







在电商场景下需要对主商品进行审核、替换商品图背景等场景需求。就需要对商家提供的商品图进行抠图、替换背景等操作。
当然有不少的第三方工具可供运营和产品使用,但都至少需要这样几个步骤,上传图片、选择抠图区域或边缘、等待抠图生成、下载抠图结果。
且先不管商品图片涉及泄漏的问题,单是抠图效果如何也不是很好保证的。比如有这样一个商品图,我们希望抠出手机这个主商品,去掉背景色和背景物。

期望得到的理想效果是这样:[这也是通过我们算法抠图后得到的一个效果图]

比如这个抠图软件remove.bg,它抠完后的效果是这样的。基本不能准确识别出商品,而且毛边也比较严重。需要人工再点恢复来修正它。这样一张图片的抠图成本不降反增了。
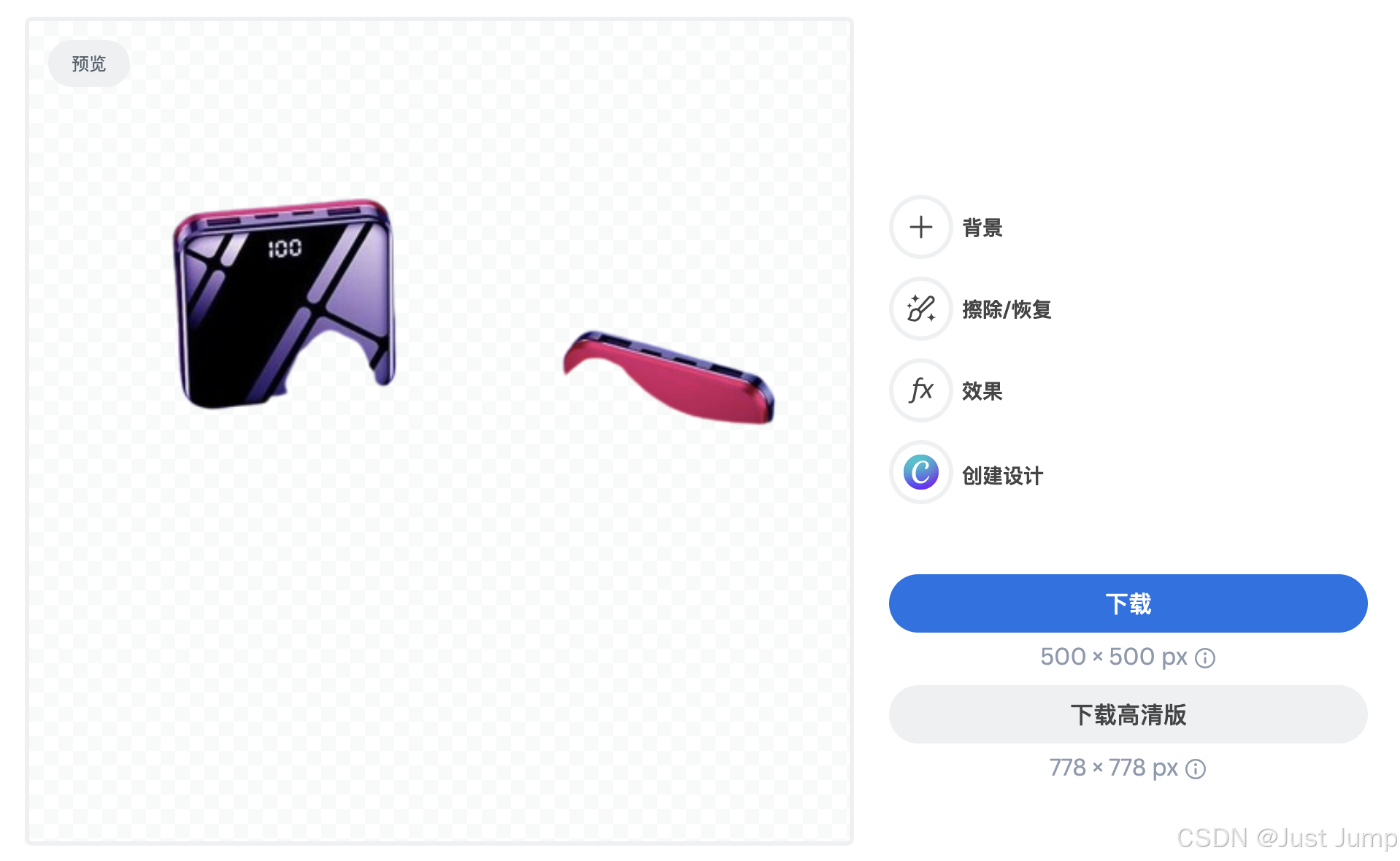
我们做这样一个项目的初衷就是为了给运营和产品同学降本提效的,所以,对算法抠图后的效果评价比较严格,不仅仅是识别商品的准确率、还要求抠图后的毛边、分辨率等不能太差。即要求商品识别率、抠图准确率高到90%,运营人工抽检和返工率不超过10%。这样才能大幅提高运营的人工效果,降低抠图的人工成本,真正达到降本增效的目的。
这个项目里主要用的就是 GroundDINO + SAM: segment Anything
https://github.com/IDEA-Research/Grounded-Segment-Anything
https://github.com/facebookresearch/segment-anything
实现步骤:
加载包和基本方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time: 2023/10/27 11:17 上午
# @Author: gao
# @Project : image_tagging
# @File: demo_sam
"""
抠图, 从EXCEL中获取商品URL和存放路径
"""
import pandas as pd
import numpy as np
import random
import os
import sys
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.preprocessors.image import load_image
sys.path.append('/root/git/Grounded-Segment-Anything')
import argparse
import copy
import torch
# print(torch.__version__)
import urllib.request
from IPython.display import display
from PIL import Image, ImageDraw, ImageFont
from torchvision.ops import box_convert
# Grounding DINO
import GroundingDINO.groundingdino.datasets.transforms as T
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util import box_ops
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.util.utils import clean_state_dict, \
get_phrases_from_posmap
from GroundingDINO.groundingdino.util.inference import annotate, load_image, \
predict
import supervision as sv
# segment anything
from segment_anything import build_sam, SamPredictor
import cv2
import matplotlib.pyplot as plt
# diffusers
import PIL
import requests
import torch
from io import BytesIO
from diffusers import StableDiffusionInpaintPipeline
from huggingface_hub import hf_hub_download
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*',
s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*',
s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(
plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0),
lw=2))
def load_model_hf(repo_id, filename, ckpt_config_filename, device='cpu'):
# cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
cache_config_file = ckpt_config_filename
args = SLConfig.fromfile(cache_config_file)
args.device = device
model = build_model(args)
# cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
checkpoint = torch.load(filename, map_location=device)
log = model.load_state_dict(clean_state_dict(checkpoint['model']),
strict=False)
print("Model loaded from {} \n => {}".format(filename, log))
_ = model.eval()
