







背景
内存模型这个名词就很奇怪,它不是说对象的内存布局,而是在说多线程编程问题,这个问题真是孩子没娘,说来话长。
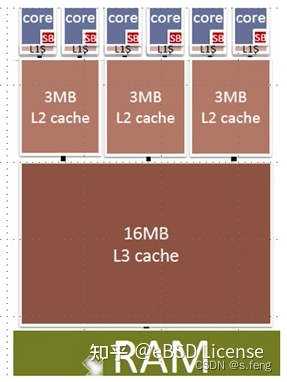
首先是硬件上的,由于计算单元做计算的速度很快,但是每次从内存上去数据速度很慢,为此搞了一缓存的硬件,从缓冲上去数据速度很快。可以看到下面这款cpu有L1/L2/L3三款缓存,此外还有Store Buffer (SB),且SB和L1 是每个Core独享,而L2是两个Core共享,L3是所有Core共享。
为了提高性能,在实际运行中,不管是编译器还是硬件cpu都会重排我们的代码逻辑,既然编译器和cpu都会重排,那么我们先看编译的的做了哪些事情,从下面的两个图片可以看到,当开启优化-O2后执行逻辑完全变化了,但是结果没问题,因为图二中只是把B的写过放在寄存器上,然后一直在这个寄存器上操作,所以结果是对的。
//-std=c++11

//-std=c++11 -O2

但是在多线程上,这个问题就很大,假如线程2依赖这个B的结果,认为一旦B为1(true)的时候,A就True(0+1)了,但是实际A并没有变化,这样,就会发生非预期的行为。
说了这么多问题,那么为啥编译器非要重新排布指令顺序呢?才看看图一,先把B的值放到cache, 然后再把计算结果写到cache里,比如我们cache就是只有一个cache line, 那么为了把计算结果写到cache里,B的值必须被删掉,如果后面还用B就需要重新load。
Invention
// Invention示例代码
// 原始代码
if( cond ) x = 42;
// 优化后代码
r1 = x;// read what's there
x = 42;// oops: optimistic write is not conditional
if( !cond)// check if we guessed wrong
x = r1;// oops: back-out write is not SC















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









