







在学习基于goal的分层强化学习算法之前,先了解一下在goal-conditioned问题下的算法。虽然不属于分层强化学习,但这个框架能讲清楚什么是goal。
Universal Value Function Approximators
将强化学习中的值函数同时定义在状态s和目标g上,提出一种监督学习的方法将值函数分解成状态和目标的嵌入向量,从而学习到s和g到它们各自嵌入向量之间的映射问题。
Background
对于任意目标![]() ,定义伪奖励函数
,定义伪奖励函数![]() 和伪折扣函数
和伪折扣函数![]() 。伪折扣函数
。伪折扣函数![]() 有着决定每一时刻与s相关的折扣因子和决定状态是否终止的作用。
有着决定每一时刻与s相关的折扣因子和决定状态是否终止的作用。
对于任意策略![]() 和每一个目标g,状态价值函数和动作价值函数分别扩展为:
和每一个目标g,状态价值函数和动作价值函数分别扩展为:
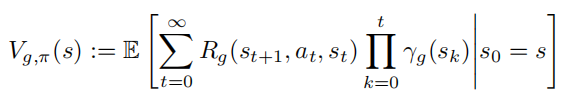
![]()
每个目标g均对应着一个最优策略![]()
![]() ,以及最优值函数
,以及最优值函数![]()
![]() 。
。
UVFA网络结构
主要思想是 用单一的、统一的函数逼近器来表示一组最优值函数,它可以概括所有的状态和目标。具体来说,就是在状态空间![]() 和目标空间
和目标空间![]() 上用
上用![]() 和
和![]() ,其中
,其中![]() 。
。
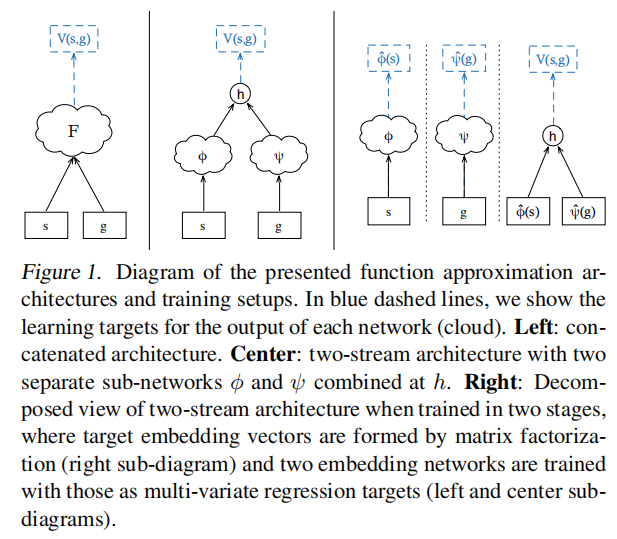
Left:Concatenated Architecture
最直接的一种方式,![]() ,将状态s和目标g连接在一起作为一个联合输入,输入到非线性函数近似器例如MLP中。
,将状态s和目标g连接在一起作为一个联合输入,输入到非线性函数近似器例如MLP中。
Center:Two-Stream Architecture
首先分别将状态s和目标g输入到两个不同的子模块中,![]() 和
和![]() ,得到状态s和目标g对应的n维嵌入向量,然后将嵌入向量同时输入到输出函数
,得到状态s和目标g对应的n维嵌入向量,然后将嵌入向量同时输入到输出函数![]() 中,得到一个标量输出。文中关注的是映射函数
中,得到一个标量输出。文中关注的是映射函数![]() 和
和![]() 都是一般函数逼近器(例如MLP),h是简单函数(例如点乘)。
都是一般函数逼近器(例如MLP),h是简单函数(例如点乘)。
Two-Stream Architecture可以很好地学习到state和goal之间的共同结构。
- 在很多情况下,goal都可以定义成state的形式/state的组合,
。因而Φ和φ之间应该有一些可以共享的feature。
- 在有些情况下,UVFA可能是对称的
Right:Decomposed View of Two-Stream Architecture
分两个阶段训练
基于监督学习的UVFA
有两种学习的方法,一种是端对端(end-to-end),一种是基于矩阵分解(matrix factorization)的两阶段(two-stage)训练。
端对端(end-to-end):通过一个合适的loss function(比如MSE )+梯度下降实现
两阶段(two-stage):
- stage1:将V*(g)放到一个矩阵中,行表示state,列表示goal。进行矩阵分解,得到
和
- stage2:将
作为ground-truth,学习Φs和φg
(也就是这个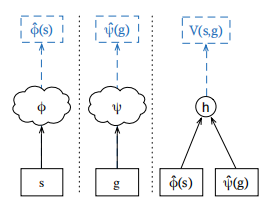 )
)
强化学习UVFA

