









开篇之前做一些说明。
最近技术咨询实在太多,真心感谢大伙儿的信任!但说实话,我现在有点扛不住了。很多兄弟连win的使用一些问题都@我,其实用深度求索(deepseek)、Kimi这些工具分分钟就能解决,比我手动回复快多了——不信你们试试,这俩工具处理技术文档比人靠谱。
当初想着能帮就帮,结果现在业余时间全被咨询占满,连内容更新都耽误了。可能你们觉得问个问题就几分钟,但我每天面对的是n个。所以以后不回消息不是看不起你们,实在是精力有限。我需要更多的时间去学习,去实践来保持稳定的更新。
最近ragflow和dify都在疯狂的更新,每家产品更新后都带出来一堆bug。dify的1.0.0一堆bug,到1.0.1解决了一部分。ragflow也是一样。最近也是疯狂的更新。我们看下官方的更新日志。
升级日志
v0.17.2(2025-03-13)
- 解决了 0.17.1 引入的,无法添加 Ollama / Xinference 部署模型的错误
- 提供 OpenAI 兼容的 API
- 支持德文用户界面
- 加速知识图谱的生成速度
- 允许用户在 Agent Retrieval 组件使用 Tavily 搜索
- 新增通义千问 QwQ 模型
- General 文档解析方法支持 CSV 文件格式
v0.17.1(2025-03-11)
- 解决 Knowledge graph 信息重复抽取的问题
- 改善特定情况下,英文分词质量不高的问题
- 解决了一系列 API 调用的问题
- 解决了在知识库配置页中 Document parser 不可见问题
- 改善了文档解析任务的并行性能
- 解决了图片类文件的预览问题
- 支持解析 XLS (excel97~2003) ,并改善了错误处理机制
- 解决了 Tavily 搜索的错误支持 Huggingface 重排序模型
- Agent 中的 Rewrite 算子支持相对时间表达
- 更新了硅基流动的模型列表
