






导读:Graph kernel可以直观地理解为测量图相似度的函数。它们允许如支持向量机之类的内核化学习算法直接在图上工作,而不需要进行特征提取即可将其转换为固定长度的实值特征向量。一个简单的例子是随机游动核,它在概念上同时对两个图执行随机游动,然后计算两次游动产生的路径数。这等效于在这对图的直接积上进行随机游走,并由此得出可以有效计算的核。

Graph kennel 是一种kernel method, kernel method 在图结构中的研究主要有两类:一是Graph embedding 算法,将图(Graph)结构嵌入到向量空间;另一类就是Graph kernel算法。第一类得到图结构的向量化表示,然后直接应用基于向量的核函数(RBF kernel, Sigmoid kernel, etc.) 处理,但是这类方法将结构化数据降维到向量空间损失了大量结构化信息。而Graph kernel 直接面向图结构数据,既保留了核函数计算高效的优点,又包含了图数据在希尔伯特高维空间的结构化信息。
1. Learning Metrics for Persistence-Based Summaries and Applications for Graph Classification (NIPS 2019)
Qi Zhao, Yusu Wang
Paper: https://arxiv.org/abs/1904.12189
Code: https://github.com/topology474/WKPI
本文关注图中的persistent homology (and its corresponding persistence diagram summary)。目前已经有一系列方法来将persistence diagram映射到矢量表示,以便于机器学习下游使用。在这些方法中,经常预设不同持久性特征的重要性(权重)。但是,在实践中,权重函数的选择通常应取决于人们考虑的特定数据类型的性质,因此,非常有必要从标记的数据中自动学习最佳权重函数(并由此得出持久性图的度量)。本文作者研究了这个问题,并为persistence summaries提出了一个新的加权内核,称为WKPI,以及一个优化框架,以学习persistence summaries的良好度量。本文的内核和优化问题都具有很好的属性。学习到的内核应用于图分类的任务中,并表明基于WKPI的分类框架比一系列基准图数据集上的一系列先前图分类框架的最佳结果获得的相似或更好的结果(有时明显) 。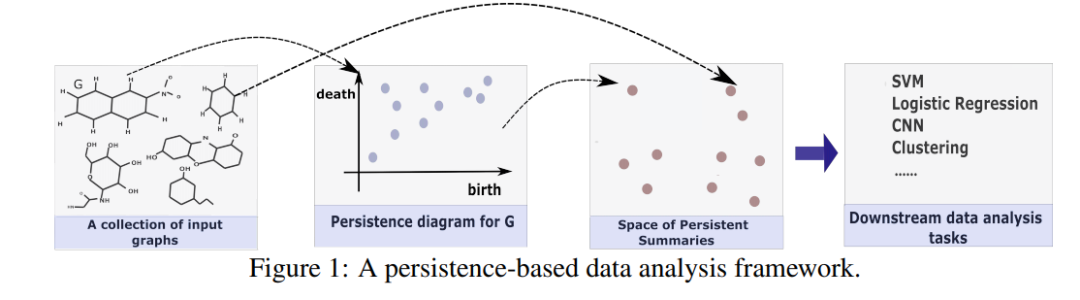
2. A Persistent Weisfeiler–Lehman Procedure for Graph Classification (ICML 2019)
Sebastian Rieck, Christian Bock, and Karsten Borgwardt
Paper: http://proceedings.mlr.press/v97/rieck19a/rieck19a.pdf
Python Reference: https://github.com/BorgwardtLab/P-WL
Weisfeiler-Lehman图内核在许多图分类任务中表现出竞争优势。但是,其子树特征无法捕获连接的成分和环,但是这些是用于表征graph-level拓扑非常重要的特征。为了提取此类特征,本文利用节点标签信息并将未加权的图转换为度量图。这能够利用持久性同源性(拓扑数据分析的概念)获得的拓扑信息来扩充子树特征。本文的方法可以看做是Weisfeiler-Lehman的泛化,具有良好的分类精度,其中的涨点主要在于循环信息的利用(cycle information)
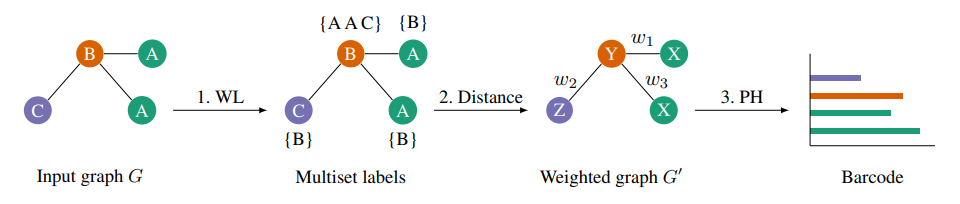
最后的3PH就是提到的persistent homology (PH) features
3. Message Passing Graph Kernels (2018)
Giannis Nikolentzos, Michalis Vazirgiannis
Paper: https://arxiv.org/pdf/1808.02510.pdf
Python Reference: https://github.com/giannisnik/message_passing_graph_kernels
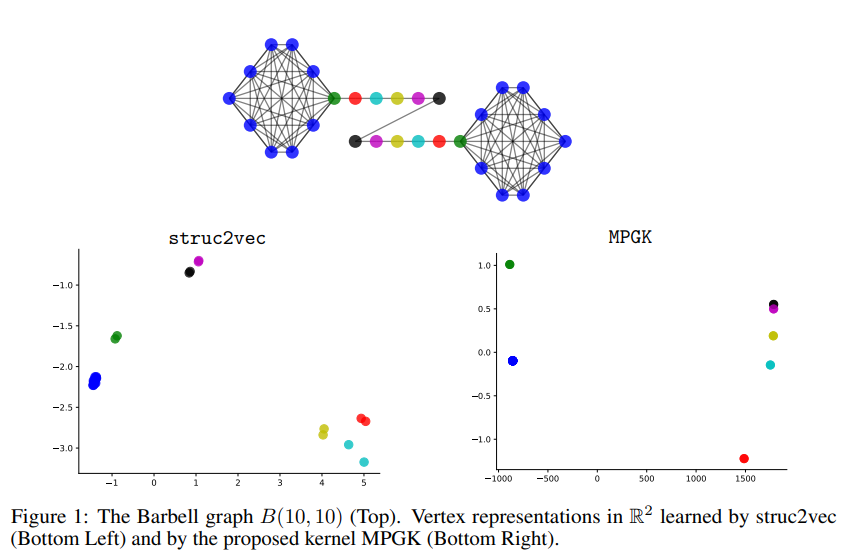
图内核可以用于解决图相似性和以及图学习的任务。在本文中,作者提出了一个用于设计图内核的通用框架。所提出的框架利用了图上众所周知的消息传递方案。 该框架的内核包含两个组件。第一个分量是顶点之间的核,而第二个分量是图之间的核。 本文提出的框架背后的主要思想是使用迭代隐式地更新顶点的表示。然后,这些表示用作比较图对的内核的构建块。 作者推导了所提出框架的四个实例,并通过广泛的实验表明,这些实例在各种任务中与最新方法具有竞争力。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑AI基础下载(pdf更新到25集)机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085,加入微信群请扫码喜欢文章,点个在看

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









