






注:GPT4的原理尚未公开
预训练语⾔模型具备了通⽤且强⼤的⾃然语⾔表示能⼒,能够有效地学习到词汇、语法和语义信 息。将预训练模型应⽤于下游任务时,不需要了解太多的任务细节,不需要设计特定的神经⽹络结构,只需要“微调”预训练模型,即使⽤具体任务的标注数据在预训练语⾔模型上进⾏监督训练,就 可以取得显著的性能提升。
一、GPT-1
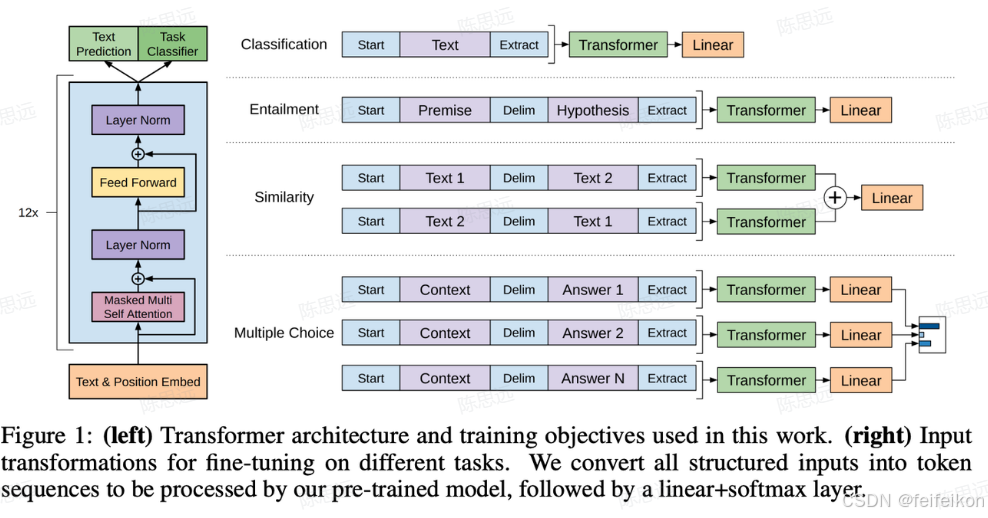
1. OpenAI公司在2018年提出的⽣成式预训练语⾔模型(Generative Pre-Training,GPT)是典型的⽣成式预训练语⾔模型之⼀。GPT模型结构如下图所示,由多层Transformer组成的单向语⾔模型,主要分为输⼊层,编码层和输出层三部分:
2. GPT采⽤⽣成式预训练⽅法,单向意味着模型只能从左到右或从右到左对⽂本序列建模,所采⽤的 Transformer结构和解码策略保证了输⼊⽂本每个位置只能依赖过去时刻的信息。
3. 给定⽂本序列w=w1w2...wn,GPT⾸先在输⼊层中将其映射为稠密的向量;经过输⼊层编码,模型得到表示向量序列v=v1...vn,随后将v送⼊模型编码层。编码层由L个Transformer模块组成,在⾃注 意⼒机制的作⽤下,每⼀层的每个表示向量都会包含之前位置表示向量的信息,使每个表示向量都 具备丰富的上下⽂信息,并且经过多层编码后,GPT能得到每个单词层次化的组合式表示:

4. GPT模型的输出层基于最后⼀层的表示h(L),预测每个位置上的条件概率,其计算过程可以表示为:
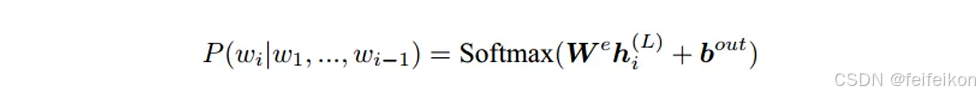 5. 单向语⾔模型是按照阅读顺序输⼊⽂本序列w,⽤常规语⾔模型⽬标优化w的最⼤似然估计,使之能 根据输⼊历史序列对当前词能做出准确的预测,预训练时通常使⽤随机梯度下降法进⾏反向传播优 化该负似然函数:
5. 单向语⾔模型是按照阅读顺序输⼊⽂本序列w,⽤常规语⾔模型⽬标优化w的最⼤似然估计,使之能 根据输⼊历史序列对当前词能做出准确的预测,预训练时通常使⽤随机梯度下降法进⾏反向传播优 化该负似然函数:
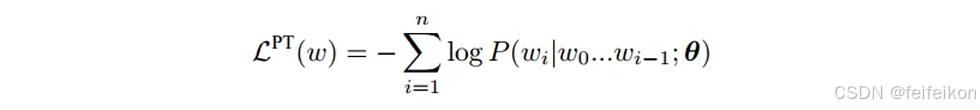
6. 有监督下游任务微调:通过⽆监督语⾔模型预训练,使得GPT模型具备了⼀定的通⽤语义表示能 ⼒。下游任务微调(Downstream Task Fine-tuning)的⽬的是在通⽤语义表示基础上,根据下游 任务的特性进⾏适配。下游任务通常需要利⽤有标注数据集进⾏训练,数据集合使⽤D进⾏表示,每个样例由输⼊⻓度为n的⽂本序列x=x1x2...xn和对应的标签y构成。