- 解析 Markdown 文档类型时,优化了其中的表格内容提取逻辑
v0.17.0(2025-03-03)
- 支持 Agentic Reasoning,实现 Deep Research
- 依托 Tavily 支持在对话中引入联网搜索,并支持在 Reasoning 过程中调用,补充推理的上下文信息
- 更新了阿里云模型支持列表,支持 DeepSeek; 新增模搭社区作为模型提供商
- 支持采用 Naive 和 大模型解析文档 (实验阶段)
- 支持阿里云 OSS 作为文件存储
- 支持不设置知识库,直接和大模型进行对话
- 允许通过 API 来更新文档元数据
- 支持对 HTML 文件的预览
- 优化了在 Agent 算子(component)中通过 prompt 引用变量的方式,支持通过 / 展示、选择可用变量。
升级解读
在v0.17.0中,比较重要的更新的点。
- 实现
Deep Research,官方发文,重点介绍这个 - 创建的chat,不再必须依赖知识库了
- 前端交互中对生成html的预览
- 通过/选取可用变量,但是比较鸡肋,因为除了在大模型里,其他的组件里,你也不知道怎么用
在v0.17.1中的重点
- 解决了Knowledge graph 信息重复抽取的问题,在之前抽取一个知识图谱特别特别特别慢
- 解决了交互中token超长的问题,超过设置的大模型的最大tokens
导致无法添加ollama和Xinference部署的模型的bug
在v0.17.2中
- 重点是解决v0.17.1的bug
- 加速知识图谱的生成速度
- 分段中支持CSV文件解析的格式
我比较看中的知识图谱的升级。具体升级以后速度提升多少,我等下实验告诉你们。
ragflow中知识图谱介绍
在ragflow的官方中,关于知识图谱,主要有两个文档,
https://ragflow.io/blog/ragflow-support-graphrag
主要内容
- 从0.9.0开始引入