return model
def detect(image, text_prompt, model, box_threshold=0.3, text_threshold=0.25):
boxes, logits, phrases = predict(
model=model,
image=image,
caption=text_prompt,
box_threshold=box_threshold,
text_threshold=text_threshold
)
annotated_frame = annotate(image_source=image_source, boxes=boxes,
logits=logits, phrases=phrases)
annotated_frame = annotated_frame[..., ::-1] # BGR to RGB
return annotated_frame, boxes
def segment(image, sam_model, boxes):
sam_model.set_image(image)
H, W, _ = image.shape
boxes_xyxy = box_ops.box_cxcywh_to_xyxy(boxes) * torch.Tensor([W, H, W, H])
transformed_boxes = sam_model.transform.apply_boxes_torch(
boxes_xyxy.to(device), image.shape[:2])
masks, _, _ = sam_model.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
return masks.cpu()
def draw_mask(mask, image, random_color=True):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.8])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
annotated_frame_pil = Image.fromarray(image).convert("RGBA")
mask_image_pil = Image.fromarray(
(mask_image.cpu().numpy() * 255).astype(np.uint8)).convert("RGBA")
return np.array(Image.alpha_composite(annotated_frame_pil, mask_image_pil))
对商品进行抠图实现
if __name__ == '__main__':
keyword_lookup_dict = {"鞋": "shoes", "表": "watch", "手机": "cell phone", "床": "bed", "沙发": "sofa", "裤": "pants", "杯": "cup", "笔记本电脑": "laptop", "车": "car", "锅": "pot", "奶粉": "milk powder", "键盘": "keyboard", "面霜": "cream", "口红": "lipstick", "靴": "boots", "烧水壶": "Kettle", "板鞋": "sneakers", "香水": "perfume", "面膜": "Facial mask", "碗": "bowl", "内裤": "underwear", "吹风机": "hair dryer", "大衣": "coat", "桌子": "table", "剃须刀": "shaver", "音响": "Audio", "空调": "air conditioner", "吊坠": "pendant", "电饭煲": "rice cooker", "睡衣": "pajamas", "按摩仪": "Massager", "平板": "flat", "尿不湿": "Diapers", "沙发床": "sofa bed", "茶几": "coffee table", "清洗机": "washing machine", "投影仪": "projector", "拓展坞": "expansion dock", "无人机": "drone", "净饮机": "Drinking machine", "台灯": "desk lamp", "摄像头": "Camera", "抽水器": "water pump", "螺丝刀": "screwdriver", "烤箱": "oven", "牛奶": "milk", "筋膜枪": "fascia gun", "电暖器": "electric heater", "耳钉": "earrings", "压力锅": "pressure cooker", "足浴盆": "footbath", "泡脚桶": "Foot bath bucket"}
images_download_dir = "/root/notebook/gao/sam_dino/images_source"
result_save_dir = "/root/notebook/gao/sam_dino/images_result"
if not os.path.exists(images_download_dir):
os.mkdir(images_download_dir)
if not os.path.exists(result_save_dir):
os.mkdir(result_save_dir)
# 1、从EXCEL中读取商品URL和标题信息 , 这里第一行是标题header=0
sku_file = pd.read_excel(open('商品抠图列表.xlsx', 'rb'), sheet_name='Sheet1',
header=0, dtype={"sku_id": str})
n, m = sku_file.shape
# 3、sam_demo抠图
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device = 'cpu'
