






The Annotated Transformer注释加量版
前面我们从0实现了Transformer和GPT2的预训练过程,并且通过代码注释和打印数据维度使这个过程更容易理解,今天我将用同样的方法继续学习Bert。
原始Transformer是一个Encoder-Decoder架构,GPT是一种Decoder only模型,而Bert则是一种Encoder only模型,所以我们主要关注Transformer的左侧部分。
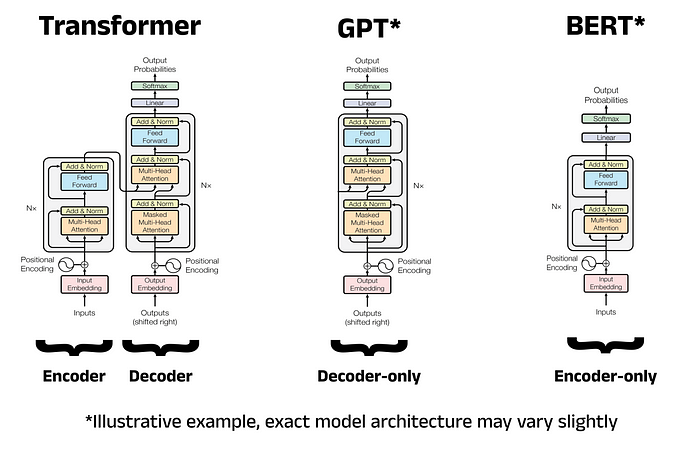
阅读本文时请结合代码
https://github.com/AIDajiangtang/annotated-transformer/blob/master/AnnotatedBert.ipynb0.准备训练数据
0.0下载数据
原始BERT使用BooksCorpus和English Wikipedia作为预训练数据,但这个数据集太大了,我们本次使用IMDb网站的50,000条电影评论数据来预训练,它是一个包含两列数据的csv文件,其中review列是电影评论,sentiment列是情感标签,即正面(positive)或负面(negative),我们本次只使用review列的电影评论。
下面打印出一条评论
One of the other reviewers has mentioned that after watching just 1 Oz episode you'll be hooked.
They are right, as this is exactly what happened with me.<br /><br />The first thing that struck me about Oz was its brutality and unflinching scenes of violence, which set in right from the word GO.
Trust me, this is not a show for the faint hearted or timid. This show pulls no punches with regards to drugs, sex or violence. Its is hardcore, in the classic use of the word.<br /><br />It is called OZ as that is the nickname given to the Oswald Maximum Security State Penitentary. It focuses mainly on Emerald City, an experimental section of the prison where all the cells have glass fronts and face inwards, so privacy is not high on the agenda. Em City is home to many..Aryans, Muslims, gangstas, Latinos, Christians, Italians, Irish and more....so scuffles, death stares, dodgy dealings and shady agreements are never far away.<br /><br />I would say the main appeal of the show is due to the fact that it goes where other shows wouldn't dare. Forget pretty pictures painted for mainstream audiences, forget charm, forget romance...OZ doesn't mess around. The first episode I ever saw struck me as so nasty it was surreal, I couldn't say I was ready for it, but as I watched more, I developed a taste for Oz, and got accustomed to the high levels of graphic violence. Not just violence, but injustice (crooked guards who'll be sold out for a nickel, inmates who'll kill on order and get away with it, well mannered, middle class inmates being turned into prison bitches due to their lack of street skills or prison experience) Watching Oz, you may become comfortable with what is uncomfortable viewing....thats if you can get in touch with your darker side.ds = IMDBBertDataset(BASE_DIR.joinpath('data/imdb.csv'), ds_from=0, ds_to=1000)为了加快训练,通过ds_from和ds_to参数设置只读取前1000条评论。
0.1计算上下文长度
上下文长度是指输入序列的最大长度,再讲Transformer和GPT2时,是直接通过超参数设置的,今天我们将根据训练数据统计得出,通过pandas逐行读取1000条数据,将每条评论按'.'分割成句子,并将所有句子的长度存储到一个数组中。取句子长度数组中第90百分位的值。
通过计算,找到最优的句子长度:27,如果样本长度大于27会被截断,小于27会用特殊字符填充。
举个简单的例子,假设句子长度数组为 [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],那么第90百分位的值就是90。
0.2分词
本次使用的是basic_english分词方法,它是一种非常简单且直接的分词方法,先将所有文本转换为小写,然后去除标点符号,最后按空格和标点符号将文本拆分成单词。
"Hello, world! This is an example sentence."