- 依赖于大模型和专有数据库
infinity - 主要增强
多跳问答和跨文档查询
https://ragflow.io/docs/dev/construct_knowledge_graph
主要内容:
- 从v0.16.0版本开始,RAGFlow支持在知识库上构建知识图谱
- 文档中的流程图不再依赖
infinity
想深读了解的,可以看看
https://github.com/microsoft/graphrag
https://arxiv.org/abs/2402.19472
知识图谱适用场景
看官方的解释:知识图谱对于涉及嵌套逻辑的多跳问答特别有用。在对包含复杂实体和关系的书籍或作品进行问答时,它们的表现优于传统的提取方法。
知识图谱的配置

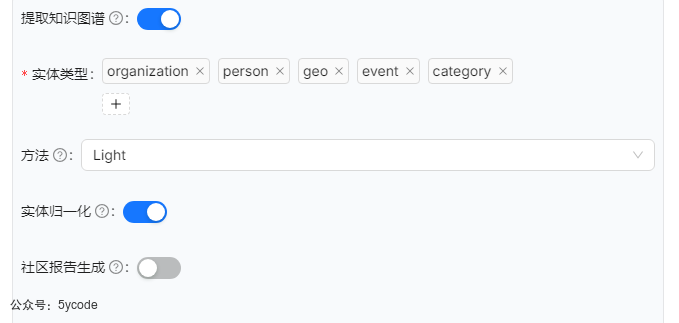
- 首先要开启知识图谱
实体类型
知识图谱中的实体类型是对现实世界或抽象概念中各类对象的分类和抽象,是构建结构化知识的基础。我们看下ragflow提供的几类实体,我们也可以添加其他的。最后由大模型去整理。
- Organization(组织)
- 由人组成的团体或机构
- 包括:企业、机构、政府等。
- 如:“腾讯”、“卫生部”
- Person(人物):
- 真实或虚构的个体
- 包括:真实人物、虚构人物、职业分类
- 如:爱因斯坦、哪吒、科学家
- Geo(地理):
- 物理或人文空间位置
- 包括:自然地理、人文地理、行政区划
- 如:喜马拉雅山、中国、长三角地区
- Event(事件)
- 特定时空发生的活动或现象
- 包括:历史事件、社会活动、自然事件
- 如:工业革命、奥运会、汶川地震
- Category(类别):如产品、技术、学科等。例如,“人工智能”、“量子力学”。
- 抽象或具体的分类集合
- 包括:产品与作品、抽象概念、科技术语、生物实体、金融实体、法律实体
- 如:iPhone16、可持续发展、DeepSeek、大熊猫、比特币、民法典
