







https://en.wikipedia.org/wiki/Kalman_filter
Underlying dynamic system model[edit]
| This section requires expansion. (August 2011) |
The Kalman filters are based on linear dynamic systems discretized in the time domain. They are modelled on a Markov chain built on linear operators perturbed by errors that may include Gaussian noise. The state of the system is represented as a vector of real numbers. At each discrete time increment, a linear operator is applied to the state to generate the new state, with some noise mixed in, and optionally some information from the controls on the system if they are known. Then, another linear operator mixed with more noise generates the observed outputs from the true ("hidden") state. The Kalman filter may be regarded as analogous to the hidden Markov model, with the key difference that the hidden state variables take values in a continuous space (as opposed to a discrete state space as in the hidden Markov model). There is a strong duality between the equations of the Kalman Filter and those of the hidden Markov model. A review of this and other models is given in Roweis and Ghahramani (1999)[11] and Hamilton (1994), Chapter 13.[12]
In order to use the Kalman filter to estimate the internal state of a process given only a sequence of noisy observations, one must model the process in accordance with the framework of the Kalman filter. This means specifying the following matrices: Fk, the state-transition model; Hk, the observation model; Qk, the covariance of the process noise; Rk, the covariance of the observation noise; and sometimes Bk, the control-input model, for each time-step, k, as described below.

The Kalman filter model assumes the true state at time k is evolved from the state at (k − 1) according to
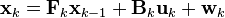
where
- Fk is the state transition model which is applied to the previous state xk−1;
- Bk is the control-input model which is applied to the control vector uk;
- wk is the process noise which is assumed to be drawn from a zero mean multivariate normal distribution with covariance Qk.

At time k an observation (or measurement) zk of the true state xk is made according to
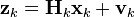
where Hk is the observation model which maps the true state space into the observed space and vk is the observation noise which is assumed to be zero mean Gaussian white noise with covariance Rk.

The initial state, and the noise vectors at each step {x0, w1, …, wk, v1 … vk} are all assumed to be mutually independent.
Many real dynamical systems do not exactly fit this model. In fact, unmodelled dynamics can seriously degrade the filter performance, even when it was supposed to work with unknown stochastic signals as inputs. The reason for this is that the effect of unmodelled dynamics depends on the input, and, therefore, can bring the estimation algorithm to instability (it diverges). On the other hand, independent white noise signals will not make the algorithm diverge. The problem of separating between measurement noise and unmodelled dynamics is a difficult one and is treated in control theory under the framework of robust control.[13][14]
Details[edit]
The Kalman filter is a recursive estimator. This means that only the estimated state from the previous time step and the current measurement are needed to compute the estimate for the current state. In contrast to batch estimation techniques, no history of observations and/or estimates is required. In what follows, the notation  represents the estimate of
represents the estimate of 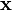 at time n given observations up to, and including at time m ≤ n.
at time n given observations up to, and including at time m ≤ n.
The state of the filter is represented by two variables:
 , the a posteriori state estimate at time k given observations up to and including at time k;
, the a posteriori state estimate at time k given observations up to and including at time k;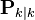 , the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
, the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
The Kalman filter can be written as a single equation, however it is most often conceptualized as two distinct phases: "Predict" and "Update". The predict phase uses the state estimate from the previous timestep to produce an estimate of the state at the current timestep. This predicted state estimate is also known as the a priori state estimate because, although it is an estimate of the state at the current timestep, it does not include observation information from the current timestep. In the update phase, the current a priori prediction is combined with current observation information to refine the state estimate. This improved estimate is termed the a posteriori state estimate.
Typically, the two phases alternate, with the prediction advancing the state until the next scheduled observation, and the update incorporating the observation. However, this is not necessary; if an observation is unavailable for some reason, the update may be skipped and multiple prediction steps performed. Likewise, if multiple independent observations are available at the same time, multiple update steps may be performed (typically with different observation matrices Hk).[15][16]
Predict[edit]
| Predicted (a priori) state estimate |  |
| Predicted (a priori) estimate covariance |  |
Update[edit]
| Innovation or measurement residual |  |
| Innovation (or residual) covariance | 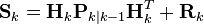 |
| Optimal Kalman gain | 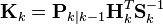 |
| Updated (a posteriori) state estimate | 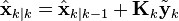 |
| Updated (a posteriori) estimate covariance | 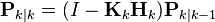 |
The formula for the updated estimate covariance above is only valid for the optimal Kalman gain. Usage of other gain values require a more complex formula found in the derivations section.
Invariants[edit]
If the model is accurate, and the values for 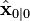 and
and 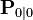 accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
![\mathbf{E}[\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k}] = \textrm{E}[\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k-1}] = 0](https://upload.wikimedia.org/math/e/f/8/ef8ed0b123b3b4c079ec49bbe54af318.png)
![\textrm{E}[\tilde{\mathbf{y}}_k] = 0](https://upload.wikimedia.org/math/d/0/a/d0a795fa05ba338eccafdb8d326af328.png)
where ![\textrm{E}[\xi]](https://upload.wikimedia.org/math/6/2/2/622bdf3feac7f49bbef4950f48b8fd45.png) is the expected value of
is the expected value of 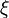 , and covariance matrices accurately reflect the covariance of estimates
, and covariance matrices accurately reflect the covariance of estimates

