







 集成学习通过结合多个分类器提升整体泛化能力。本文介绍了Bagging和Boosting两种方法。Bagging通过随机子集训练多个分类器,减少过拟合,适用于不稳定的模型。Boosting则通过调整训练数据权重,让弱分类器聚焦难分样本,逐步提升性能,对噪声敏感。AdaBoost是Boosting的一种改进,不需要预设弱分类器精度下限。
集成学习通过结合多个分类器提升整体泛化能力。本文介绍了Bagging和Boosting两种方法。Bagging通过随机子集训练多个分类器,减少过拟合,适用于不稳定的模型。Boosting则通过调整训练数据权重,让弱分类器聚焦难分样本,逐步提升性能,对噪声敏感。AdaBoost是Boosting的一种改进,不需要预设弱分类器精度下限。
集成学习
基本思想:如果单个分类器表现的很好,那么为什么不适用多个分类器呢?
通过集成学习可以提高整体的泛化能力,但是这种提高是有条件的:
(1)分类器之间应该有差异性;
(2)每个分类器的精度必须大于0.5;
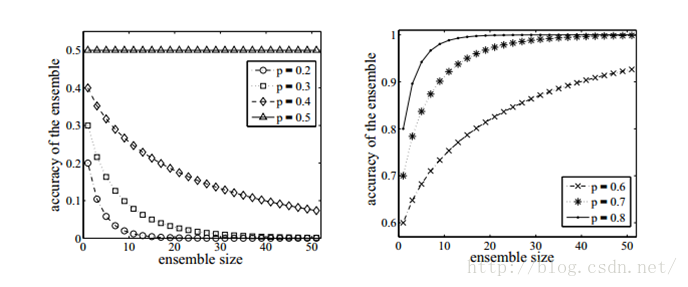
如果使用的分类器没有差异,那么集成起来的分类结果是没有变化的。如下图所示,分类器的精度p<0.5,随着集成规模的增加,分类精度不断下降;如果精度大于p>0.5,那么最终分类精度可以趋向于1。
接下来需要解决的问题是如何获取多个独立的分类器呢?
我们首先想到的是用不同的机器学习算法训练模型,比如决策树、k-NN、神经网络、梯度下降、贝叶斯等等,但是这些分类器并不是独立的,它们会犯相同的错误,因为许多分类器是线性模型,它们最终的投票(voting)不会改进模型的预测结果。
既然不同的分类器不适用,那么可以尝试将数据分成几部分,每个部分的数据训练一个模型。这样做的优点是不容易出现过拟合,缺点是数据量不足导致训练出来的模型泛化能力较差。
下面介绍两种比较实用的方法Bagging和Boosting。
Bagging(Bootstrap Aggregating)算法
Bagging是通过组合随机生成的训练集而改进分类的集成算法。Bagging每次训练数据时只使用训练集中的某个子集作为当前训练集(有放回随机抽样),每一个训练样本在某个训练集中可以多次或不出现,经过T次训练后,可得到T个不同的分类器。对一个测试样例进行分类时,分别调用这T个分类器,得到T个分类结果。最后把这T个分类结果中出现次数多的类赋予测试样例。这种抽样的方法叫做
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









