







首先感谢以下两位的博文帮助我的理解。
(1)lwzkiller https://i-blog.csdnimg.cn/blog_migrate/db3b7a528533c5b94f36dc687a227826.png
(2)青雲-吾道乐途 http://blog.csdn.net/qq_37059483/article/details/77852187
1. 何为角点?
下面有两幅不同视角的图像,通过找出对应的角点进行匹配。

再看下图所示,放大图像的两处角点区域:

我们可以直观的概括下角点所具有的特征:
>轮廓之间的交点;
>对于同一场景,即使视角发生变化,通常具备稳定性质的特征;
>该点附近区域的像素点无论在梯度方向上还是其梯度幅值上有着较大变化;
2. 角点检测算法基本思想是什么?
算法基本思想是使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。

3.如何用数学方法去刻画角点特征?
当窗口发生[u,v]移动时,那么滑动前与滑动后对应的窗口中的像素点灰度变化描述如下:

公式解释:
>[u,v]是窗口的偏移量
>(x,y)是窗口内所对应的像素坐标位置,窗口有多大,就有多少个位置
>w(x,y)是窗口函数,最简单情形就是窗口内的所有像素所对应的w权重系数均为1。但有时候,我们会将w(x,y)函数设定为以窗口中心为原点的二元正态分布。如果窗口中心点是角点时,移动前与移动后,该点的灰度变化应该最为剧烈,所以该点权重系数可以设定大些,表示窗口移动时,该点在灰度变化贡献较大;而离窗口中心(角点)较远的点,这些点的灰度变化几近平缓,这些点的权重系数,可以设定小点,以示该点对灰度变化贡献较小,那么我们自然想到使用二元高斯函数来表示窗口函数,这里仅是个人理解,大家可以参考下。
所以通常窗口函数有如下两种形式:

根据上述表达式,当窗口处在平坦区域上滑动,可以想象的到,灰度不会发生变化,那么E(u,v) = 0;如果窗口处在比纹理比较丰富的区域上滑动,那么灰度变化会很大。算法最终思想就是计算灰度发生较大变化时所对应的位置,当然这个较大是指针任意方向上的滑动,并非单指某个方向。
4.E(u,v)表达式进一步演化
首先需要了解泰勒公式,任何一个函数表达式,均可有泰勒公式进行展开,以逼近原函数,我们可以对下面函数进行一阶展开(如果对泰勒公式忘记了,可以翻翻本科所学的高等数学)
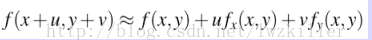
那么,
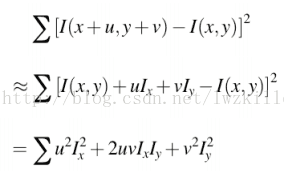
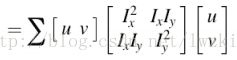
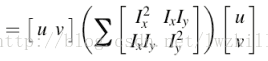
所以E(u,v)表达式可以更新为:
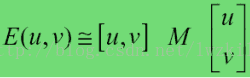
这里矩阵M为,

5.矩阵M的关键性
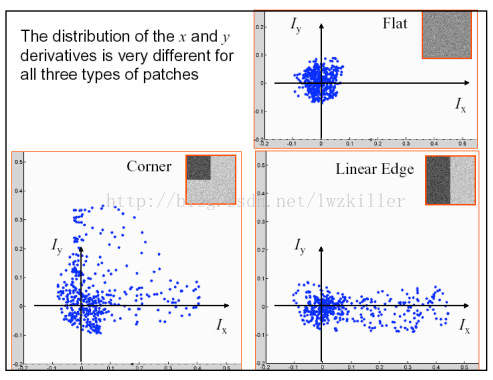
难道我们是直接求上述的E(u,v)值来判断角点吗?Harris角点检测并没有这样做,而是通过对窗口内的每个像素的x方向上的梯度与y方向上的梯度进行统计分析。这里以Ix和Iy为坐标轴,因此每个像素的梯度坐标可以表示成(Ix,Iy)。针对平坦区域,边缘区域以及角点区域三种情形进行分析:

