







前情回顾
什么是神经网络
进行了环境的配置和实现了一个神经网络简单的搭建。用代码写出了一个只有输入层和输出层的神经网络框架。在搭建这个框架的时候,我们知道了什么是神经网络,为什么神经网络的框架是这个样子的。在框架的每一层里都有一些什么东西。神经网络就是模仿大脑神经系统的一个模型,每一个神经元对应着模型的每一层。每一层都有着输入和输出,他们之间用激活函数联系在一起。激活函数里面又有两个参数—w和b,对数据的输出进行一个控制。通过对这个模型的编程化,我们用pyhon进行了实现。
数据集
现在已经把这个框架给搭建好了,那么现在就是要把数据给输入到里面去。由于我们现在是入门,进行的是一个基本学习,所以我们直接使用别人的数据就可以了。我们初步认识了MNIST手写识别数据集,并用代码从这个数据集里获取数据,用获取的数据进行了一个简单的展示,并没有对数据进行处理。我们还知道了什么三个静态数据集—训练集、验证集、测试集。
知识补充
现在是第三天,今天我们学习的是第三个视频。传送门
今天我们要解决的问题是怎么通过调整参数来减小误差。我们现在已经可以测试数据了,如果测试出来的结果不符合我们的要求,算出来的误差很大怎么办?这时候就要对激活函数里的参数进行一个调整了。这个调整的过程,在神经网络里面,我们叫做训练。
第一步,我们要知道这个误差是怎么算出来的。在神经网络里面,我们是通过损失函数(loss function)来计算误差,在这里我们使用简单的函数进行计算—平方损失函数。就是用测试出来的数据与正确数据之差的平方之和。如图所示:
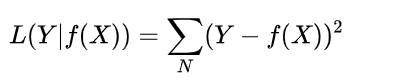
那么为什么要用这个函数呢?因为公式较为简单,对两个数据作差再平方,最后把总的结果加起来就可以了。平方的原因是作差出来的结果不管是正数还是负数,最后都是正数,也就是误差都是偏大的,便于计算。
第二步,现在我们已经知道了误差结果都是偏大的,那么怎样减小误差,即调整参数。我们要用梯度下降法,对这个参数进行调整。这里我们用到的是高数里的知识了,在这里我尽量讲的通俗易懂一点。
先看只有一个参数的,我们就拿速度这个概念举例子吧。速度=路程/时间。这一个物理公式相信大家都知道。现在我们加一点数学知识放在里面。速度是路程对时间进行求导出来的结果,求导相信大家都会求,最多就是忘记了公式。转换到二维平面坐标轴:路程-时间上看,速度是表示路程在某一时间点的斜率。通过这个斜率,我们知道速度是快还是慢。如果快了,我们可以慢一点,如果慢了,我们就可以快一点。
基本公式如图所示:

再看有两个参数的,跟上面同理,无非是二维平面换成了三维空间。因为这里有两个参数,所以我们在这里要求的是偏导。也就是把其中一个要求的参数看成参数,另外一个参数看作常数来进行求导即可。
现在我们来看看梯度下降,因为我们的通过平方损失函数来计算误差,所以我们的误差都是偏大的,所以我们可以将参数往其反方向移动来减小误差,这就是梯度下降。
现在知道了梯度下降的方向是多少,即向哪个方向下降。但是应该下降多少呢?这里我们用到学习率(Learning Rate)这个概念。通过学习率,可以计算下降的距离。
我们用 Wi表示权重的初始值, Wi+1 表示更新后的权重值,用α表示学习率,则有:
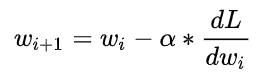
在梯度下降中,我们会重复式子多次,直至损失函数值收敛不变。
如果学习率α设置得过大,有可能我们会错过损失函数的最小值;如果设置得过小,可能我们要迭代式子非常多次才能找到最小值,会耗费较多的时间。因此,在实际应用中,我们需要为学习率 α设置一个合适的值。
以上就是梯度下降的全部内容了。
推导过程
推导过程并不难,就是对复合函数求偏导,用链式法则就可以了,那我们现在就开始吧!
数据分析
首先,我们由输入数据x,因为由28×28个输入数据,所以把x记为向量x,向量x=[x1,x2,x3,…] 向量xi表示向量x中第i个分量。由第一层激活函数A1=tanh(x),将输入数据输入到激活函数中,得第0层的输出L0=tanh(x+b0),L0指的是layer.第二层激活函数A2=softmax(x),将第0层的输出输入到A2中,得第二层的输出为output=softmax(L1),其中L1=L0·w1+b1。即output=softmax(L1)=softmax(L0×w1+b1)=softmax(tanh(x+b0)×w1+b1)。
注意,这里为了书写和计算方便,我写的都是标量,也就是只有一个数据,但是应该都写层向量和矩阵的形式,这会在后面内容中进行补充。
输出结果output是softmax函数,由这个函数的性质,我们可以知道output是一个概率,在这个案例中,就是0~9十个数字出现的概率。在Day3中说的误差就是出现在这个地方。在理想情况下,在output十个分量中,应当就只有一个数字出现的概率是1,其他数字出现的概率都是0。但是,大多数情况是十个分量都不为零,导致误差的出现。我们对数据进行作差再平方来表示这个误差,即损失函数(loss function),记L。L=(y-output)**2,两个*表示平方。出现了误差,我们就要通过调整参数来减小这个误差,对L中的三个参数b0,w1,b1分别求偏导。偏导结果用向量表示即为梯度。
我们再把L写完整写一遍。
- L=(y-output)**2
- output=softmax(L1)
- L1=L0·w1+b1
- L0=tanh(x+b0)
- L=(y-output)**2=(y-softmax(L1))**2=(y-softmax(L0·w1+b1))**2=(y-softmax((tanh(x+b0))·w1+b1))**2。
由此可见,L是一个5重复合函数。我们不要怕,要勇敢的面对。用链式法则轻轻松松,具体如下:

那我们现在就是要把每一块给求出来就可以了。(注:d_表示导数)
- L对output的偏导:-2×(y-output)
- output对L1的偏导:d_softmax(L1)
- L1对w1的偏导:L0
- L1对b1的偏导:1
- L1对L0的偏导:w1
- L0对b0的偏导:d_tanh(L0)
我们得出: - L对b0的偏导:-2×(y-output)×d_softmax(L1)×w×d_tanh(L0)
- L对b1的偏导:-2×(y-output)×d_softmax(L1)
- L对w1的偏导:-2×(y-output)×d_softmax(L1)×L0
我们现在得出了三个参数的偏导出来,但是这里算的标量,只有一个数据。现在我们就要考虑多个数据的问题,即向量求导。到了这里,你可能会疑惑,向量怎么求导啊?其实和单个数求导是一样的。如图所示:

关键是对向量tanh(x)和向量softmax(x)求偏导。
我们先看tanh(x)。
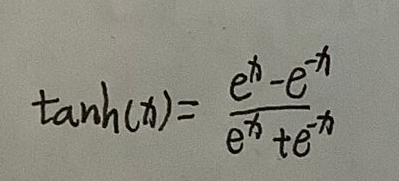
tanh(x)的导数是这个:
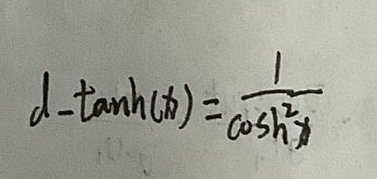
现在里面的x是向量x=[x1,x2,x3…]。求偏导结果为:

只有对角线上不为0,其余全是0。
接下来我们看softmax(x)函数。
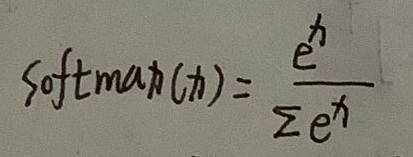
其导数是:
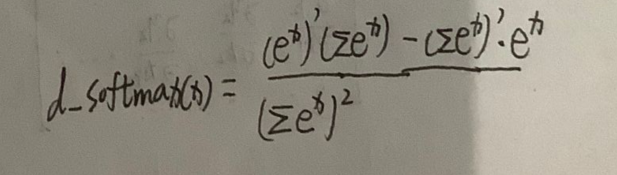
现在里面的x是向量x=[x1,x2,x3…]。求偏导结果为:

其中
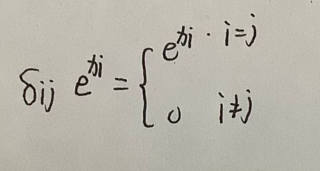
xi是表示向量x中第i个分量,softmaxj表明softmax中第j个分量。只有两个分量相同的时候,才会又偏导存在,否则为0。
明白了这些之后,计算的过程就写完了,接下就是用代码去实现就可以了。
















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