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "/root/git/Grounded-Segment-Anything/groundingdino_swinb_cogcoor.pth"
ckpt_config_filename = "/root/git/Grounded-Segment-Anything/GroundingDINO_SwinB.cfg.py"
groundingdino_model = load_model_hf(ckpt_repo_id, ckpt_filenmae,
ckpt_config_filename, device)
for i in np.arange(n):
line = sku_file.loc[i]
sku_id = line['sku_id']
sku_title = str(line['标题'])
img_save_name = line['输出文件名']
img_url = line['待抠图文件']
if img_save_name.endswith("png"):
"JPG转为PNG"
# 图片下载存放
img_download_path = os.path.join(images_download_dir,
img_url.split("/")[-1])
if not os.path.exists(img_download_path):
try:
urllib.request.urlretrieve(img_url, filename=img_download_path)
except:
""
else:
""
if os.path.getsize(img_download_path) == 0:
sys.stderr.write("图片URL下载失败")
prompt_list = []
for wrd in keyword_lookup_dict.keys():
if sku_title.find(wrd) != -1:
prompt_list.append(keyword_lookup_dict[wrd])
else:
continue
if len(prompt_list) < 2:
prompt_list.append('item.object.entity')
prompt_text = '.'.join(prompt_list)
else:
prompt_text = '.'.join(prompt_list[:10])
# 抠图图片存放
result_save_path = os.path.join(result_save_dir, img_save_name)
try:
# 开始抠图
image_source, image = load_image(img_download_path)
annotated_frame, detected_boxes = detect(image,
text_prompt=prompt_text,
model=groundingdino_model)
print("detected_boxes:\n", detected_boxes)
# ! wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
sam_checkpoint = 'sam_vit_h_4b8939.pth'
sam_predictor = SamPredictor(
build_sam(checkpoint=sam_checkpoint).to(device))
segmented_frame_masks = segment(image_source, sam_predictor,
boxes=detected_boxes)
"""
1、抠图后图片与 原图片 色差,RGBA --> BGRA
2、边缘粗糙
"""
# 抠图
image = Image.open(img_download_path) # 打开图片
img = np.array(image.convert('RGBA')) # 将图片转化为张量形式 RGBA
print("原图shape: ", img.shape)
new_img = np.zeros(img.shape, dtype='int32')
print("抠图shape:", new_img.shape)
new_img[:] = 255 # 抠图图片初始化为全白色
# id = 0
for t in np.arange(segmented_frame_masks.shape[0]):
img1 = segmented_frame_masks[t][0] # 掩码
sq = img1.shape # 掩码尺寸
height = sq[0]
width = sq[1]
for p in range(0, height):
for q in range(0, width):
if img1[p, q].numpy():
new_img[p, q] = [img[p, q][2], img[p, q][1],
img[p, q][0], img[p, q][
3]] # #遍历图片,掩码部分赋值真实图像原始值
# print("new img", new_img)
# new_img =cv2.cvtColor(new_img, cv2.COLOR_BGR2RGB) #cv2读取的bgr通道转为rbg,否则图片偏蓝
# cv2.imwrite(img_download_path.split("/")[-1].split(".")[0]+"_2_2.jpg", new_img[:,:,::-1]) # 同 new_img[...,::-1]
# new_img1 = cv2.cvtColor(new_img, cv2.COLOR_RGBA2BGRA)
cv2.imwrite(result_save_path, new_img)
# print(id)
except:
""抠图效果展示:
商品提示词:手机

遗留问题:
当然算法虽然实现了大部分商品的抠图准确率,但毛边问题还是有的,需要加光滑函数来解决。商品识别的准确率也是依赖于提示词的,需要准备大量准确的提示词。
Done

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