二、GPT-2
在GPT1问世不久,和GPT很相似的BERT横空出世,并且在各方面都超越GPT-1。OpenAI在《Language Models are Unsupervised Multitask Learners》中于2019年提出的GPT-2,全称为Generative Pre-Training 2.0。提出语言模型式无监督的多任务学习 ,通过无监督学习也能达到和finetune一样的效果,并且拥有更强的泛化能能力。
2.1 GPT-2提出背景
现有基于监督学习训练的模型的泛化性不是很好,在一个任务上训练好的模型也很难迁移到下一个任务上。多任务学习(Multitask learning)是指在训练一个模型时,同时看多个任务的数据集,而且可能通过多个损失函数来达到一个模式在多个任务上都能用的效果,但是在NLP领域用的不多。NLP领域主流的做法还是像GPT-1或BERT那样先在大量无标签数据上预训练语言模型,然后在每个下游任务上进行有监督的fine-tune,但是这样也有两个问题:
- 对于下游的每个任务,还是要重新训练模型
- 需要收集有标签的数据
这样导致在拓展到新任务上时还是有一定的成本。因此,GPT-2提出利用语言模型做下游任务时,不需要下游任务的任何标注信息,即zero-shot设定,也不用训练模型。因此基本实现一劳永逸,训练一个模型,在多个任务上都能用。
2.2 GPT-2简介
GPT-2继续沿用了原来在GPT中使用的单向 Transformer 模型,尽可能利用单向Transformer的优势,做一些BERT使用的双向Transformer所做不到的事。那就是通过上文生成下文文本。
GPT-2的目标是为了训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络机构进行过多的结构创新和设计,只是使用了更大的数据集和更大的网络参数。更大的数据集和更大的模型(15亿个参数),用于zero-shot(不作任何训练直接用于下游任务)效果还不错:在某些任务上和当前的模型效果差不多,但是某些任务上效果很一般。
GPT-2适用于文本生成任务,并且仍然固执地用单向语言模型,而不是双向语言模型。生成内容后续单词这种模式,单向语言模型更方便;想证明通过增加数据量和模型结构,单向模型未必输双向模型。
