







 R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用...
R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用...
R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。
R语言作为统计学一门语言,一直在小众领域闪耀着光芒。直到大数据的爆发,R语言变成了一门炙手可热的数据分析的利器。随着越来越多的工程背景的人的加入,R语言的社区在迅速扩大成长。现在已不仅仅是统计领域,教育,银行,电商,互联网….都在使用R语言。
要成为有理想的极客,我们不能停留在语法上,要掌握牢固的数学,概率,统计知识,同时还要有创新精神,把R语言发挥到各个领域。让我们一起动起来吧,开始R的极客理想。
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-probability/

前方
R语言是统计语言,概率又是统计的基础,所以可以想到,R语言必然要从底层API上提供完整、方便、易用的概率计算的函数。让R语言帮我们学好概率的基础课。
目录
- 随机变量
- 随机变量的数字特征
- 极限定理
1. 随机变量
- 什么是随机变量?
- 离散型随机变量
- 连续型随机变量
1). 什么是随机变量?
随机变量(random variable)表示随机现象各种结果的实值函数。随机变量是定义在样本空间S上,取值在实数载上的函数,由于它的自变量是随机试验的结果,而随机实验结果的出现具有随机性,因此,随机变量的取值具有一定的随机性。
R程序:生成一个在(0,1,2,3,4,5)的随机变量
> S sample(S,1)
[1] 2
> sample(S,1)
[1] 3
> sample(S,1)
[1] 5
2). 离散型随机变量
如果随机变量X的全部可能的取值只有有限多个或可列无穷多个,则称X为离散型随机变量。
R程序:生成样本空间为(1,2,3)的随机变量X,X的取值是有限的
> S X3). 连续型随机变量
随机变量X,取值可以在某个区间内取任一实数,即变量的取值可以是连续的,这随机变量就称为连续型随机变量
R程序:生成样本在空间(0,1)的连续随机函数,取10个值
> runif(10,0,1)
[1] 0.3819569 0.7609549 0.6692581 0.6314708 0.5552201 0.8225527 0.7633086 0.4667188 0.1883553
[10] 0.3741653
2. 随机变量的数字特征
- 数学期望
- 方差
- 标准差
- 各种分步的期望和方差
- 常用统计量(最大,最小,中位数,四分位数)
- 协方差
- 相关系数
- 矩(原点矩,中心矩,偏度,峰度)
- 协方差矩阵
1). 数学期望(mathematical expectation)
离散型随机变量:的一切可能的取值xi与对应的概率Pi(=xi)之积的和称为该离散型随机变量的数学期望,记为E(x)。数学期望是最基本的数学特征之一。它反映随机变量平均取值的大小。
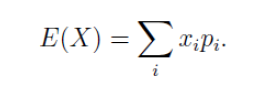
R程序:计算样本(1,2,3,7,21)的数学期望
> S mean(S)
[1] 6.8
连续型随机变量:若随机变量X的分布函数F(x)可表示成一个非负可积函数f(x)的积分,则称X为连续性随机变量,f(x)称为X的概率密度函数,积分值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









