







The key aspects ofsystem are:
- We learn joint pushing and grasping policies through self-supervised trial and error. Pushing actions are useful only if, in time, enable grasping. This is in contrast to prior approaches that define heuristics or hard-coded objectives for pushing motions.
- We train our policies end-to-end with a deep network that takes in visual observations and outputs expected return (i.e. in the form of Q values) for potential pushing and grasping actions. The joint policy then chooses the action with the highest Q value – i.e. , the one that maximizes the expected success of current/future grasps. This is in contrast to explicitly perceiving individual objects and planning actions on them based on handdesigned Features
Problem Formulation
Formulate the task of pushing-for-grasping as a Markov decision process:
a given state \(S_t\)
an action \(a_t\)
a police \(\pi(s_t)\)
a new state \(s_{t+1}\)
an immediate corresponding reward \(R_{a_t}(s_t,s_{t+1})\)
Goal
find an optimal policy \(\pi^*\) that maximizes te expected sum of future rewards, given by \(R_t = \sum_{i=t}^{\infty}\gamma R_{a_i}(s_i,s_{i+1})\)
\(\gamma\)-discounted sum over an infinite-horizon of future returns from time t to \(\infty\)
Use Q-learning to to train a greedy deterministic policy
Learning objective is to iteratively minimize the temporal difference error \(\delta_{t}\) of \(Q_\pi(s_t,a_t)\) to a fixed target value \(y_t\)
δ
t
=
∣
Q
(
s
t
,
a
t
)
−
y
t
∣
\delta_t = |Q(s_t,a_t)-y_t|
δt=∣Q(st,at)−yt∣
y
t
=
R
a
t
(
s
t
,
s
t
+
1
)
+
γ
Q
(
s
t
+
1
,
a
r
g
m
a
x
a
′
(
Q
(
s
t
+
1
,
a
′
)
)
)
y_t = R_{a_t}(s_t,s_{t+1}) + \gamma Q(s_{t+1},argmax_{a^{'}}(Q(s_{t+1},a^{'})))
yt=Rat(st,st+1)+γQ(st+1,argmaxa′(Q(st+1,a′)))
\(a^{’}\) the set of all available actions
Method
A. State Representations
model each state \(s_t\) as an RGB-D heightmap image
- capture RGB-D images from a fixed-mount camera, project the data onto a 3D point cloud
- orthographically back-project upwards in the gravity direction to construct a heightmap image representation with both color (RGB) and height-from-bottom (D) channels
B. Primitive Actions
Parameterize each action \(a_t\) as a motion primitive behavior \(\psi\) esecuted at the 3D loacation q projected from a pixel p of the heightmap images representation of the state \(s_t\):
a
=
(
ψ
,
q
)
∣
ψ
∈
p
u
s
h
,
g
r
a
s
p
,
q
→
p
∈
s
t
a = (\psi,q) | \psi \in {push,grasp}, q \to p \in s_t
a=(ψ,q)∣ψ∈push,grasp,q→p∈st
motion primitive behaviors are defined as follows:
Pushing: q starting position of a 10cm push in one of k = 16 directions
Grasping: q the middle position of a top-down parallel-jaw grasp in one of k=16 orientations
C. Learning Fully COnvolutional Action-Value Functions
extend vanilla deep Q-networks(DQN) by modeling Q-function as two feed-forward fully convolutional networks \(\Phi_p\) \(\Phi_g\)
input: the heightmap image representation of the state s_t
outputs: a dense pixel-wise map of Q values with the same image size and resolution as that of \(s_t\)
Both FCNs φ p and φ g share the same network architecture: two parallel 121-layer DenseNet pre-trained on ImageNet , followed by channel-wise concatenation and 2 additional 1 × 1 convolutional layers interleaved with nonlinear activation functions (ReLU) and spatial batch normalization, then bilinearly upsampled.
D. Rewards
\(R_g(s_t,s_{t+1}) = 1\) if grasp is successful
\(R_p(s_t,s_{t+1}) = 0.5\) if pushed that make detetable changes. if the sum of differences between heightmaps exceeds some threshold
E. Training details
Our Q-learning FCNs are trained at each iteration i using the Huber loss function:
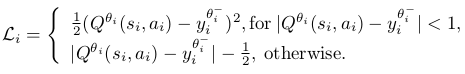
F.Testing details
Limitation
- Motion primitives are defined with parameters specified on a regular grid (heightmap), which provides learning efficiency with deep networks, but limits expressiveness – it would be interesting to explore other parameterizations that allow more expressive motions (without excessively inducing sample complexity), including more dynamic pushes, parallel rather than sequential combinations of pushing and grasping, and the use of more varied contact surfaces of the robot.
- Train our system only with blocks and test with a limited range of other shapes (fruit, bottles, etc.) – it would be interesting to train on larger varieties of shapes and further evaluate the generalization capabilities of the learned policies.
- study only synergies between pushing and grasping, which are just two examples of the larger family of primitive manipulation actions, e.g. rolling, toppling, squeezing, levering, stacking, among others















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