2.2.1 GPT-2的核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积。它的实际意义是根据已知的上文,预测未知的下文。这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。语言模型其实也是在给序列的条件概率建模。这种机制叫做自回归(auto-regression),同时也是令 RNN 模型效果拔群的重要思想。
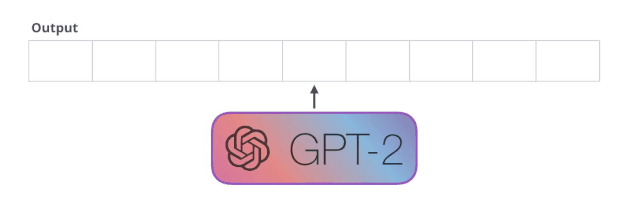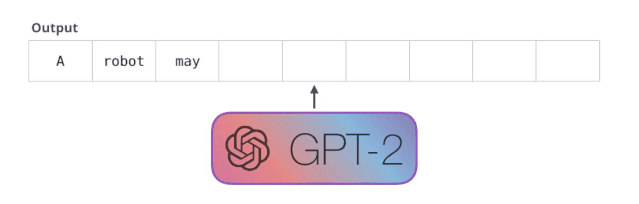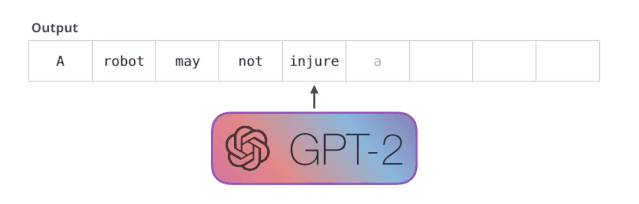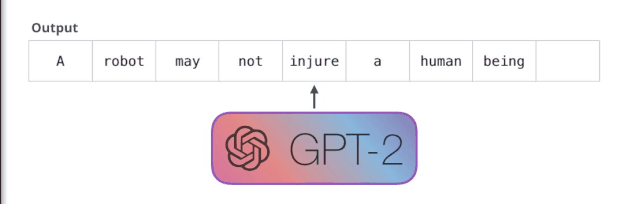
基于上面的思想,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
2.2.2 GPT-2其他知识
1.语言模型其实也是在给序列的条件概率建模,即𝑝(𝑠𝑛−𝑘,...,𝑠𝑛|𝑠1,𝑠2,...,𝑠𝑛−𝑘−1)。
2.任何有监督任务,其实都是在估计𝑝(𝑜𝑢𝑡𝑝𝑢𝑡|𝑖𝑛𝑝𝑢𝑡),通常我们会用特定的网络结构去给任务建模,但如果要做通用模型,它需要对𝑝(𝑜𝑢𝑡𝑝𝑢𝑡|𝑖𝑛𝑝𝑢𝑡,𝑡𝑎𝑠𝑘)建模。对于NLP任务的input和output,我们平常都可以用向量表示,而对于task,其实也是一样的。18年已经有研究对task进行过建模了,这种模型的一条训练样本可以表示为:(translate to french,English text,french text),或者表示为:(answer the question,document,question,answer)。已经证实了,以这种数据形式可以有监督地训练一个single model,其实也就是对一个模型进行有监督的多任务学习。
3.语言模型=无监督多任务学习。相比于有监督的多任务学习,语言模型只是不需要显示地定义哪些字段是要预测的输出,所以,实际上有监督的输出只是语言模型序列中的一个子集。举个例子,比如我在训练语言模型时,有一句话“The translation of word Machine Learning in chinese is 机器学习”,那在训练完这句话时,语言模型就自然地将翻译任务和任务的输入输出都学到了。再比如,又碰到一句话“美国的总统是特朗普”,这一句话训练完,也就是一个小的问答了。
2.2.3 GPT-2的工作流程
GPT-2 可以处理最长 1024 个单词的序列。每个单词都会和它的前续路径一起「流过」所有的解码器模块。