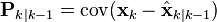

Optimality and performance[edit]
It follows from theory that the Kalman filter is optimal in cases where a) the model perfectly matches the real system, b) the entering noise is white and c) the covariances of the noise are exactly known. Several methods for the noise covariance estimation have been proposed during past decades, including ALS, mentioned in the previous paragraph. After the covariances are estimated, it is useful to evaluate the performance of the filter, i.e. whether it is possible to improve the state estimation quality. If the Kalman filter works optimally, the innovation sequence (the output prediction error) is a white noise, therefore the whiteness property of the innovations measures filter performance. Several different methods can be used for this purpose.[17]
Example application, technical[edit]

Consider a truck on frictionless, straight rails. Initially the truck is stationary at position 0, but it is buffeted this way and that by random uncontrolled forces. We measure the position of the truck every Δt seconds, but these measurements are imprecise; we want to maintain a model of where the truck is and what its velocity is. We show here how we derive the model from which we create our Kalman filter.
Since  are constant, their time indices are dropped.
are constant, their time indices are dropped.
The position and velocity of the truck are described by the linear state space
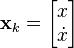
where  is the velocity, that is, the derivative of position with respect to time.
is the velocity, that is, the derivative of position with respect to time.
We assume that between the (k − 1) and k timestep uncontrolled forces cause a constant acceleration of ak that is normally distributed, with mean 0 and standard deviation σa. From Newton's laws of motion we conclude that
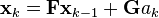
(note that there is no 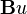 term since we have no known control inputs. Instead, we assume that ak is the effect of an unknown input and
term since we have no known control inputs. Instead, we assume that ak is the effect of an unknown input and  applies that effect to the state vector) where
applies that effect to the state vector) where

and
![\mathbf{G} = \begin{bmatrix} \frac{\Delta t^2}{2} \\[6pt] \Delta t \end{bmatrix}](https://upload.wikimedia.org/math/9/2/d/92d88df42ed15b0c57511f39ff1fb258.png)
so that

where  and
and
![\mathbf{Q}=\mathbf{G}\mathbf{G}^{\text{T}}\sigma_a^2 =\begin{bmatrix} \frac{\Delta t^4}{4} & \frac{\Delta t^3}{2} \\[6pt] \frac{\Delta t^3}{2} & \Delta t^2 \end{bmatrix}\sigma_a^2.](https://upload.wikimedia.org/math/a/1/8/a189db8d8f2fca5065335d7bf92b0563.png)
At each time step, a noisy measurement of the true position of the truck is made. Let us suppose the measurement noise vk is also normally distributed, with mean 0 and standard deviation σz.

