









Imagenet-trained cnns are Biased towards Texture; Increasing Shape Bias Improves Accuracy And Robustness
RobertGeirhos University of T¨ubingen & IMPRS-IS robert.geirhos@bethgelab.org
PatriciaRubisch University of T¨ubingen & U. of Edinburgh p.rubisch@sms.ed.ac.uk
ClaudioMichaelis University of T¨ubingen & IMPRS-IS claudio.michaelis@bethgelab.org
MatthiasBethge∗ matthias.bethge@bethgelab.org
FelixA.Wichmann∗ felix.wichmann@uni-tuebingen.de
WielandBrendel∗ University of T¨ubingen wieland.brendel@bethgelab.org
这是ICLR 2019的一篇oral文章,文章不是讲的关于对抗样本相关的,是因为在最新一篇对抗样本的文章中涉及到了它,感觉很有意思,同时读完以后觉得也很有实验探索价值,所以把它放在了这里。
**这篇文章主要实验探索了CNNs在判别物体时,到底是依赖的物体纹理还是依赖的物体的形状。**因为在去年自己做的实验当中也发现了这么一个现象,目标检测网络是可以通过物体的形状来检测目标的。而本篇论文主要是基于图像分类网络做的相关实验。不知道图像分类网络和目标检测网络在这相关领域是否存在一些差异,当然文中也涉及到了一点相关的实验。
本篇文章解读,也主要将以高度总结的形式,进行相关的梳理以及最后的总结。主要包括如下4个点及最后的总结:
1.数据集及简单的实验对比
2.人及基于ImageNet训练的CNNs的纹理vs形状偏置
3.在Stylized-ImageNet上学习一个基于形状表征的CNNs
4.基于形状表征判别的CNNs的鲁棒性及准确度
5.总结
摘要
有的人认为CNNs主要是基于物体的形状表征来识别物体的,而有的研究认为物体的纹理在识别过程当中起到了至关重要的角色。本篇论文通过在texture-shape冲突的数据集上,来定量的实验验证人及CNNs在识物上依赖(纹理or形状)的不同。我们展示了基于ImageNet训练的网络跟依赖于纹理判别,而人类却更依赖于形状判别。同时我们展示了基于ImageNet训练的网络可以学习到基于纹理的表征,及基于Stylized-ImageNet训练的网络可以学习到基于形状的表征。并通过一系列实验验证了基于形状判别的网络具有更好的目标检测性能及更好的鲁棒性。
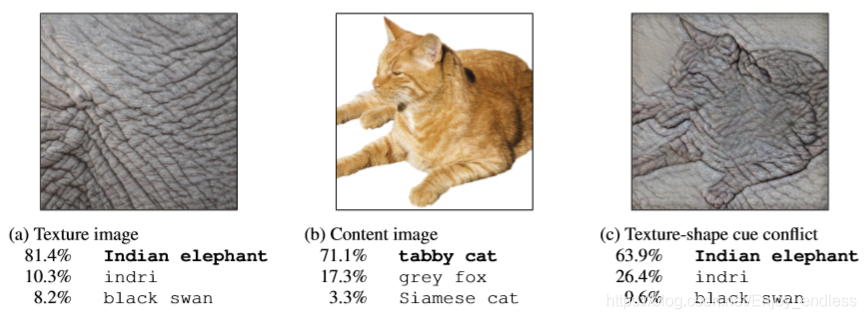
如上图所示,第一张为纹理图像,Cnns高度判别为大象,第二张为原整体图像,CNNs判别为猫,第三张即为Texture-shape冲突的图像(猫形状+大象纹理),而CNNs同样判别为了大象。
1.数据集及简单的实验对比
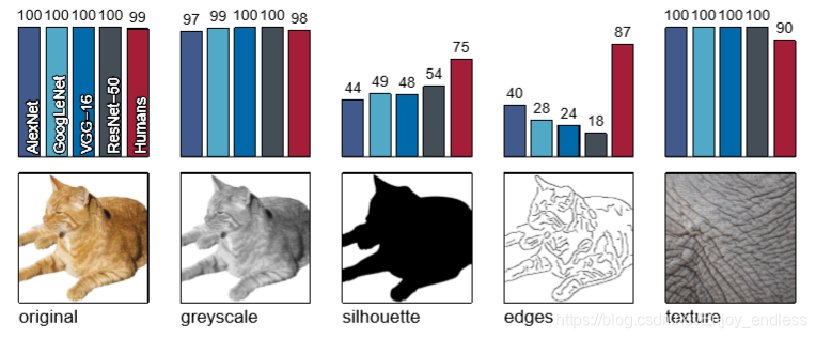
如上图所示为基本的数据集,包括:原始图像,灰度图,轮廓图,边缘图及纹理图。
图像上方的柱状图分别表示基于原始ImageNet训练的不同网络(AlexNet、LeNet、VGG等)及人在相应图像上的分类结果。
根据简单的实验结果可以看到,网络对于轮廓及边缘图像分类能力较差,而对于人类来说还是可以接收的。
但是这样简单的对比是不公平的,本身网络是基于ImageNet训练的,应用于不同图像的测试,不同图像可能具有不同的数据分布,所以分类效果下降是有可能的。
于是提出了新的数据集包括:Texture-shape冲突的图像数据集(物体形状及纹理来源于不同类别),及Stylized-ImagNet数据集。

如上利用风格迁移的技术,分别获得原ImageNet图像对应的Stylized-ImagNet图像,这些图像大部分保留了原图像的物体形状,而移除了其局部的纹理信息。
2.人及基于ImageNet训练的CNNs的纹理vs形状偏置