想要运行一个训练好的 GPT-2 模型,最简单的方法就是让它自己随机工作(从技术上说,叫做生成无条件样本)。换句话说,我们也可以给它一点提示,让它说一些关于特定主题的话(即生成交互式条件样本)。在随机情况下,我们只简单地提供一个预先定义好的起始单词(训练好的模型使用「|endoftext|」作为它的起始单词,不妨将其称为<s>),然后让它自己生成文字。
此时,模型的输入只有一个单词,所以只有这个单词的路径是活跃的。单词经过层层处理,最终得到一个向量。向量可以对于词汇表的每个单词计算一个概率(词汇表是模型能「说出」的所有单词,GPT-2 的词汇表中有 50000 个单词)。在本例中,我们选择概率最高的单词「The」作为下一个单词。
但有时这样会出问题——就像如果我们持续点击输入法推荐单词的第一个,它可能会陷入推荐同一个词的循环中,只有你点击第二或第三个推荐词,才能跳出这种循环。同样的,GPT-2 也有一个叫做「top-k」的参数,模型会从概率前 k 大的单词中抽样选取下一个单词。显然,在之前的情况下,top-k = 1。
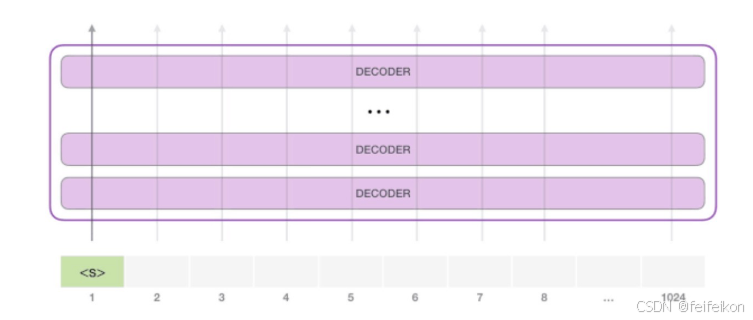
接下来,我们将输出的单词添加在输入序列的尾部构建新的输入序列,让模型进行下一步的预测:
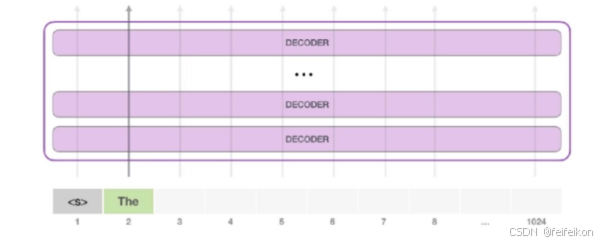
第二个单词的路径是当前唯一活跃的路径了。GPT-2 的每一层都保留了它们对第一个单词的解释,并且将运用这些信息处理第二个单词(具体将在下面一节对自注意力机制的讲解中详述),GPT-2 不会根据第二个单词重新解释第一个单词。
2.3 GPT-2的改进
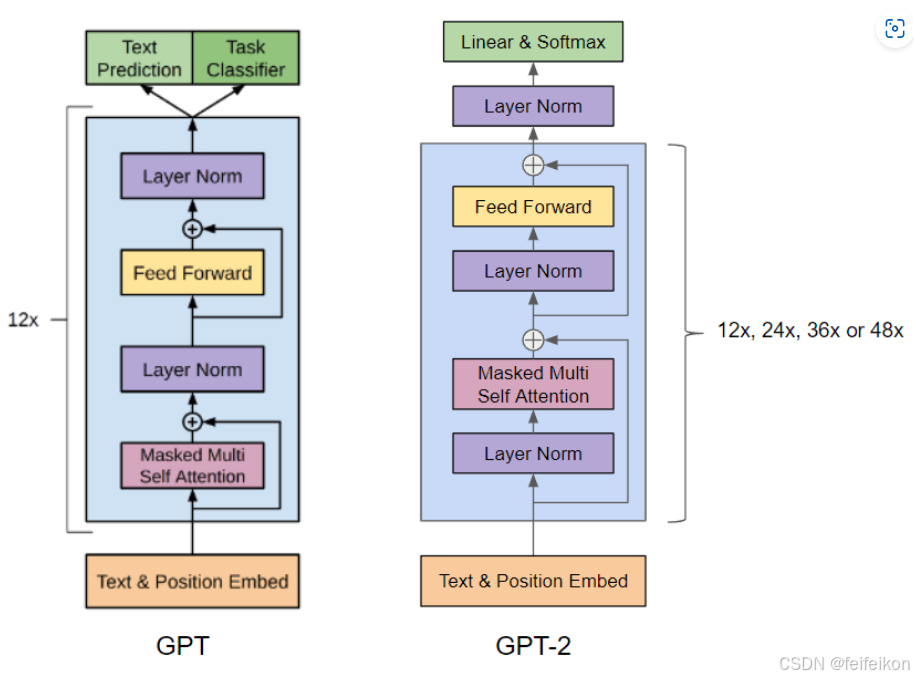
1. 去掉了fine-tuning层:只有无监督的pre-training阶段,不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。这就好比一个人博览群书,你问他什么类型的问题,他都可以顺手拈来,GPT-2就是这样一个博览群书的模型。学习的是一个通用NLP模型。
2. 增加数据集:GPT-2使用了更加广泛,数量更多的语料组成数据集。GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。这些数据是经过过滤后得到的高质量文本。GPT2需要的是带有任务信息的数据。
3. 增加网络参数:GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量达到了15亿。(5倍于BERT的参数量)。(Bert large是3.4亿)。「小号」12 层,「中号」24 层,「大号」36 层,「特大号」48 层。GPT-2训练了4组不同的层数和词向量的长度的模型。