目标的选取
没有具体说目标从哪里来以及如何表示目标,而是直接说目标是状态的子集,当状态达到目标时获得奖励。
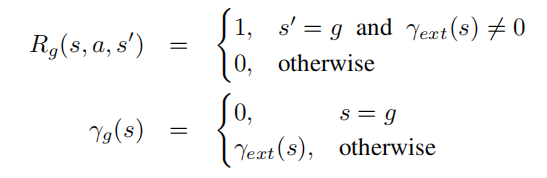
其中,![]() 是原本的折扣函数
是原本的折扣函数
Hindsight Experience Replay
这一篇文章是建立在UVFA基础之上的,hindsight是事后聪明的意思,点明了本文算法的核心思想。经验回放技术HER以UVFA中所提出的同时基于状态和目标的值函数为基础,其背后的思想是:在回放每个episode时,用一个新的目标替代原本智能体需要完成的目标,这个新的目标是本episode中实现过的目标。
在off-policy算法中,目标只会影响transition的动作,而不会影响状态之间的动态转移,因此我们可以把经验回放池中transition的原始goal替代成对应episode已经实现过的状态,奖励也就变成了完成目标所能得到的奖励,这样就能够保证回放池中总是有足够数量的正奖励样本。
本文针对的是一种特殊场景,环境中只存在稀疏的二元奖励,奖励是用来表示任务是否完成的,只有在任务完成的时候智能体才会得到奖励。稀疏奖励下模型很难得到有效的学习。为了解决稀疏奖励的问题,一种常用的做法是 reward shaping,即根据对环境的先验信息人为设计奖励,但这种方法需要我们具备对特定场景的知识,并根据这些知识精心设计奖励,另外,这些reward所表示的含义有可能与原本我们的目标是相悖的,因此并不适用于某些我们不知道合理行为是何种行为的场景中,因此研究如何从 unshaped reward 中学习策略 具有十分重要的意义,例如反映任务是否成功完成的二元奖励,这就是本文的出发点。
Multi-goal RL
本文考虑的是训练智能体实现多个不同的目标。经过实验证实,训练智能体实现多个目标比只实现一个目标要学得更快,因此HER同样适用于只有一个目标需要实现的场景。
假设每个目标![]() 对应一个预测:
对应一个预测:![]() ,智能体的目标就是找到某个状态使
,智能体的目标就是找到某个状态使![]() 。当我们明确知道我们希望达到什么样的目标时,此时有
。当我们明确知道我们希望达到什么样的目标时,此时有![]() 。当目标是状态的某些属性时(只需要达到某些特征的状态),假设
。当目标是状态的某些属性时(只需要达到某些特征的状态),假设![]() ,目标是达到任意给定x坐标的状态,此时有
,目标是达到任意给定x坐标的状态,此时有![]()
总结一下,就是![]() ,假设给定任意状态s,均可以找到该状态所能够实现的目标g。比如第一个例子里,m就是一个常数g,第二个例子里,
,假设给定任意状态s,均可以找到该状态所能够实现的目标g。比如第一个例子里,m就是一个常数g,第二个例子里,![]()
一个通用策略是使用任意off-policy算法求解,通过从某些分布中采样目标和初始状态,运行一些时间步,并在目标没有实现时在每个时间步给它一个负奖励,比如![]() 。但实践效果不好,因为奖励函数稀疏并且没有提供有效的信息,所以HER才被提出。
。但实践效果不好,因为奖励函数稀疏并且没有提供有效的信息,所以HER才被提出。
HER
HER的思想比较简单, 经过了一个episode![]() 之后,我们将每个transition
之后,我们将每个transition![]() 存储起来,每个experience里的目标不仅包含初始设定的目标,还包含一些重新设定的目标。之所以可以这么做的原因是目标只会影响智能体的动作,但是并不会影响环境的动态变化规律,因此当我们采用off-policy算法时(所学习的策略与正在执行的策略不一致),我们可以将trajectory里的目标更改为任意其他目标。
存储起来,每个experience里的目标不仅包含初始设定的目标,还包含一些重新设定的目标。之所以可以这么做的原因是目标只会影响智能体的动作,但是并不会影响环境的动态变化规律,因此当我们采用off-policy算法时(所学习的策略与正在执行的策略不一致),我们可以将trajectory里的目标更改为任意其他目标。
我们主要有4种新目标的获取方式:
- final — goal corresponding to the final state in each episode:把相应序列的最后时刻的状态作为新的目标goal
- future — replay with k random states which come from the same episode as the transition being replayed and were observed after it:从该时刻起往后的同一序列中的状态,随机采样k个作为新的目标goal
- episode — replay with k random states coming from the same episode as the transition being replayed:对于同一序列中的状态,随机采样k个作为新的目标goal
- random — replay with k random states encountered so far in the whole training procedure:从全局出现过的state中,随机选择k个作为新的目标goal。
对于第一种方式,每一条原始经验可以得到一条新的经验,而对于后三种方式,每一条原始经验可以得到k条新的经验。

图中的重点是经验池Replay Buffer的构建,而模型本身可以选择任意off-policy的强化学习模型,如DQN、DDPG等。
经验池的构造过程我们可以进行如下拆解:
(1)基于实际目标g采样完整序列
我们首先要采样M个完整的序列。对于任意一个序列,我们首先采样它的初始状态和目标状态,因为此时每个序列的目标是不同的,我们要根据不同的目标来选择动作,所以动作的采样同时基于当前的状态s和目标g。同时,基于状态s、动作a以及目标g来计算奖励r。因此保存的每一条经验可以由五部分组成:当前状态s,采取的动作a,即时奖励r,下一个状态s',当前的目标g。我们把这部分基于实际目标g采样得到的经验存放入经验池中。可以看到,这部分经验中的反馈大多都是负反馈。每一个完整的序列最多只有一条正反馈。
(2)通过变换目标得到新的经验
对于每一个序列,我们可以得到一些额外的经验,我们通过一些方法来得到一个新的目标g' 。并将(st,at,r',st+1,g')存入我们的经验池中。
有代码可以模拟:https://github.com/princewen/tensorflow_practice/tree/master/RL/Basic-HER-Demo















 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









