




Unlocking Vision-Text Dual-Encoding: Multi-GPU Training of a CLIP-Like Model ROCm Blogs

2024年4月24日,由Sean Song撰写。
在本博客中,我们将构建一个类似CLIP的视觉-文本双编码器模型,并在AMD GPU上使用ROCm对其进行微调,使用COCO数据集。这项工作受到CLIP原理和Hugging Face 示例的启发。我们的目标是联合训练一个视觉编码器和一个文本编码器,将图像及其描述的表示投射到相同的嵌入空间中,使文本嵌入位于描述其图像的嵌入附近。在训练过程中,目标是最大化批次内图像和文本对嵌入的相似性,同时最小化错误对的嵌入相似性。该模型通过学习一个多模态嵌入空间来实现这一点。使用对称交叉熵损失优化这些相似性分数。
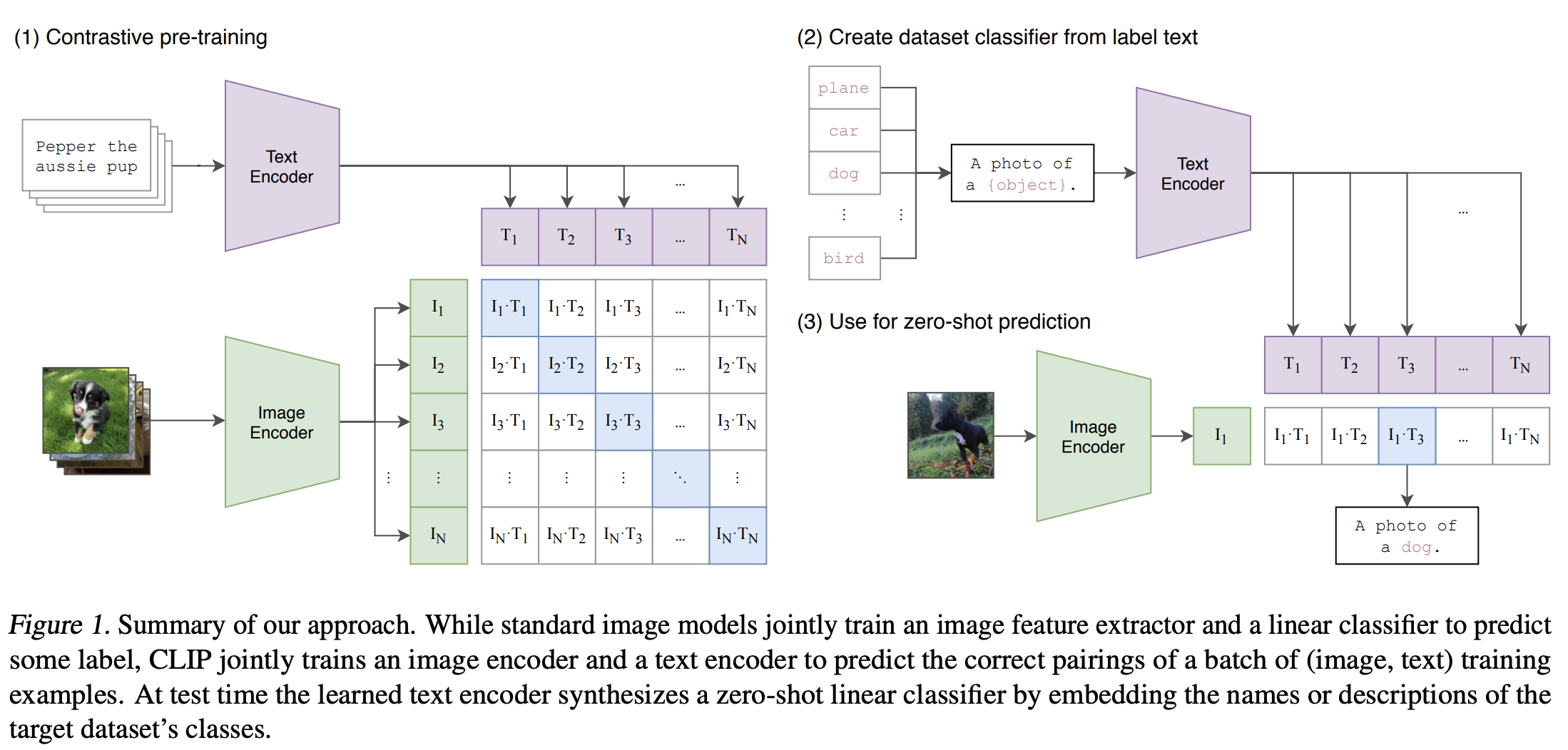
图片来源:从自然语言监督中学习可迁移的视觉模型。
视觉-文本双编码器模型可以应用于广泛的下游视觉和语言任务,如图像分类、目标检测、图像描述、视觉问答等。参考我们之前的与CLIP互动博客,了解如何使用预训练的CLIP模型来计算图像和文本之间的相似性,以实现零样本图像分类。
您可以在vision-text-dual-encoding找到本博客中使用的完整代码。
配置
本演示是在以下设置下创建的。有关全面的支持细节,请参阅 ROCm 文档.
-
硬件和操作系统:
-
Ubuntu 22.04.3 LTS
-
软件:
1. 入门
安装所需的库。
!pip install datasets accelerate matplotlib -U
建议从源代码安装 Transformers。
%%bash git clone https://github.com/huggingface/transformers cd transformers pip install -e .
检查系统上 GPU 的可用性。
!rocm-smi
==================== ROCm System Management Interface =========================
========================= Concise Info ===================================
GPU Temp (DieEdge) AvgPwr SCLK MCLK Fan Perf PwrCap VRAM% GPU%
0 39.0c 41.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
1 42.0c 43.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
2 41.0c 43.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
3 41.0c 40.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
4 41.0c 44.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
5 40.0c 42.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
6 37.0c 43.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
7 40.0c 43.0W 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
====================================================================================
=================== End of ROCm SMI Lo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 2210
2210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