4. 调整Transformer:将layer normalization放到每个sub-block之前,并在最后一个self-attention后再增加一个layer normalization。(防止深层网络容易出现梯度消失,影响训练稳定性)
5.增加词表:GPT-2将词汇表数量增加到50257个;最大的上下文大小从GPT-1的512提升到了1024 tokens;batch-size增加到512。
2.4 模型参数
1.同样使用了使用字节对(BPE)编码构建字典,字典的大小为50257。
2.滑动窗口的大小为1024。
3.batchsize的大小为512。
4.Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization。
5.将残差层的初始化值用进行缩放,其中N是残差层的个数。
6. GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
| 参数量 | 层数 | 词向量长度 |
|---|---|---|
| 117M(GPT-1) | 12 | 769 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
2.5 总结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间。
当一个大型语言模型被训练在一个足够大和多样的数据集上时,它能够在许多域和数据集上表现良好。在八分之七的测试语言模型数据集上,GPT-2 zero-shot 到最先进的性能。该模型能够在zero-shot setting下执行的任务的多样性表明,经过训练以使文本语料库充分变化的可能性最大化的高容量模型开始学习如何执行数量惊人的任务,而不需要明确的监督。
三、GPT-3
3.1 引言
今天来介绍下牛逼的GPT-31,它是一个拥有1750亿参数的巨大的自回归(autoregressive)语言模型。
3.2 GPT-3简介
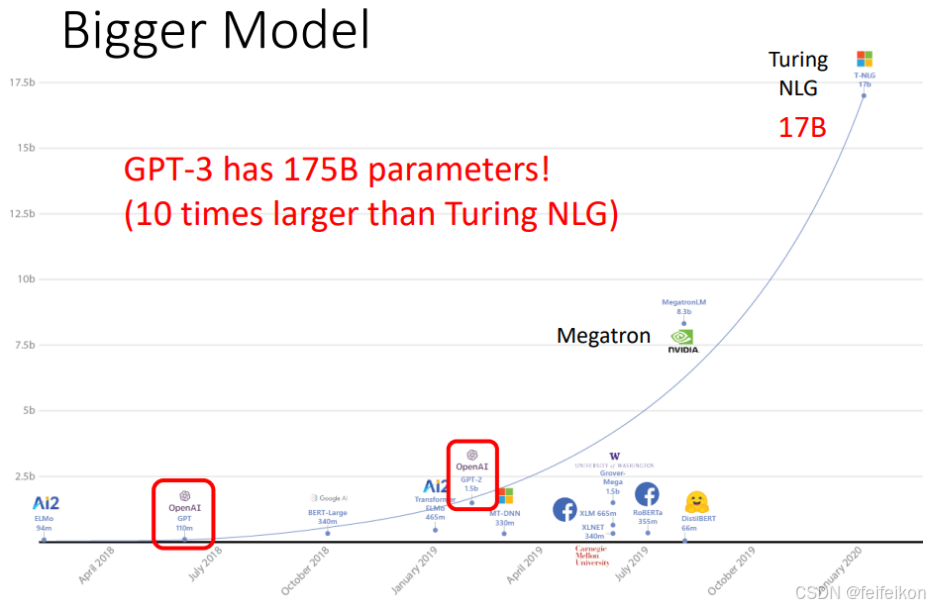
之前最大的语言模型是Turing NLG,它由170亿参数,而GPT-3的参数量是它的10倍。
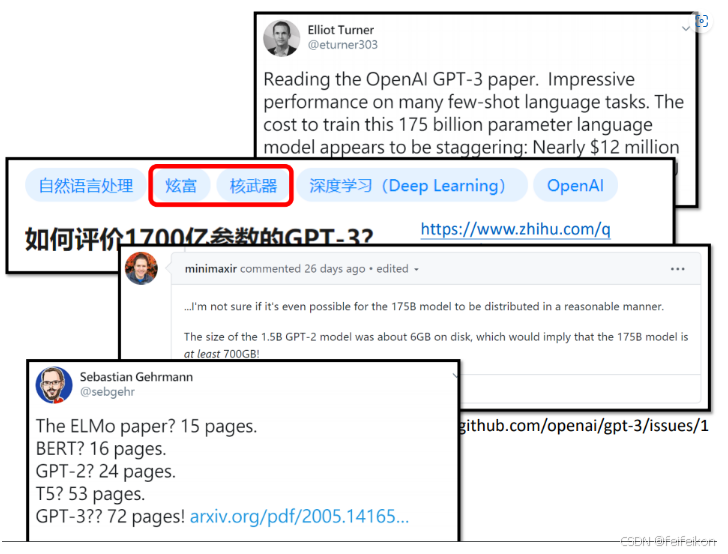
由于它的参数量过于巨大,如果你想自己训练一个GPT-3模型,需要花费1200万美元,呵呵,这真的是炫富。
15亿的参数需要6G的硬盘来保存,175亿的参数至少需要700G!