方法
ragflow提供两种方法可以选择。
- Light:实体和关系提取提示来自 GitHub - HKUDS/LightRAG:“LightRAG:简单快速的检索增强生成”
- General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于图的模块化检索增强生成 (RAG) 系统
一般我们使用Light即可。
实体归一化
实体归一化是将文本中提及的 不同形式、别名或歧义实体 映射到知识库中 唯一标准实体 的过程。其核心目标是消除表述差异,确保同一实体在不同数据源或上下文中被统一标识。
ragflow在解析过程会将具有相同含义的实体合并在一起,从而使知识图谱更简洁、更准确。应合并以下实体:特朗普总统、唐纳德·特朗普、唐纳德·J·特朗普、唐纳德·约翰·特朗普。
有以下几种技术实现
| 模块 | 技术方案 | 示例场景 |
|---|---|---|
| 同义词归并 | 构建别名词典(Alias Dictionary)+ 模糊匹配 | “Jack Ma” → 马云(实体ID: E123) |
| 歧义消解 | 基于上下文的BERT语义匹配 + 知识图谱属性验证 | “苹果” → 公司(Q312) / 水果(Q89) |
| 跨语言对齐 | 多语言嵌入模型(mBERT) + Wikidata跨语言链接 | “New York” → 纽约市(Q60) |
| 动态更新 | 实时监控新实体,通过众包反馈机制更新归一化规则 | 新增"ChatGPT" → GPT-4(Q1209) |
知识图谱生成测试
由于知识图谱的构建需要LLM,不需要太强的推理能力,我使用了qwen-plus在线模型。
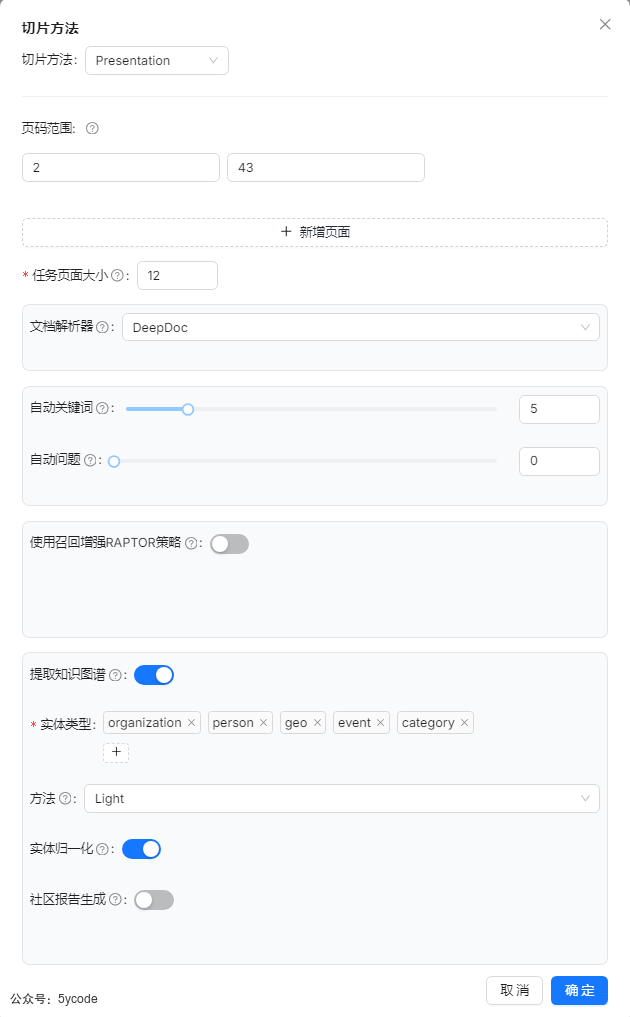
采用统一切片方法。
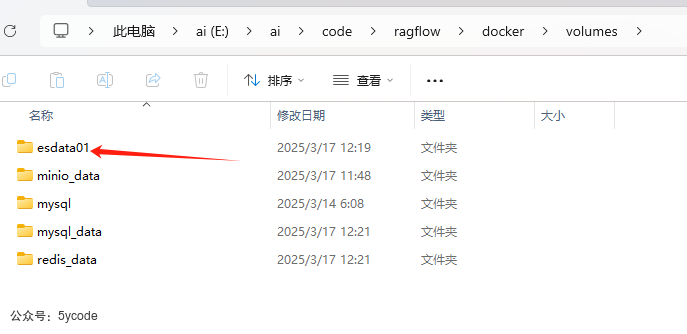
每次操作流程
- 删除知识库
- 执行
