




Speed Up Text Generation with Speculative Sampling on AMD GPUs — ROCm Blogs

随着变压器模型的规模增长,进行推理的成本也在增加,影响了延迟和吞吐量。量化和蒸馏等压缩方法,以及诸如闪存注意力和Triton等硬件优化,已被提出在不同层面上减少计算成本。然而,这些方法要么在准确性上有所妥协,要么需要对模型实现进行重大改动。
投机采样是一种加速推理的技术(在70B Chinchilla模型上可以提高2-2.5倍的速度),既不改变数学准确性,也不改变模型配置或训练。此外,它可以与上述优化策略结合使用,进一步减少文本生成的延迟。在这篇博客文章中,我们将简要介绍投机采样、基于草稿模型和目标模型的算法方法,以及其在使用ROCm的AMD GPU上的实现。
了解推测采样
推测采样技术在DeepMind的论文Accelerating Large Language Model Decoding with Speculative Sampling和Google Research的论文Fast Inference from Transformers via Speculative Decoding中首次提出。尽管两者略有不同,但它们都提出了类似的策略来减少大型语言模型的推断成本。
在高层次上,推测采样采用辅助生成的方法,使用一个小型的草稿模型来生成接下来的`k`个token,并使用一个大型的目标模型来验证这些生成的token。使用这种方法生成和验证token所需的总时间低于仅使用大型目标模型生成token的时间。
使用草稿模型的基本原理是,大多数“下一个token”的预测是简单而显而易见的。例如,它们可能是常见的短语或预期的代词。想象一下,使用一个具有数十亿参数的模型的前向传递仅仅是为了生成一个逗号作为下一个token!一个较小版本的模型能做到吗?在大多数情况下,它可以。
此外,大多数变压器模型中的计算更依赖于内存带宽,而不是计算能力。随着参数数量的增加,矩阵乘法器和大型KV缓存的内存带宽使用率也会增加,因此有必要减小模型的大小,从而减少延迟。
此外,推测采样并行地对K个token进行评分和验证,这相较于传统自回归方法提高了速度。
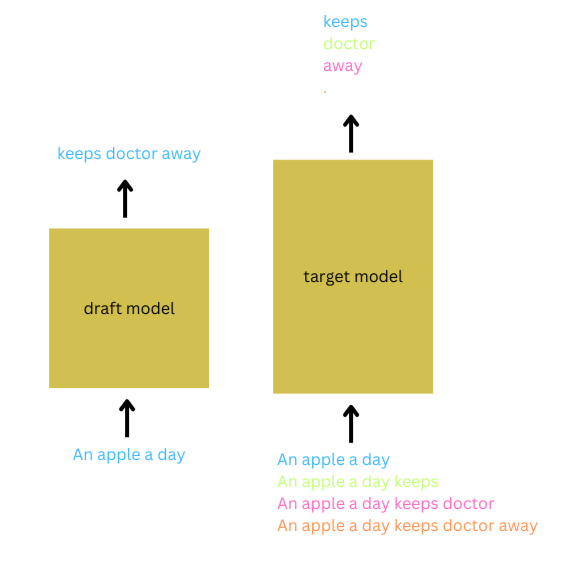
为了说明推测采样,考虑输入提示“An apple a day”。设置K=3,草稿模型自回归地推测接下来的3个token将是“keeps doctor away”。目标模型将输入提示与预测token的不同延续进行批处理以验证这些预测。当满足验证标准时,并且草稿模型的分布与目标模型的分布在所有三个token上都非常接近,则接受这三个token的预测。除了接受前`K`个token的预测外,还接受目标模型对`(K+1)`个token的预测。在这种情况下,`K+1`个token在大型模型的单次前向传递和草稿模型的`K`次前向传递中生成,从而大大减少了延迟。这个过程将重复进行,直到达到所需序列长度。
自然地,我们好奇如果任何预测的token未通过验证会发生什么。为了解决这一问题,作者提出了一种`修改后的拒绝采样`策略。验证策略如算法2所述,通过计算目标模型预测该token的概率的比率,即`q(x_n+1|x_1,...,x_n)`,与草稿模型预测该token的概率,即`p(x_n+1|x_1,...,x_n)`。如果这个比率高于指定的阈值,则接受该token。如果该比率低于此阈值,则拒绝该token,并从基于这两个概率`q()-p()`差异的新分布中重新采样。

图片来源于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