而且GPT-3论文的页数页数冠绝群雄,它有72页!
GPT-3想要做的事情是Zero-Shot Learning(零次学习)【这个GPT2一样】

它由三种情形,如上图所示。以翻译为例,在Few-shot Learinng中,首先给模型看一个任务说明的句子“Translate English to French”,接下来让模型看几个例子(没有梯度下降),然后问模型“cheese”应该翻译成什么;
而One-shot Learing和上面一样,不过只给一个例子;最牛的是Zero-shot Learing,只给说明,不给例子,直接问模型问题。
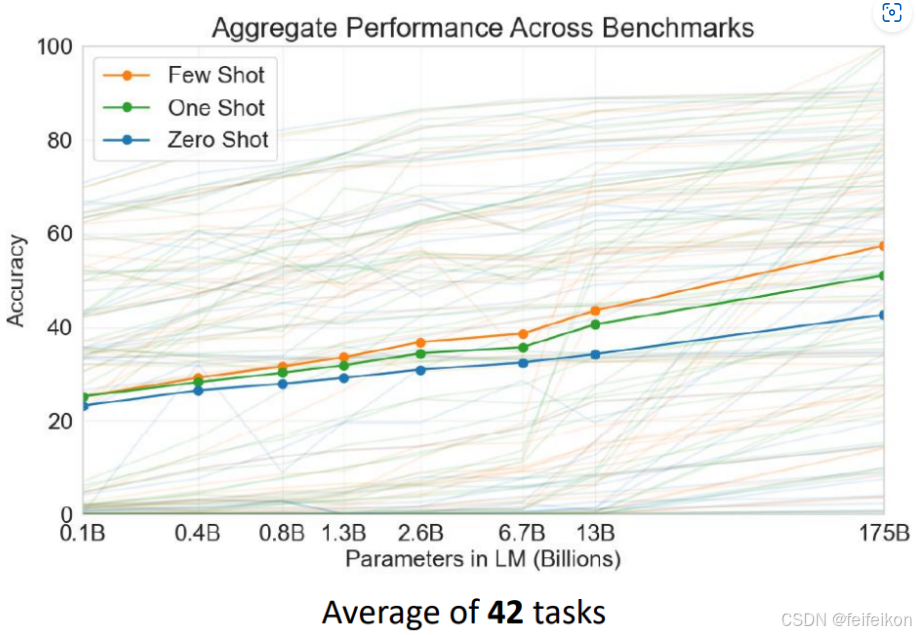
横轴是模型大小,纵轴是准确率,可以看到,随着模型越来越大,正确率也越来越高。
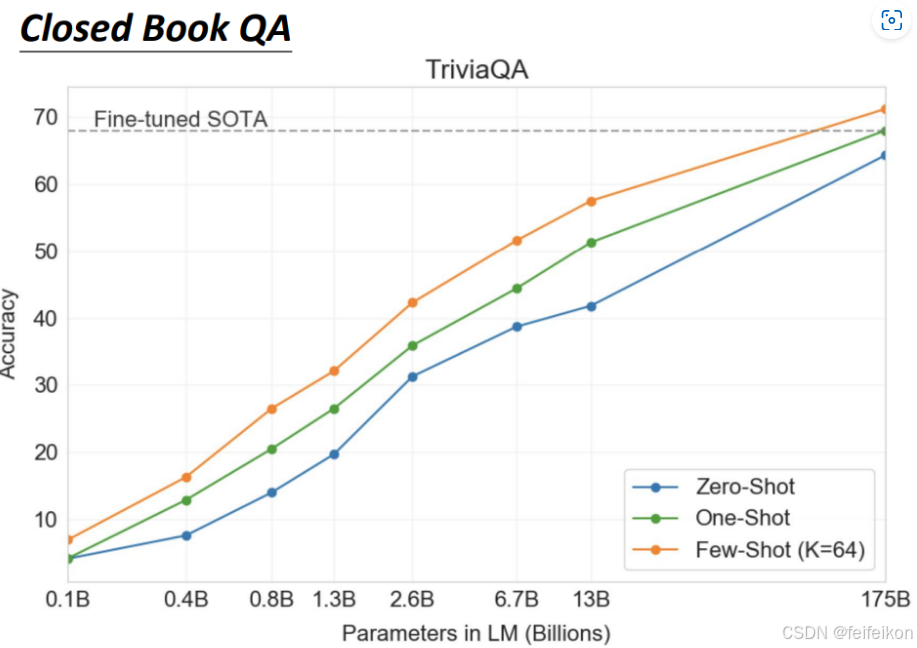
接下来看几个GPT-3的神奇之处,Closed Book QA的意思是,直接问训练好的GPT-3模型,比如“喜马拉雅山有多高”,但不提供关于喜马拉雅山的描述资料,让GPT-3回答问题。
上图是GPT-3的表现,可以看到,Few-Shot Learning的结果竟然超过了微调好的SOTA。
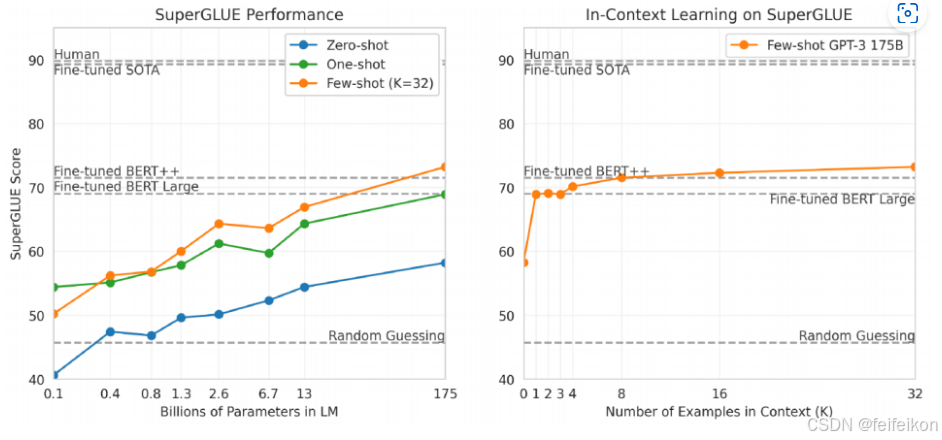
上图左边是应用于SuperGLUE任务,随着参数量越来越多,表现越来越好。右边显示在进行Few-Shot Learning时,随着给的例子越来越多,对GPT-3表现的影响。可以看到,只要给到32个,就能超过微调好的BERT Large模型。
3.3 GPT-3模型结构
- GPT基于transformer的decoder结构。
- GPT-3模型和GPT-2一样,但GPT-3应用了Sparse Transformer中的attention结构。
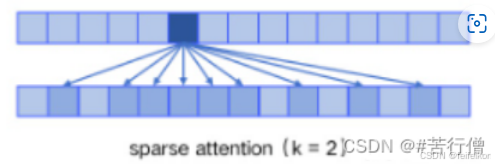
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
- dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)
- sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,… 的 token,其他所有 token 的注意力都设为 0,如下图所示:
使用 sparse attention 的好处主要有以下两点:
- 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
- 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
3.4 训练范式:预训练 + few-shot(in-context learning)
论文尝试了如下下游任务的评估方法:few-shot learning(10-100个小样本);one-shot learning(1个样本);zero-shot(0个样本);其中few-shot效果最佳。
- fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数
- few-shot(又称为in-context learning):预训练 + task description + examples + prompt,预测。不更新模型参数
3.5 与GPT-2区别
- 模型结构上来看,在gpt2的基础上,将attention改为了sparse attention(交替使用 Dense Attention 和 Sparse Attention)。
- 效果上远超gpt2,生成的内容更为真实。
- GPT-3 主推few-shot,而GPT-2 主推zero-shot。(证明 few-shot 性能显著优于 zero-shot,甚至接近监督微调模型;模型规模越大,few-shot 的收益越明显)
- 数据量远大于gpt2:gpt3(45T,清洗后570G),gpt2(40G)。
- gpt3最大模型参数为1750亿,gpt2最大为15亿。
3.6 GPT-3的In-context learning 和 元学习 的关联
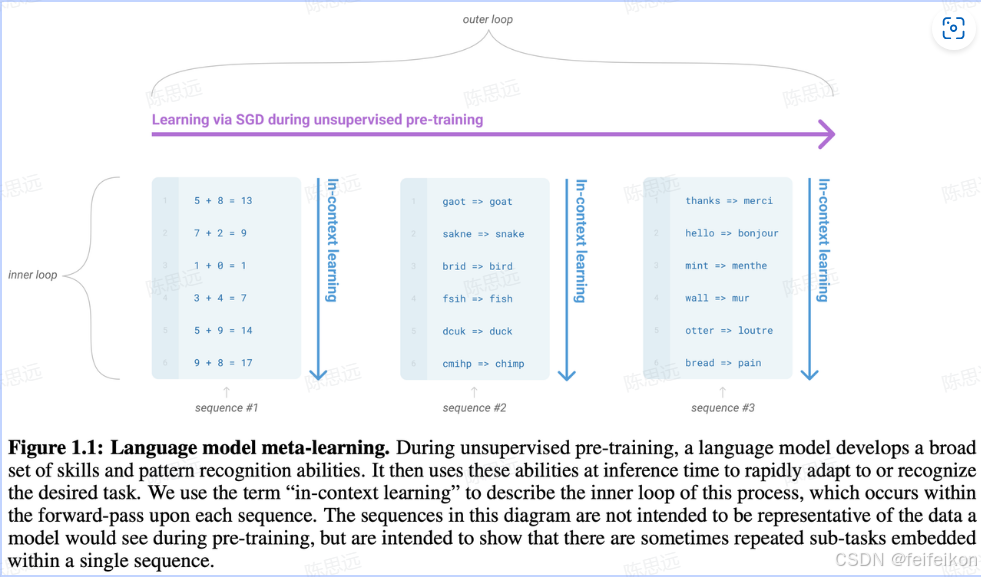