下图是对这三种情况窗口中的对应像素的梯度分布进行绘制:
如果使用椭圆进行数据集表示,则绘制图示如下:
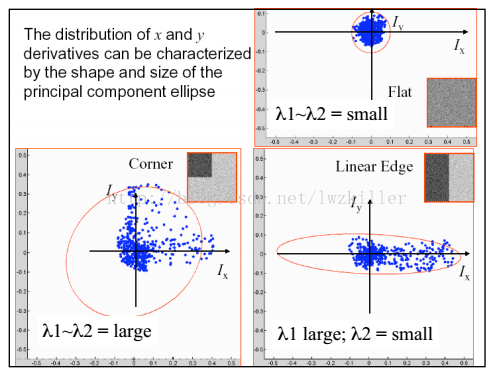
不知道大家有没有注意到这三种区域的特点,平坦区域上的每个像素点所对应的(IX,IY)坐标分布在原点附近,其实也很好理解,针对平坦区域的像素点,他们的梯度方向虽然各异,但是其幅值都不是很大,所以均聚集在原点附近;边缘区域有一坐标轴分布较散,至于是哪一个坐标上的数据分布较散不能一概而论,这要视边缘在图像上的具体位置而定,如果边缘是水平或者垂直方向,那么Iy轴方向或者Ix方向上的数据分布就比较散;角点区域的x、y方向上的梯度分布都比较散。我们是不是可以根据这些特征来判断哪些区域存在角点呢?
虽然我们利用E(u,v)来描述角点的基本思想,然而最终我们仅仅使用的是矩阵M。让我们看看矩阵M形式,是不是跟协方差矩阵形式很像,像归像,但是还是有些不同,哪儿不同?一般协方差矩阵对应维的随机变量需要减去该维随机变量的均值,但矩阵M中并没有这样做,所以在矩阵M里,我们先进行各维的均值化处理,那么各维所对应的随机变量的均值为0,协方差矩阵就大大简化了,简化的最终结果就是矩阵M,是否明白了?我们的目的是分析数据的主要成分,相信了解PCA原理的,应该都了解均值化的作用。
如果我们对协方差矩阵M进行对角化,很明显,特征值就是主分量上的方差,这点大家应该明白吧?不明白的话可以复习下PCA原理。如果存在两个主分量所对应的特征值都比较大,说明什么? 像素点的梯度分布比较散,梯度变化程度比较大,符合角点在窗口区域的特点;如果是平坦区域,那么像素点的梯度所构成的点集比较集中在原点附近,因为窗口区域内的像素点的梯度幅值非常小,此时矩阵M的对角化的两个特征值比较小;如果是边缘区域,在计算像素点的x、y方向上的梯度时,边缘上的像素点的某个方向的梯度幅值变化比较明显,另一个方向上的梯度幅值变化较弱,其余部分的点都还是集中原点附近,这样M对角化后的两个特征值理论应该是一个比较大,一个比较小,当然对于边缘这种情况,可能是呈45°的边缘,致使计算出的特征值并不是都特别的大,总之跟含有角点的窗口的分布情况还是不同的。
注:M为协方差矩阵,需要大家自己去理解下,窗口中的像素集构成一个矩阵(2*n,假设这里有n个像素点),使用该矩阵乘以该矩阵的转置,即是协方差矩阵
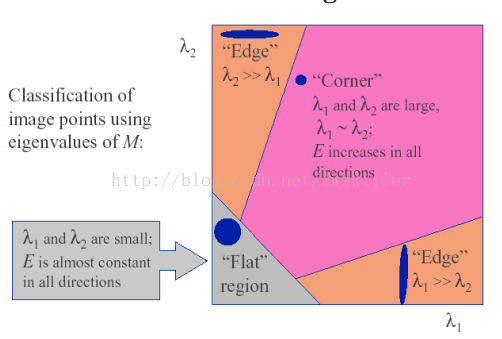
因此可以得出下列结论:
>特征值都比较大时,即窗口中含有角点
>特征值一个较大,一个较小,窗口中含有边缘
>特征值都比较小,窗口处在平坦区域
6. 如何度量角点响应?
(1)Harris用下面表达式进行度量:

其中k是常量,一般取值为0.04~0.06,这个参数仅仅是这个函数的一个系数,它的存在只是调节函数的形状而已。
但是为什么会使用这样的表达式呢?一下子是不是感觉很难理解?其实也不难理解,函数表达式一旦出来,我们就可以绘制它的图像,而这个函数图形正好满足上面几个区域的特征。 通过绘制函数图像,直观上更能理解。绘制的R函数图像如下:
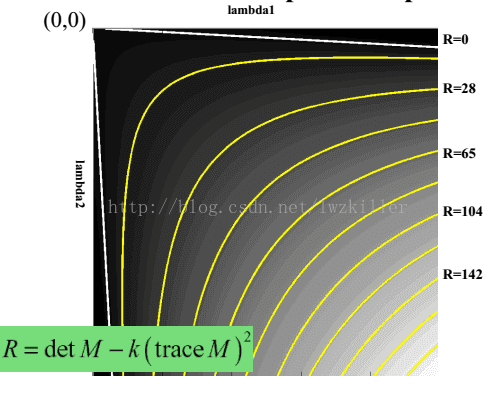
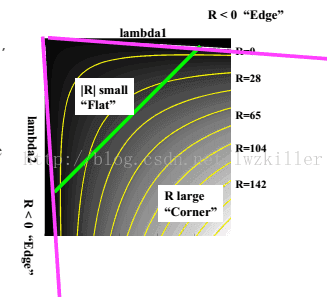
所以说难点不在于理解这个函数表达式,而在于如何创造出这个函数表达式。Harris对很多函数模型非常了解,对于创造出这样的一个函数表达式,易如反掌。最后设定R的阈值,进行角点判断。当然其中还有些后处理步骤,比如说角点的极大值抑制(dilate)。
(2)Shi-Tomasi用下面表达式进行度量:
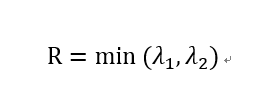
如果打分超过阈值,我们就认为它是一个角点。我们可以把它绘制到 λ1 ~λ2 空间中,就会得到下图:
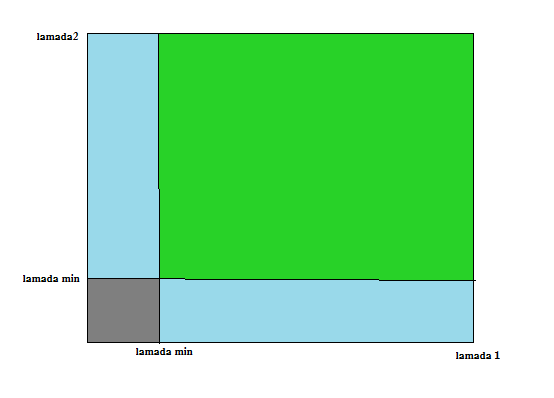
从这幅图中,我们可以看出来只有当 λ1 和 λ2 都大于最小值时,才被认为是角点(绿色区域)。
OpenCV 提供了函数: goodFeaturesToTrack()。这个函数可以帮我们使用 Shi-Tomasi 方法获取图像中 N 个最好的角点(也可以通过改变参数来使用 Harris 角点检测算法)。通常情况下,输入的应该是灰度图像。然后确定你想要检测到的角点数目。再设置角点的质量水平, 0到 1 之间。它代表了角点的最低质量,低于这个数的所有角点都会被忽略(阈值为maxEigVal*qualityLevel)。最后在设置两个角点之间的最短欧式距离。根据这些信息,函数就能在图像上找到角点。所有低于质量水平的角点都会被忽略,然后再把合格角点按角点质量进行降序排列。函数会采用角点质量最高的那个角点(排序后的第一个),然后将它附近(最小距离之内)的角点删掉。按着这样的方式最后返回 N 个最佳角点。
- //goodFeaturesToTrack有比cornerHarries更多的控制参数,函数原型:
- void goodFeaturesToTrack( InputArray image, OutputArray corners,
- int maxCorners, double qualityLevel, double minDistance,
- InputArray mask=noArray(), int blockSize=3,
- bool useHarrisDetector=false, double k=0.04);
- /*第一个参数image:8位或32位单通道灰度图像;
- 第二个参数corners: 位置点向量,保存的是检测到角点的坐标;
- 第三个参数maxCorners: 定义可以检测到的角点的数量的最大值;
- 第四个参数qualityLevel: 检测到的角点的质量等级,角点特征值小于qualityLevel*最大特征
- 值的点将被舍弃;
- 第五个参数minDistance: 两个角点间最小间距,以像素为单位;
- 第六个参数mask: 指定检测区域,若检测整幅图像,mask置为空Mat();
- 第七个参数blockSize: 计算协方差矩阵时窗口大小;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