['hello', 'world', 'this', 'is', 'an', 'example', 'sentence']接下来将拆分后的单词转换成一个数字id,这个过程需要根据训练数据构造一个词表,也就是找到训练数据中所有唯一单词。
通过统计可知,这1000条数据包含词汇数:9626
然后将下面特殊字符加到词表前面。
CLS = '[CLS]'
PAD = '[PAD]'
SEP = '[SEP]'
MASK = '[MASK]'
UNK = '[UNK]'0.3构造训练数据
BERT是一种Encoder only架构,每一个token会与其它所有token计算注意力,无论是它前面的还是后面的。这样能充分吸收上下文信息,Encoder only的模型适合理解任务。
而Decoder只与它前面的token计算注意力。从这种意义上看,GPT只利用了上文,但这种自回归的方式也有好处,就是适合生成任务。
为了学习双向表示,除了模型结构,构造训练数据方式也有所不同。
GPT是用当前词预测下一个词,假设训练数据的token_ids = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],context_length=4,stride=4,batch_size=2。
Input IDs: [tensor([1, 2, 3, 4]), tensor([5, 6, 7, 8])]
Target IDs: [tensor([2, 3, 4, 5]),tensor([6, 7, 8, 9])]BERT采用两种方式构造预训练数据:
“masked language model” (MLM)
“next sentence prediction”(NSP)
MLM会随机将一个样本中的某些词替换成[MASK],或者替换成词表中的其它词,在本例中,会替换15%的词,其中80%替换成[MASK],20%替换成词表中的其它词。
NSP则是将相邻的句子构造成正样本对,将不相邻的句子视为负样本对,两个句子之间加一个[SEP]分割符。
BERT不善于生成任务,那它如何完成问答等下游任务?其实,BERT会在每个样本开头都会放一个[CLS] token,通过CLS输出进行二分类。
知道方法后,接下来构造训练数据,首先遍历这1000条电影评论文本。
以第一条评论为例
One of the other reviewers has mentioned that after watching just 1 Oz episode you'll be hooked.
They are right, as this is exactly what happened with me.<br /><br />The first thing that struck me about Oz was its brutality and unflinching scenes of violence, which set in right from the word GO.
Trust me, this is not a show for the faint hearted or timid. This show pulls no punches with regards to drugs, sex or violence. Its is hardcore, in the classic use of the word.<br /><br />It is called OZ as that is the nickname given to the Oswald Maximum Security State Penitentary. It focuses mainly on Emerald City, an experimental section of the prison where all the cells have glass fronts and face inwards, so privacy is not high on the agenda. Em City is home to many..Aryans, Muslims, gangstas, Latinos, Christians, Italians, Irish and more....so scuffles, death stares, dodgy dealings and shady agreements are never far away.<br /><br />I would say the main appeal of the show is due to the fact that it goes where other shows wouldn't dare. Forget pretty pictures painted for mainstream audiences, forget charm, forget romance...OZ doesn't mess around. The first episode I ever saw struck me as so nasty it was surreal, I couldn't say I was ready for it, but as I watched more, I