docker compose down - 删除
esdata01文件夹 - 执行
docker compose up -d - 新建知识库
- 上传《天津大学 深度解读DeepSeek原理与效应》
- 设置切片方法
- 应用
构建出来的知识图谱
v0.17.0 知识图谱测试
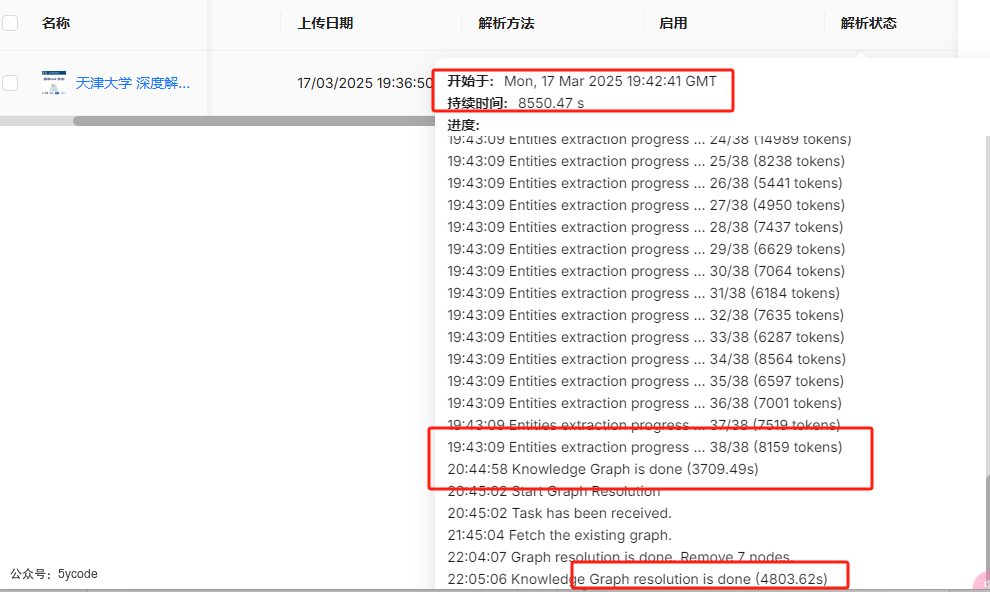
- 在v0.17.0中,知识图谱的构建,花费了8550秒,测试了几次最少花费是7200多秒,得凌晨用的人少的时候
- 看这个日志,构建花费了3707秒,后面又去
resolution花费了4800秒
v0.17.1 知识图谱测试
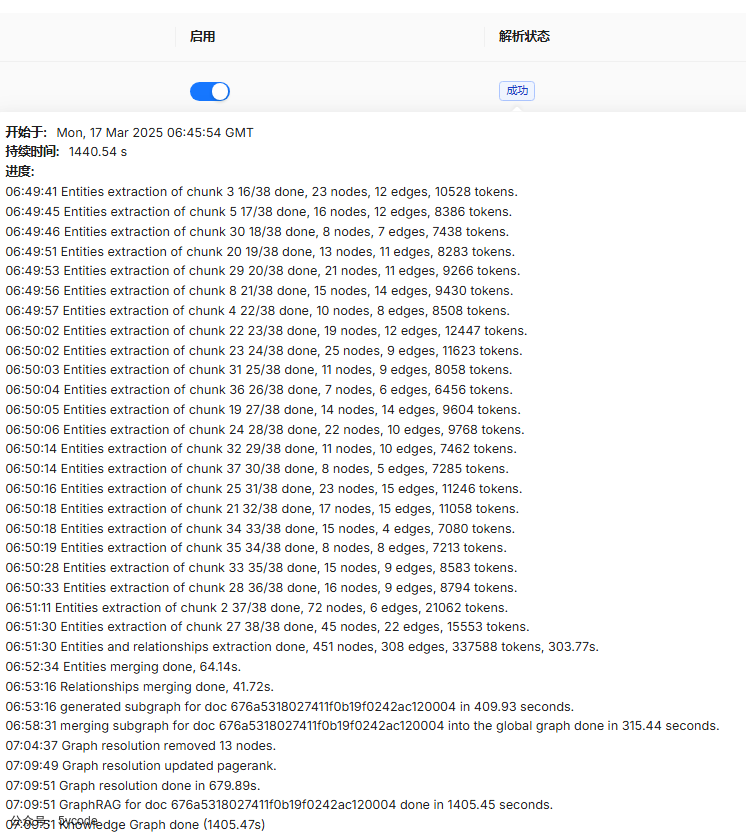
- 到v0.17.1的时候,整体花费1440秒
- 根据日志看到,先根据文档构建了子知识图谱,然后又合并到global 知识图谱
v0.17.2知识图谱测试
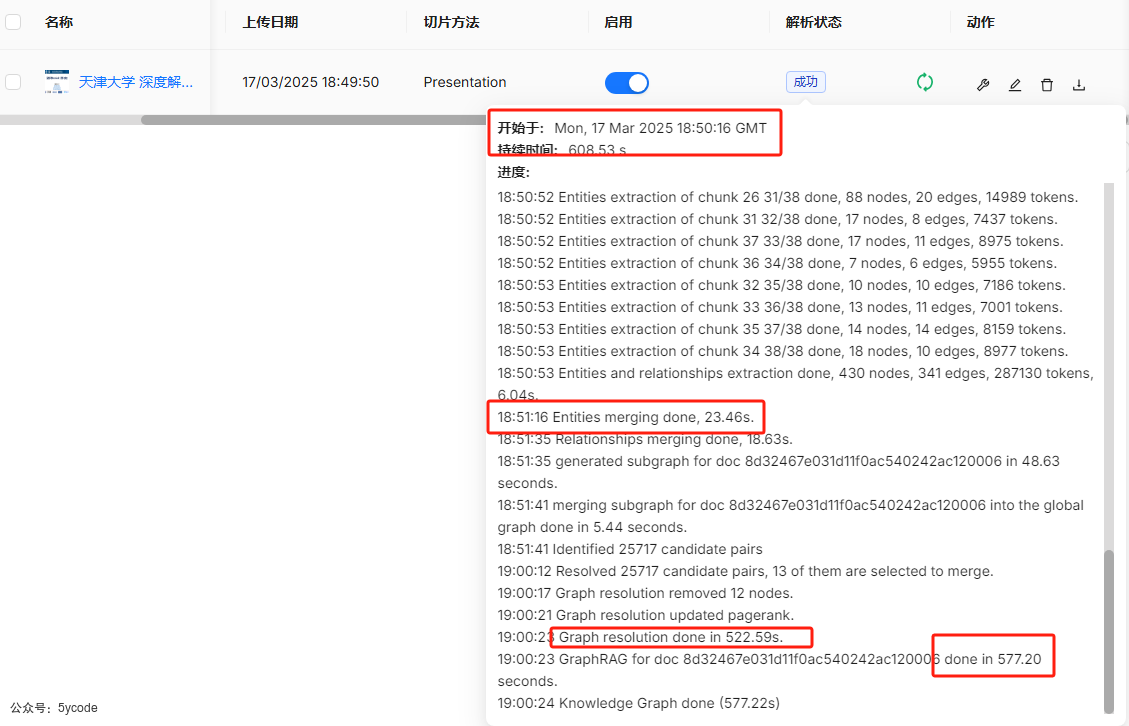
- 到了v0.17.2中,整体构建花费了608秒,偶尔构建到700秒
我们可以看到只是前面的解析+关键词构建,花费时间很短的,大头都在知识图谱的构建。
总结
我们看下耗时对比。
| 版本 | 构建耗时 | 降幅 |
|---|---|---|
| v0.17.0 | 8550秒 | - |
| v0.17.1 | 1440秒 | 83%↓ |
| v0.17.2 | 608秒 | 58%↓ |
| |
- 我们可以看到知识图谱的构建是非常花费时间和tokens的
- 一般情况下,关键词+向量检索就够了,非必要不构建知识图谱
我让deepseek整理下使用知识图谱的条件
if 文档满足以下任意条件:
1. 含超过50个实体互连
2. 需处理NLP时间表达式(如"三个月前"→2024-03-01)
3. 查询含2层以上逻辑嵌套
4. 涉及跨表/跨文档关系验证
then 启用知识图谱