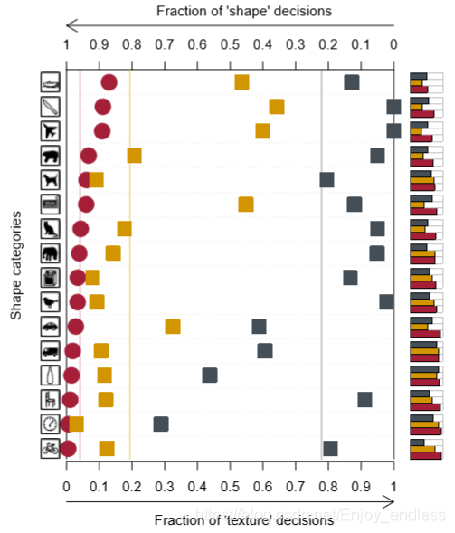
如上图实验结果所示,基于Texture-shape冲突的图像数据集,人及CNNs在识别图像时的主要依赖是形状还是纹理(实验时,判别人及CNNs的答案是与形状类别相同还是与纹理类别相同)。
横坐标下面箭头表示判别结果相同于纹理信息,上面箭头表示判别结果相同于形状信息,纵坐标表示各个类别。红圈表示人类的判别结果,而绿蓝黑等形状分别表示不同CNNs的判别结果。
从实验结果,可以明显得出,人在判别图像类别时更偏向于形状判别,而CNNs更依赖于纹理信息的判别。
3.在Stylized-ImageNet上学习一个基于形状表征的CNNs
既然上一步实验结果表明了基于ImageNet训练的网络更依赖于目标纹理实现图像分类,那么如何训练一个基于物体形状来实现图像分类的网络呢。
dataset: Stylized-ImageNet
nework: BagNets maximum receptive field size is limited to 9×9, 17×17 or 33×33(限制网络的接收域)
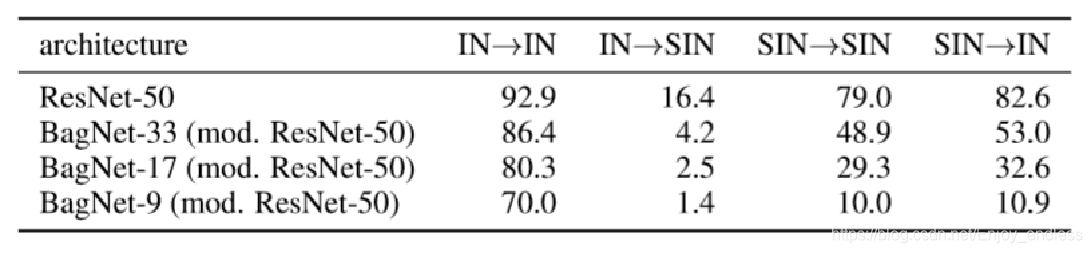
IN表示ImageNet数据集,SIN表示Stylized-ImageNet数据集,IN–>IN表示在IN上训练,在IN上测试。
results:
1.IN–>IN比SIN—>SIN精度更高;
2.SIN–>IN比IN—>SIN鲁棒性更好;
3.BageNet中随着接收域的减少,对于SIN–>SIN比IN—>IN的影响更大;
4.如上图,红/橙/黑色分别表示为人/基于SIN/基于IN训练后网络的判别结果;可以看到基于SIN训练后的网络的判别结果,即黄色相比于黑色明显更依赖于形状判别。
4.基于形状表征判别的CNNs的鲁棒性及准确度
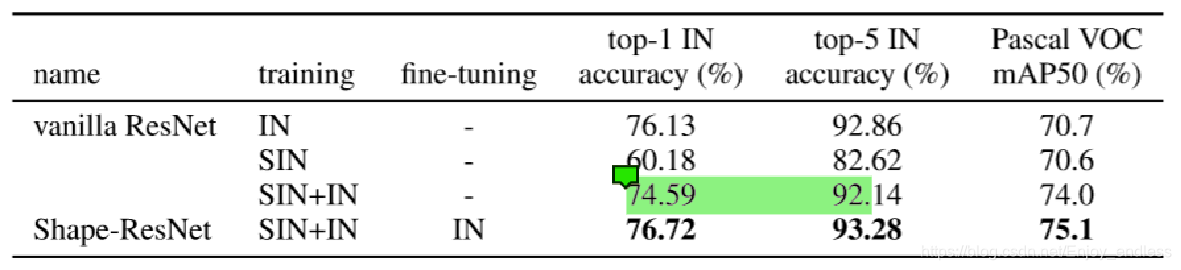
datasets: vanilla resnet、shape-resnet(SIN+IN混合训练,IN微调)
results:
1.shape-ResNet的SIN+IN,对于分类及目标检测其结果都提升了,且对于检测提升更大;
2.vanilla-ResNet的SIN+IN,对于分类其acc下降了,对于检测其mAP提升了;
3.robustness against distortions
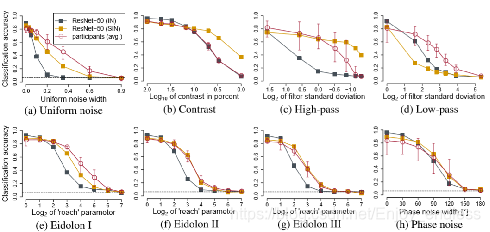
如下是对比的分别是:基于IN训练的网络(黑色)、基于SIN训练的网络(黄色)、人判别结果(红色);
对于不同的噪声及各自强度的增强,可以看到,基于SIN训练的网络相比于基于IN训练的网络,具有更强的鲁棒性。
5.总结
-
ICLR19 oral的点在哪?现有2个冲突观点的定量测试评估
实验对比设置;shape-based datasets; -
其引申出的一些价值,包括提升分类或检测性能、噪声鲁棒性、模型进一步的可解释性等














 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









