







YOLOv8论文尚未发布,YOLOv8由Ultralytics公司推出并维护,源码见:https://github.com/ultralytics/ultralytics ,于2024年1月发布v8.1.0版本,最新发布版本为v8.2.0,License为AGPL-3.0。
以下内容主要来自:
1. https://docs.ultralytics.com/
2. https://github.com/ultralytics/ultralytics/issues/189
3. https://viso.ai/deep-learning/yolov8-guide/
Ultralytics YOLOv8是一种尖端、最先进(state-of-the-art, SOTA)的模型,它建立在先前YOLO版本成功的基础上,并引入了新功能和改进,以进一步提高性能和灵活性。YOLOv8的设计目标是快速、准确且易于使用,使其成为各种目标检测和跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
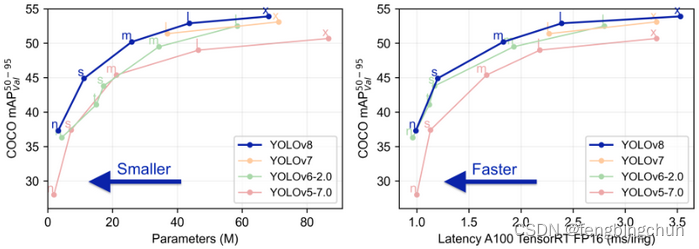
向YOLOv5一样,根据参数数量,YOLOv8有5种不同类型的模型:nano(n), small(s), medium(m), large(l), and extra large(x),如下图所示:
YOLOv8检测模型结构如下所示:来源:https://github.com/ultralytics/ultralytics/issues/189 ,与 YOLOv5 相比,改变如下:
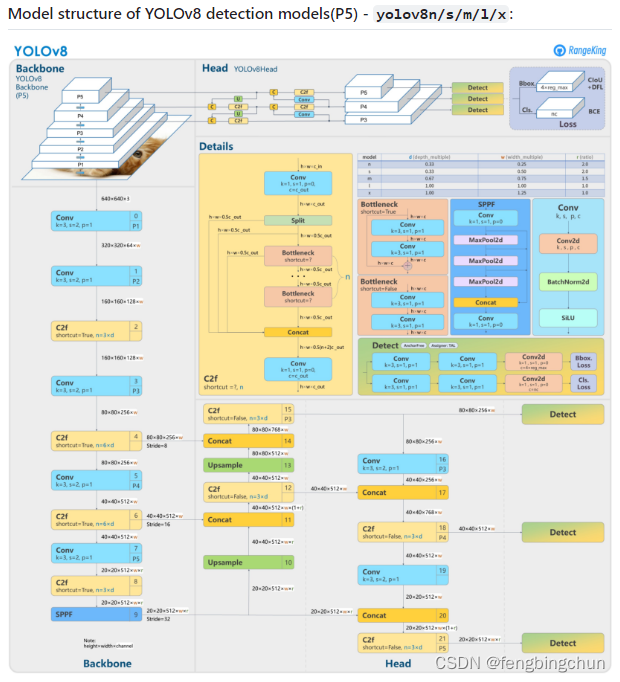
(1).将C3模块替换为C2f模块;
(2).将Backbone中的第一个6*6 Conv替换为3*3 Conv;
(3).删除两个Conv(YOLOv5配置中的No.10和No.14);
(4).将Bottleneck中的第一个1*1 Conv替换为3*3 Conv;
(5).使用解耦头(decoupled head)并删除objectness分支.
YOLOv8架构利用几个关键组件来执行目标检测任务:
(1).Backbone是一系列卷积层,用于从输入图像中提取相关特征。SPPF层和后续的卷积层处理各种尺度的特征,而上采样层则提高特征图的分辨率。C2f模块将高级特征(high-level features)与上下文信息相结合,以提高检测精度。最后,检测模块使用一系列卷积层和线性层将高维特征(high-dimensional features)映射到输出边界框和目标类别。
(2).Head负责获取Backbone生成的特征图并进一步处理它们,以边界框和目标类别的形式生成模型的最终输出。在YOLOv8中,Head被设计为解耦,这意味着它独立处理对象性(objectness)、分类和回归任务。这种设计使得每个分支能够专注于各自的任务,并提高了模型的整体准确性。为了处理特征图,Head使用一系列卷积层,然后是线性层来预测边界框和类别概率。Head的设计针对速度和精度进行了优化,特别关注每层的通道数量和kernel大小,以最大限度地提高性能。注:新版本中objectness head已被删除
(3).YOLOv8中使用的框回归损失基于Smooth L1损失函数,该函数常用于目标检测任务。该损失函数平衡了L1和L2损失函数,并且对训练数据中的异常值不太敏感。它用于计算预测的边界框坐标与ground truth坐标之间的差异。然后使用损失函数在训练过程中更新网络的权重。注:早期版本使用的是Smooth L1,新版本是CIoU、DFL、BCE.
(4).在YOLOv8的输出层中,我们使用sigmoid函数作为objectness分数的激活函数,它表示边界框包含目标的概率。对于类别概率,我们使用softmax函数,它表示目标属于每个可能类别的概率。
(5).YOLOv8中的Neck结构,它是一个新颖的C2f模块,与YOLOv5中使用的PANet结构不同。C2f模块取代了传统的YOLO Neck结构,并改进了网络中的特征提取。
(6).YOLOv8中使用的网格单元的大小取决于图像的输入大小。具体来说,网格单元的大小是通过将输入图像划分为具有一定数量单元的网格来确定的,其中每个单元对应于输出特征图的一个区域。在YOLOv8中,这个网格大小由Backbone中最终卷积层的步长决定。例如,如果最终卷积层的步长(Stride)为32,则输入图像将被划分为32*32单元的网格,网格中的每个单元格将对应于输出特征图的大小为80*80的区域。类似地,如果最终的卷积层的步长为16,那么输入图像将被划分为16*16单元的网格,网格中的每个单元将对应于输出特征图的大小为40*40的区域。YOLOv8中的Stride参数是指输入图像在Backbone中下采样的像素数。
YOLOv8主要features:
(1).Mosaic数据增强:YOLOv8的变化是在最后10个epoch停止Mosaic增强操作以提高性能;
(2).Anchor-Free Detection:YOLOv8改用无锚(anchor-free)检测来提高泛化能力,基于锚点(anchor-based)的检测的问题是预定义的锚点框降低了自定义数据集的学习速度。通过无锚检测,模型直接预测目标的中心点并减少边界框预测的数量,这有助于加速非最大值抑制(Non-maximum Suppression,NMS),用于消除冗余的检测框;
(3).C2f Module:YOLOv8模型的Backbone现在由C2f模块而不是C3模块组成。两者的区别在于,在C2f中,模型连接了所有Bottleneck模块的输出。相反,在C3中,模型使用最后一个Bottleneck模块的输出。Bottleneck模块由bottleneck残差块组成,可减少深度学习网络中的计算成本。这加快了训练过程并改善了梯度流(gradient flow)。
(4).Decoupled Head:Head部不再一起执行分类和回归。相反,它单独执行task,这提高了模型性能。
(5).Loss:使用BCE(Binary Cross-entropy)计算分类损失;使用CIoU(Complete IoU)和DFL(Distributional Focal Loss)计算回归损失。DFL背后的主要思想是解决训练数据中类别不平衡的问题。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