else 使用传统检索
其他
ragflow文件上传限制解决。我不知道什么时候把文件上传限制到了10mb,修改限制也很简单。
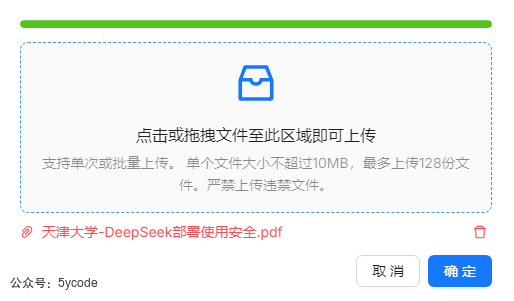
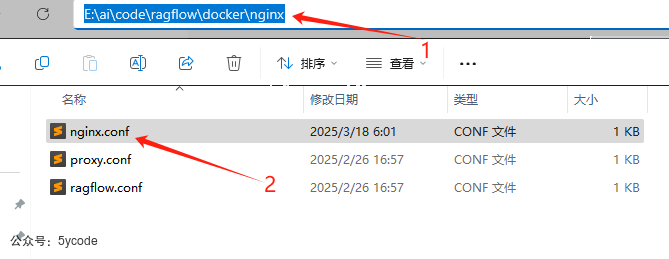
- 打开ragflow的docker目录的nginx文件夹
- 打开
nginx.conf文件
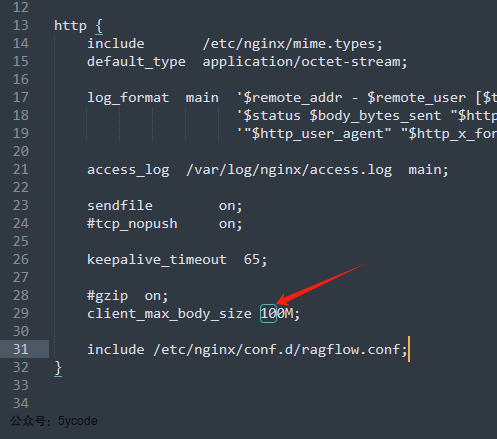
- 修改对应的
client_max_body_size限制。 - 执行
docker compose down - 执行
docker compose up -d
相关资料
deepseek相关资料,包含内容如下
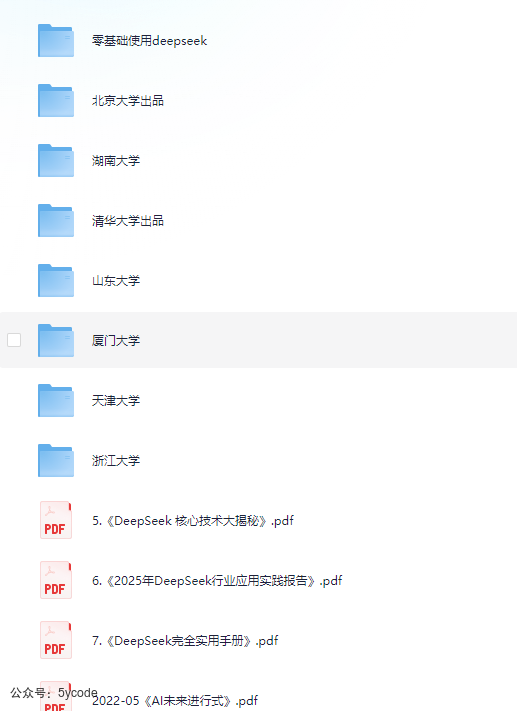
https://pan.quark.cn/s/faa9d30fc2bd
https://pan.baidu.com/s/10vnv9jJJCG-KKY8f_e-wLw?pwd=jxxv
系列文档:
DeepSeek本地部署相关
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
dify相关
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
模型微调相关
📢【三连好运 福利拉满】📢
🌟 若本日推送有收获:
👍 点赞 → 小手一抖,bug没有
📌 在看 → 一点扩散,知识璀璨
📥 收藏 → 代码永驻,防止迷路
📤 分享 → 传递战友,功德+999
🔔 关注 → 关注5ycode,追更不迷路,干货永同步
💬 若有槽点想输出:
👉 评论区已铺好红毯,等你来战!


















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









