







 本文介绍了深度学习中的正则化技术,包括L1和L2正则化、Dropout、数据增强以及早停策略,旨在解决过拟合问题,提高模型在未知数据上的性能。通过Python实例展示了如何在Keras中应用这些技术,以MNIST数据集为例。
本文介绍了深度学习中的正则化技术,包括L1和L2正则化、Dropout、数据增强以及早停策略,旨在解决过拟合问题,提高模型在未知数据上的性能。通过Python实例展示了如何在Keras中应用这些技术,以MNIST数据集为例。
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
磐石
介绍
数据科学研究者们最常遇见的问题之一就是怎样避免过拟合。你也许在训练模型的时候也遇到过同样的问题–在训练数据上表现非同一般的好,却在测试集上表现很一般。或者是你曾在公开排行榜上名列前茅,却在最终的榜单排名中下降数百个名次这种情况。那这篇文章会很适合你。
去避免过拟合可以提高我们模型的性能。

在本文中,我们将解释过拟合的概念以及正则化如何帮助克服过拟合问题。随后,我们将介绍几种不同的正则化技术,并且最后实战一个Python实例以进一步巩固这些概念。
注意:本文假设你具备神经网络及其在keras中实现神经网络结构的基本知识。如果没有,你可以先参考下面的文章。
目录
- 什么是正则化?
- 正则化如何帮助减少过拟合?
- 深度学习中的不同正则化技术
L2和L1正则化
Dropout
数据增强(Data Augmentation)
早停(Early stopping)
- 使用Keras处理MNIST数据案例研究
一、什么是正则化?
深入探讨这个话题之前,请看一下这张图片:
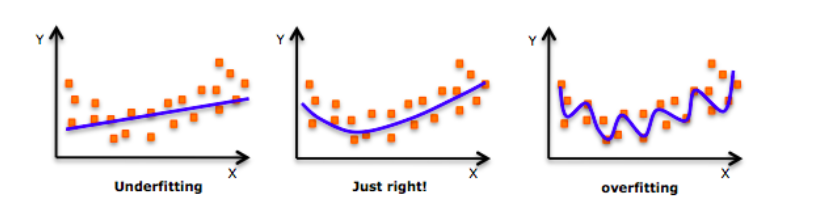
不知道你之前有么有看到过这张图片?当我们训练模型时,我们的模型甚至会试图学到训练数据中的噪声,最终导致在测试集上表现很差。
换句话说就是在模型学习过程中,虽然模型的复杂性增加、训练错误减少,但测试错误却一点也没有减少。这在下图中显示。
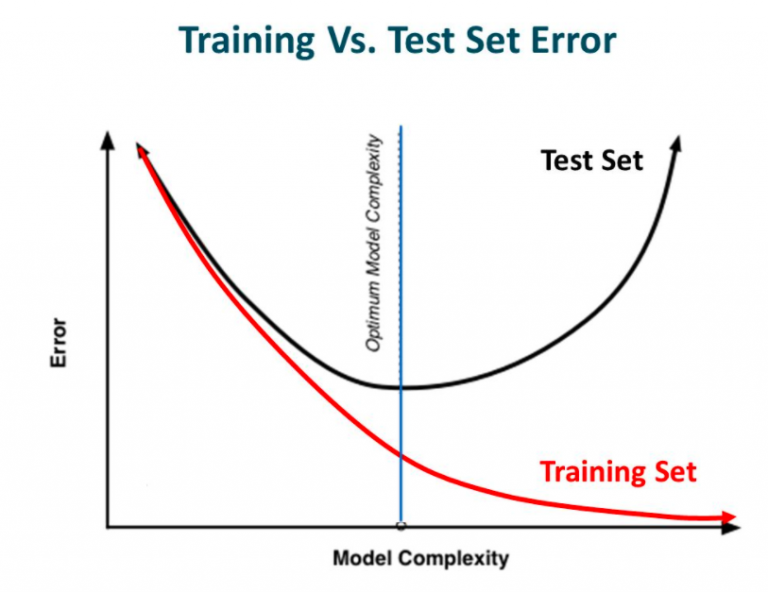
来源:Slideplayer
如果你有构建过神经网络的经验,你就知道它们是有多复杂。这使得更容易过拟合。

正则化是一种对学习算法进行微调来增加模型鲁棒性的一种技术。这同时也意味着会改善了模型在未知的数据上的表现。
二、正则化如何帮助减少过拟合?
让我们来分析一个在训练中过拟合的神经网络模型,如下图所示。
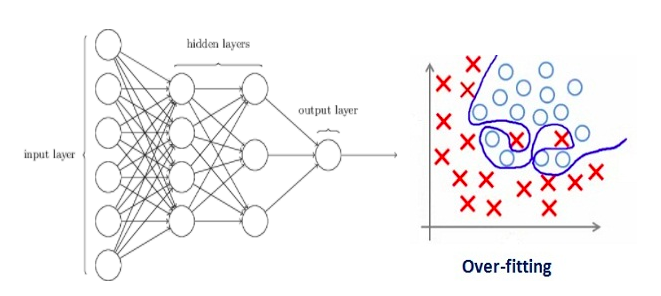
如果你了解过机器学习中正则化的概念,那你肯定了解正则项惩罚系数。在深度学习中,它实际上会惩罚节点的权重矩阵。
如果我们的正则项系数很高以至于一些权重矩阵几乎等于零。
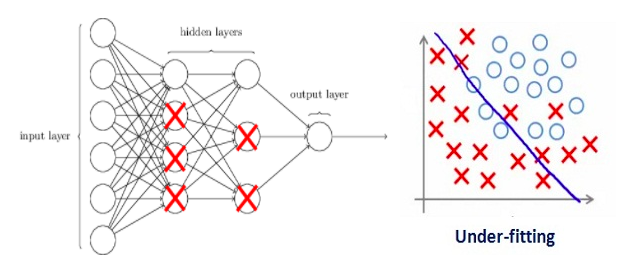
这将导致出现一个极其简单的线性网络结构和略微训练数据不足。
较大数值的正则项系数显然并不是那么有用。我们需要优化正则项系数的值。以便获得一个良好拟合的模型,如下图所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









