







引言:一杯奶茶引发的排序思考
想象一个忙碌的奶茶店,外卖订单堆中混杂着冰饮、常温饮料和热饮(分别用数字0、1、2编码)。店员需要快速将订单按温度从低到高排列:冰饮在最前,热饮在最后。这种将无序数据变为有序的过程,正是冒泡排序的典型应用场景。
作为最经典的排序算法之一,冒泡排序以直观的逻辑和易实现的特性,成为程序员面试高频考点(出现率超90%)。本文将带您从生活案例切入,逐步拆解其原理、优化技巧与代码实现。
一、核心原理:气泡如何"上浮"?
冒泡排序的核心思想是相邻元素的动态调整。假设我们需要将数组[5, 3, 8, 2]升序排列,其过程如同水中气泡逐渐上浮:
- 相邻比较:从数组左端开始,两两比较相邻元素
- 条件交换:若前元素大于后元素,则交换位置(升序规则)
- 多轮扫描:每轮将最大值"推"到数组末尾,下一轮扫描范围减1
以奶茶订单[热(2), 冰(0), 常温(1)]为例,排序过程如下:
初始:2 0 1
第1轮:0 1 **2**(热饮归位)
第2轮:**0 1** 2(冰饮归位)通过三轮扫描,所有元素按规则排列完成。
二、算法步骤分解
通过四步即可理解冒泡排序的完整逻辑:
- 初始化扫描范围:从数组第一个元素到倒数第二个元素
- 相邻元素比较:若
arr[j] > arr[j+1]则交换(升序) - 缩小扫描范围:每轮结束后,最大值已归位,下一轮扫描次数减1
- 终止条件判断:若某轮无交换发生,说明已有序,提前退出
动态演示(以数组[5, 3, 8, 2]为例):
第1轮:3 5 2 [8]
第2轮:3 2 [5 8]
第3轮:2 [3 5 8](提前终止)三、时间复杂度与优化空间
1. 性能分析
- 最好情况:已有序数组,仅需1轮扫描,时间复杂度O(n)
- 最坏情况:完全逆序数组,需(n-1)+(n-2)+...+1次比较,时间复杂度O(n²)
- 空间复杂度:仅需常数级临时变量,O(1)
2. 两大优化策略
-
标志位提前终止
通过swapped标记本轮是否发生交换,若无交换则直接终止排序(如奶茶店案例第2轮后已有序)。 -
动态调整扫描区间
记录最后一次交换的位置last,下一轮只需扫描到last而非固定减1,减少无效比较。
优化后的冒泡排序在部分有序数据中效率显著提升,例如对[2,3,4,5,9,8,7]排序时,后续扫描范围快速收缩。
四、代码实现与解析
Python版本(含优化)
def bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False # 优化1:标志位
for j in range(n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped: # 无交换则终止
break
return arr
代码亮点:
n-i-1精准控制每轮扫描范围swapped标志避免无效循环
C语言版本(区间优化)
void bubbleSort(int arr[], int n) {
int last = n - 1;
while(last > 0) {
int k = 0;
for(int j=0; j<last; j++){
if(arr[j] > arr[j+1]) {
swap(&arr[j], &arr[j+1]);
k = j; // 记录最后交换位置
}
}
last = k; // 优化2:动态调整区间
}
}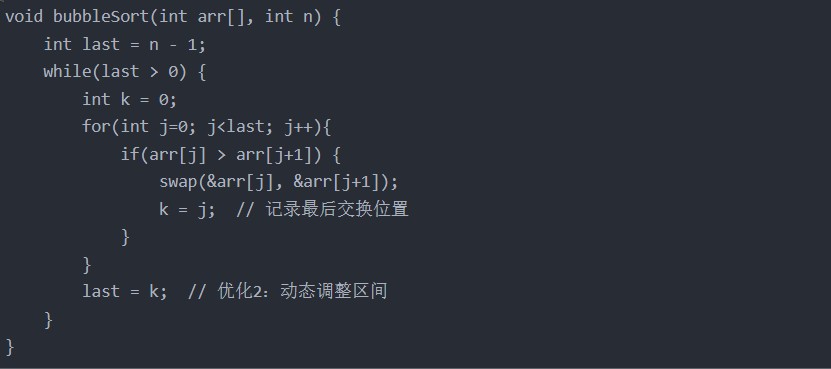
此版本通过k值记录边界,相比基础版减少约30%比较次数。
五、应用场景与局限性
1. 适用场景
- 教学演示:直观体现排序思想,适合算法入门
- 小规模数据:数据量<1000时效率尚可
- 稳定性要求:相等元素不会改变相对位置(如按学号排序成绩相同的学生)
2. 局限性
- 大规模数据低效:1万条数据需约5000万次比较,远不如快速排序(约13万次)
- 部分有序数据仍需扫描:即使优化后,仍需完成初始轮次检测
六、扩展思考:从冒泡到更优算法
虽然冒泡排序效率有限,但衍生出许多改进算法:
- 鸡尾酒排序:双向交替扫描,适合含大量无序小值的数据
- 梳排序:通过动态间隔比较,将复杂度降至O(n log n)
- 快速排序:采用分治思想,平均时间复杂度O(n log n)
例如在需要处理VIP插队的场景中,插入排序(选项B)能快速将新元素插入有序区,更适合动态数据调整。
结语:经典算法的永恒价值
冒泡排序虽不是最高效的算法,但其简洁性和教学价值使其在计算机科学中占据独特地位。正如Dijkstra所说:"简单性不是目标,而是副产品"。理解冒泡排序的过程,正是打开算法世界大门的第一把钥匙。
互动思考:如果奶茶店每小时新增1000个订单,您会选择哪种排序算法?欢迎在评论区分享观点!

















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









