chapter in the book is a biography.首先对数据集进行预处理以形成句对,随后进行标记化,并最终随机掩码标记。一批预处理后的输入要么会被_填充_(使用`[PAD]`标记),要么会被_修剪_(以`_max_seq_length_超参数为准),这样所有输入元素的长度都会被统一,然后加载到BERT模型中。BERT模型包含两个分类头:一个用于MLM(num_cls_heads = vocab_size),另一个用于NSP(num_cls_heads=2`)。两个预训练任务的分类损失总和用于训练BERT。
在 AMD GPU 上的实现
在开始之前,确保您已满足以下要求:
-
Install ROCm-compatible TensorFlow on the device hosting AMD GPU在托管 AMD GPU 的设备上安装与 ROCm 兼容的 TensorFlow。本实验已在 ROCm 5.7.0 和 TensorFlow 2.13 上测试。
-
运行命令
pip install datasets transformers以安装 Hugging Face 库。
实现
训练一个BERT模型可以总结为三行代码!(是的,仅此而已。)
Transformer编码器、MLM分类头和NSP分类头都包装在Hugging Face的`BertForPreTraining`模型中,该模型返回累计分类损失,正如我们在介绍中解释的一样。该模型使用默认的BERT base配置参数(NUM_LAYERS、`ACT_FUNC`、`BATCH_SIZE`、`HIDDEN_SIZE`、`EMBED_DIM`和其他)初始化。你可以从Hugging Face的`BertConfig`中导入这些参数。
那就完了吗?几乎。训练的第一部分也是最关键的一部分是数据预处理。涉及到三个步骤:
-
将数据集重新组织为每个文档的句子字典。这在为NSP任务选择随机文档中的随机句子时非常有用。为此,使用一个简单的for循环遍历整个数据集。
-
使用Hugging Face的`Autokenizer`对所有句子进行分词。
-
使用另一个for循环,创建50%随机对和50%按顺序对的句子对。
我对包含2,500百万词的`WikiText-103-raw-v1`语料库进行了上述预处理步骤,然后将处理后的验证数据集上传到这个库中。预处理后的训练拆分上传在Hugging Face Hub的此处。
接下来,导入`DataCollatorForLanguageModeling`收集器以运行MLM预处理并获得掩码和句子分类标签。出于演示目的,我使用了包含4,000多句子的`Wikitext-103-raw-v1`验证拆分。使用`_to_tf_dataset_函数将得到的数据集转换为TensorFlow tf.data.Dataset`对象。
tokenized_dataset_valid = datasets.load_from_disk('./wikiTokenizedValid.hf')
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
collater = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=MLM_PROB, return_tensors="tf"
)
valid = tokenized_dataset_valid.to_tf_dataset(
columns=["input_ids", "token_type_ids", "attention_mask"],
label_cols=["labels", "next_sentence_label"],
batch_size=TRAIN_BATCH_SIZE,
shuffle=False,
collate_fn=collater,
)
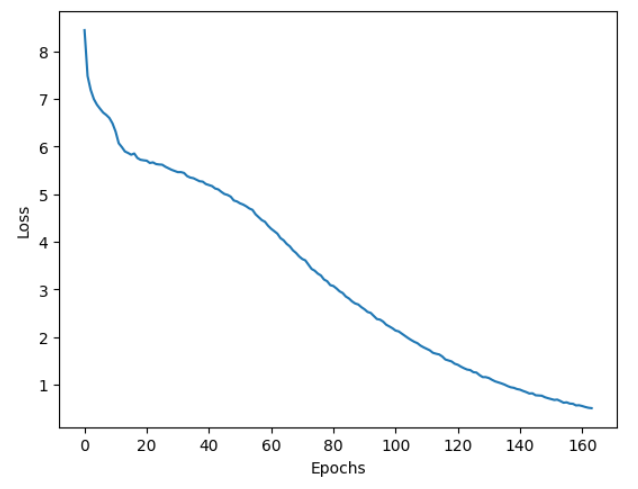
del tokenized_dataset_valid将此数据集传递给`model.fit()`函数并开始训练吧!使用Adam优化器(learning_rate=2e-5)和`batch_size=5`模型大约训练了160个时期。在一台AMD GPU(MI210,ROCm 5.7.0,TensorFlow 2.13)上使用验证集(3,000+句子对)进行预训练仅需数小时。得到的训练曲线如图1所示。你可以使用最佳模型检查点微调不同的数据集并测试在各种NLP任务上的表现。
完整代码如下:
import datasets
from transformers import DataCollatorForLanguageModeling, AutoTokenizer, BertConfig
import random
import logging
import tensorflow as tf
from tensorflow import keras
# 只记录错误消息
tf.get_logger().setLevel(logging.ERROR)
# 设置随机种子
tf.keras.utils.set_random_seed(42)
MLM_PROB = 0.2# MLM中掩码的概率
TRAIN_BATCH_SIZE = 5
MAX_EPOCHS = 200# 模型的最大训练周期
LEARNING_RATE = 2e-5# 模型训练的学习率
#tokenized_dataset_train = datasets.load_from_disk('./wikiTokenizedTrain.hf')
tokenized_dataset_valid = datasets.load_from_disk('./wikiTokenizedValid.hf')
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
collater = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=MLM_PROB, return_tensors="tf"
)
valid = tokenized_dataset_valid.to_tf_dataset(
columns=["input_ids", "token_type_ids", "attention_mask"],
label_cols=["labels", "next_sentence_label"],
batch_size=TRAIN_BATCH_SIZE,
shuffle=False,
collate_fn=collater,
)
del tokenized_dataset_valid
config = BertConfig.from_pretrained('bert-base-cased')