在无监督预训练过程中,语言模型会学习到一系列的技能和模式识别能力。然后,在推理时(inference),它可以利用这些能力快速适应或识别所需的任务。我们使用术语 “in-context learning”(上下文学习)来描述此过程中的内循环,它发生在对每个序列的前向传播(forward-pass)过程中。
上图中的序列并不一定代表模型在预训练期间实际看到的数据,而是旨在说明在一个序列内部可能嵌入多个重复的子任务。
3.6.1 In‐context learning 与元学习之间的联系
在传统的元学习(例如MAML等算法)中,也会将学习分成一个“外循环”和“内循环”:
In‐context learning可以视作一种“不做参数更新的元学习”,即在推理时,模型并不改变内部权重,而是靠输入序列(上下文)中给出的示例(如题目-答案对、翻译示例等),来“激发”或“调动”模型预训练时学到的各种潜在能力。
- 外循环:利用一批元任务(meta‐tasks)更新元模型参数,使其具备“快速适应”的能力。
- 内循环:在每个具体任务上做少量训练或者更新,用来模拟实际场景的“快速学习”。
3.7 实验
GPT-3参数量1750亿。
爬取一部分低质量的Common Crawl作为负例,高质量的Reddit作为正例,用逻辑回归做二分类,判断质量好坏。接下来用分类器对所有Common Crawl进行预测,过滤掉负类的数据,留下正类的数据;去重,利用LSH算法(用于判断两个集合的相似度,经常用于信息检索);
加入之前gpt,gpt-2,bert中使用的高质量的数据
3.8 GPT-3局限性
1、生成长文本依旧困难,比如写小说,可能还是会重复;
2、语言模型只能看到前面的信息;
3、预训练语言模型的通病,在训练时,语料中所有的词都被同等看待,对于一些虚词或无意义的词同样需要花费很多计算量去学习,无法区分学习重点;
4、只有文本信息,缺乏多模态;
5、样本有效性不够;
6、模型是从头开始学习到了知识,还是只是记住了一些相似任务,这一点不明确;
7、可解释性弱,模型是怎么决策的,其中哪些权重起到决定作用?
8、负面影响:可能会生成假新闻;可能有一定的性别、地区及种族歧视

















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