developed a taste for Oz, and got accustomed to the high levels of graphic violence. Not just violence, but injustice (crooked guards who'll be sold out for a nickel, inmates who'll kill on order and get away with it, well mannered, middle class inmates being turned into prison bitches due to their lack of street skills or prison experience) Watching Oz, you may become comfortable with what is uncomfortable viewing....thats if you can get in touch with your darker side.将该评论按照“.” 分割成句子,遍历每个句子。
第一个句子:
One of the other reviewers has mentioned that after watching just 1 Oz episode you'll be hooked
第二个句子:
They are right, as this is exactly what happened with me.<br /><br />The first thing that struck me about Oz was its brutality and unflinching scenes of violence, which set in right from the word GO
第一个句子分词:
['one', 'of', 'the', 'other', 'reviewers', 'has', 'mentioned', 'that', 'after', 'watching', 'just', '1', 'oz', 'episode', 'you', "'", 'll', 'be', 'hooked']
第二个句子分词:
['they', 'are', 'right', ',', 'as', 'this', 'is', 'exactly', 'what', 'happened', 'with', 'me', '.', 'the', 'first', 'thing', 'that', 'struck', 'me', 'about', 'oz', 'was', 'its', 'brutality', 'and', 'unflinching', 'scenes', 'of', 'violence', ',', 'which', 'set', 'in', 'right', 'from', 'the', 'word', 'go']
将每个句子随机选择15%的单词进行随机掩码,开头加上[CLS],padding到上下文长度27,然后将两个句子拼接在一起,用[SEP]分割符分开。
['[CLS]', 'one', 'of', 'the', 'other', 'reviewers', 'has', 'mentioned', '[MASK]', 'after', 'watching', 'just', '1', 'oz', 'episode', 'you', "'", '[MASK]', '[MASK]', 'hooked', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[SEP]', '[CLS]', 'they', 'are', 'right', ',', 'as', 'this', 'is', '[MASK]', 'what', 'happened', '[MASK]', 'me', '[MASK]', 'the', '[MASK]', 'financiers', 'that', 'struck', 'me', 'about', 'oz', 'was', 'its', 'brutality', 'and', 'unflinching']
根据上面掩码句子构造输入掩码,[MASK]的位置设置成Flase,其余为True。
[True, True, True, True, True, True, True, True, False, True, True, True, True, True, True, True, True, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, False, True, True, False, True, False, True, False, False, True, True, True, True, True, True, True, True, True, True]
将带掩码的句子转换成token ids,这个也是最终要输入到模型中的X。
[0, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18, 19, 20, 2, 2, 23, 1, 1, 1, 1, 1, 1, 1, 3, 0, 24, 25, 26, 27, 28, 29, 30, 2, 32, 33, 2, 35, 2, 7, 2, 32940, 12, 39, 35, 40, 17, 41, 42, 43, 44, 45]