where

and
![\mathbf{R} = \textrm{E}[\mathbf{v}_k \mathbf{v}_k^{\text{T}}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](https://upload.wikimedia.org/math/a/3/0/a308c849eb4941a4702e8587fdd0da3b.png)
We know the initial starting state of the truck with perfect precision, so we initialize
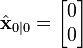
and to tell the filter that we know the exact position and velocity, we give it a zero covariance matrix:

If the initial position and velocity are not known perfectly the covariance matrix should be initialized with a suitably large number, say L, on its diagonal.
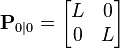
The filter will then prefer the information from the first measurements over the information already in the model.
Derivations[edit]
|
| This section needs additional citations for verification. (December 2010) |
Deriving the a posteriori estimate covariance matrix[edit]
Starting with our invariant on the error covariance Pk | k as above

substitute in the definition of

and substitute 
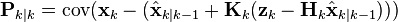
and 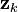
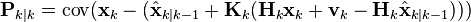
and by collecting the error vectors we get
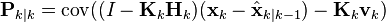
Since the measurement error vk is uncorrelated with the other terms, this becomes
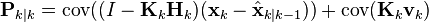
by the properties of vector covariance this becomes
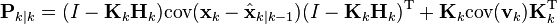
which, using our invariant on Pk | k−1 and the definition of Rk becomes

This formula (sometimes known as the "Joseph form" of the covariance update equation) is valid for any value of Kk. It turns out that if Kk is the optimal Kalman gain, this can be simplified further as shown below.
Kalman gain derivation[edit]
The Kalman filter is a minimum mean-square error estimator. The error in the a posteriori state estimation is

We seek to minimize the expected value of the square of the magnitude of this vector, ![\textrm{E}[\|\mathbf{x}_{k} - \hat{\mathbf{x}}_{k|k}\|^2]](https://upload.wikimedia.org/math/4/e/8/4e871ab0558b92db060be2895c1ccbc3.png) . This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix
. This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix 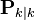 . By expanding out the terms in the equation above and collecting, we get:
. By expanding out the terms in the equation above and collecting, we get:
![\begin{align}
\mathbf{P}_{k\mid k} & = \mathbf{P}_{k\mid k-1} - \mathbf{K}_k \mathbf{H}_k \mathbf{P}_{k\mid k-1} - \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} \mathbf{K}_k^\text{T} + \mathbf{K}_k (\mathbf{H}_k \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} + \mathbf{R}_k) \mathbf{K}_k^\text{T} \\[6pt]
& = \mathbf{P}_{k\mid k-1} - \mathbf{K}_k \mathbf{H}_k \mathbf{P}_{k\mid k-1} - \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} \mathbf{K}_k^\text{T} + \mathbf{K}_k \mathbf{S}_k\mathbf{K}_k^\text{T}
\end{align}](https://upload.wikimedia.org/math/f/4/d/f4d91b9bbe31ce2392b2a4489b4bd7e2.png)
The trace is minimized when its matrix derivative with respect to the gain matrix is zero. Using the gradient matrix rules and the symmetry of the matrices involved we find that

Solving this for Kk yields the Kalman gain:


This gain, which is known as the optimal Kalman gain, is the one that yields MMSE estimates when used.
Simplification of the a posteriori error covariance formula[edit]
The formula used to calculate the a posteriori error covariance can be simplified when the Kalman gain equals the optimal value derived above. Multiplying both sides of our Kalman gain formula on the right by SkKkT, it follows that
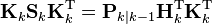
Referring back to our expanded formula for the a posteriori error covariance,

we find the last two terms cancel out, giving
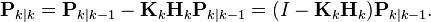
This formula is computationally cheaper and thus nearly always used in practice, but is only correct for the optimal gain. If arithmetic precision is unusually low causing problems with numerical stability, or if a non-optimal Kalman gain is deliberately used, this simplification cannot be applied; the a posteriori error covariance formula as derived above (Joseph form) must be used.















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