print(tf.config.list_physical_devices())
from transformers import TFBertForPreTraining
try:
# 指定有效的GPU设备
with tf.device('/device:GPU:0'):
model = TFBertForPreTraining(config)
optimizer = keras.optimizers.Adam(learning_rate=LEARNING_RATE)
model.compile(optimizer=optimizer)
model.fit(valid,epochs=MAX_EPOCHS,callbacks = [tf.keras.callbacks.ModelCheckpoint('./{epoch:02d}.ckpt')])
except RuntimeError as e:
print(e)推理
将示例文本使用tokenizer转换成输入tokens,生成带有掩码的输入。
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
collater = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=MLM_PROB, return_tensors="tf"
)
text="The author takes his own advice when it comes to writing: he seeks to ground his claims in clear, concrete examples. He shows specific examples of bad writing to help readers better grasp exactly what he’s critiquing"
tokens = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))
inp = collater([tokens])
在没有预训练权重的情况下初始化模型并进行推理。你可以看到模型生成了没有语境意义的随机token。
config = BertConfig.from_pretrained('bert-base-cased')
model = TFBertForPreTraining(config)
out = model.predict(inp)
print('Input: ', tokenizer.decode(inp['input_ids'][0]), '\n')
print('Output: ', tokenizer.decode(tf.argmax(out[0],-1)[0]))Input: The author takes his own [MASK] when it comes to writing : he seeks to ground his claims in clear, [MASK] examples [MASK] [MASK] shows [MASK] [MASK] of [MASK] writing to help readers better reptiles exactly what he ’ s critiquing
Output: ہ owing difference Ana editorσFI akin logistics Universal dickpine boxer nationalist television Party survivebach revolvespineḤ Sense beard Clive motto akin‘ abortion constituency Administrator Sense Universal Engineers molecular laughing wanna swim TanakaḤ noisesCs Administrator Gilesae Administrator使用TensorFlow的`load_weights`函数加载预训练权重。
model.load_weights('path/to/ckpt/folder/variables/variables')再次对相同文本进行推理,注意到对输入文本和预测`[MASK]`token理解的显著变化。
out = model.predict(inp)
print('Input: ', tokenizer.decode(inp['input_ids'][0]), '\n')
print('Output: ', tokenizer.decode(tf.argmax(out[0],-1)[0]))输入和输出示例如下。模型在一个非常小的数据集(3,000+ 句子)上训练;通过在更大的数据集上训练,使用更多的steps或epochs,可以提高性能。
Input: The author takes his own [MASK] when it comes to writing : he seeks to ground his claims in clear, [MASK] examples [MASK] [MASK] shows [MASK] [MASK] of [MASK] writing to help readers better reptiles exactly what he ’ s critiquing
Output: The author takes his own, when it comes to writing : he continued to ground his claims in clear, as examples of. shows. University of the writing to help and better. on what he's crit " give结论:
在本文中,我们通过MLM和NSP预训练任务复现了BERT预训练,不同于许多公共平台上仅使用MLM的资源。此外,我们不仅仅使用了小部分的数据集,而是预处理并上传了整个数据集到Hub,方便大家使用。在未来的文章中,我们将讨论使用多个AMD GPU进行训练的数据并行和分布策略。
我们概述的BERT基础模型预训练过程可以轻松扩展到更小或更大的BERT版本以及不同的数据集。我们使用Hugging Face的Trainer,并以TensorFlow为后端,使用一块AMD GPU进行训练。训练过程中,我们使用了wiki数据集的验证集分割,但可以轻松替换为训练集分割,只需下载我们在Hugging Face Hub上托管的预处理和标记过的训练文件即可。


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