将掩码前的句子转换成token ids,这个就是标签Y。
[0, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 1, 1, 1, 1, 1, 1, 1, 3, 0, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 7, 37, 38, 12, 39, 35, 40, 17, 41, 42, 43, 44, 45]
通过模型输出与标签Y计算MLM损失。
那NSP的损失呢?在构造句子对时,如果两个句子是相邻的,那么标签就是1,否则是0,最终通过[CLS]的输出计算二分类损失。
最终根据前1000行数据构造了一个DataFrame,DataFrame中每一条是一个样本,一共包含17122个样本,每个样本包含四列。
一个是输入X,维度[1,55]
一个是标签Y,维度[1,55],
输入掩码,维度[1,55]
NSP分类标签,0或者1。
55等于2两个句子的长度加上一个[SEP]分割符,每个句子长度27。
1.预训练
超参数
EMB_SIZE = 64 #词嵌入维度
HIDDEN_SIZE = 36 //
EPOCHS = 4
BATCH_SIZE = 12 #batch size
NUM_HEADS = 4 //头的个数
根据超参数BATCH_SIZE = 12,也就是每个batch包含12个样本,所以输入X维度[12,55],标签Y维度[12,55]。
1.0词嵌入
接下来将token ids转换成embedding,在Bert中,每个token都涉及到三种嵌入,第一种是Token embedding,token id转换成词嵌入向量,第二种是位置编码。还有一种是Segment embedding。用于表示哪个句子,0表示第一个句子,1表示第二个句子。

根据超参数EMB_SIZE = 64,所以词嵌入维度64,Token embedding通过一个嵌入层[9626,64]将输入[12,55]映射成[12,55,64]。
9626是词表的大小,[9626,64]的嵌入层可以看作是有9626个位置索引的查找表,每个位置存储64维向量。
位置编码可以通过学习的方式获得,也可以通过固定计算方式获得,本次采用固定计算方式。
Segment embedding和输入X大小一致,第一个句子对应为0,第二个位置为1。
最后将三个embedding相加,然后将输出的embedding[12,55,64]输入到编码器中。
1.1多头注意力
编码器的第一个操作是多头注意力,与Transformer和GPT中不同的是,不计算[PAD]的注意力,会将[PAD]对应位置的注意力分数设置为一个非常小的值,使之经过softmax后为0。
多头注意力的输出维度[12,55,64]。
1.2MLP
与Transformer和GPT中的一致,MLP的输出维度[12,55,64]。
1.3输出
编码器的输出[12,55,64],接下来通过与标签计算损失来更新参数。
MLM损失
将Encoder的输出[12,55,64]通过一个线性层[64,9626]映射成概率分布[12,55,9626]。
因为只需要计算[MASK]对应位置的损失,所以会通过一些技巧将标签和输出中,非[MASK]位置设置为0。
最后与输出标签Y计算多分类交叉熵损失。
NSP损失
通过另一个线性层[64,2]将开头的[CLS]的输出[12,64]映射成[12,2],表示属于正负类的概率,然后与标签计算交叉熵损失。
2.0推理
最简单的是完形填空,输入一段文本[1,55],然后将某些词替换成[MASK],将[MASK]的输出通过一个输出头映射成[1,9626]。
因为我们在预训练时使用了“next sentence prediction”(NSP),可以构造一个闭集VQA,就是为一个问题事先准备几个答案,分别将问题和答案拼接在一起输入到BERT,通过[CLS]的输出去分类。
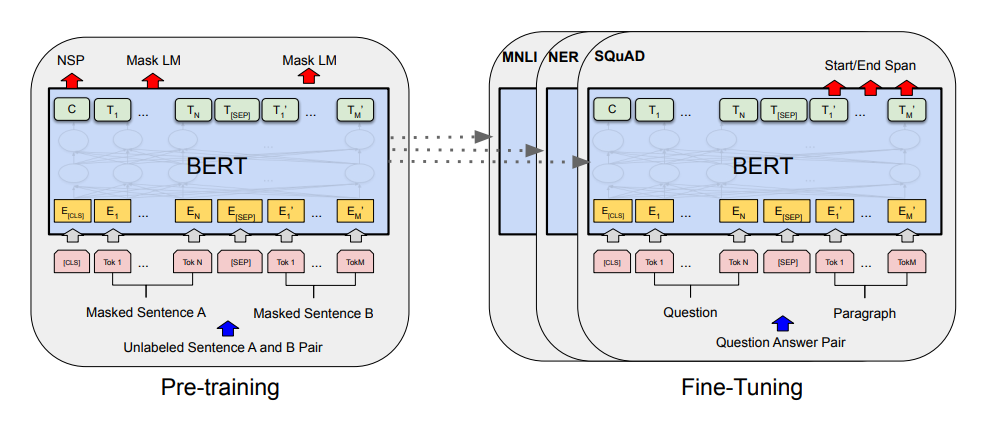
或者去预测答案的起始和终止位置,这就涉及到下游任务的微调了。
总结
至此,我们已经完成了GPT2和BERT的预训练过程,为了让模型能跟随人类指令,后面还要对预训练模型进行指令微调。
参考
https://arxiv.org/pdf/1810.04805
https://github.com/coaxsoft/pytorch_bert
https://towardsdatascience.com/a-complete-guide-to-bert-with-code-9f87602e4a11
https://medium.com/data-and-beyond/complete-guide-to-building-bert-model-from-sratch-3e6562228891
https://coaxsoft.com/blog/building-bert-with-pytorch-from-scratch

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









