









# -*- coding: utf-8 -*-
'''
Created on 2018年1月18日
@author: Jason.F
@summary: 特征抽取-PCA方法,无监督、线性
'''
import pandas as pd
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
#第一步:导入数据,对原始d维数据集做标准化处理
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns=['Class label','Alcohol','Malic acid','Ash','Alcalinity of ash','Magnesium','Total phenols','Flavanoids','Nonflavanoid phenols','Proanthocyanins','Color intensity','Hue','OD280/OD315 of diluted wines','Proline']
print ('class labels:',np.unique(df_wine['Class label']))
#print (df_wine.head(5))
#分割训练集合测试集
X,y=df_wine.iloc[:,1:].values,df_wine.iloc[:,0].values
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
#特征值缩放-标准化
stdsc=StandardScaler()
X_train_std=stdsc.fit_transform(X_train)
X_test_std=stdsc.fit_transform(X_test)
#第二步:构造样本的协方差矩阵
cov_mat=np.cov(X_train_std.T)#d=13维,构造13X13维的协方差矩阵
eigen_vals,eigen_vecs=np.linalg.eig(cov_mat)#计算线性矩阵的特征值和特征向量
print ('\nEigenvalues \n %s'%eigen_vals) #13个特征值
print (eigen_vecs.shape)#13X13的特征向量矩阵
#计算特征值占比,观察期方差贡献率,目标是寻找最大方差的成分
tot=sum(eigen_vals)
var_exp=[(i/tot) for i in sorted(eigen_vals,reverse=True)]
cum_var_exp=np.cumsum(var_exp)
plt.bar(range(1,14),var_exp,alpha=0.5,align='center',label='individual explained variance')
plt.step(range(1,14),cum_var_exp,where='mid',label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.show()
#第三部:选择前k个最大特征值对应的特征向量,构造k个特征项的映射矩阵W
eigen_pairs=[(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))]
eigen_pairs.sort(reverse=True)
w=np.hstack((eigen_pairs[0][1][:,np.newaxis],eigen_pairs[1][1][:,np.newaxis]))#选取前2个特征,构建13X2维的映射矩阵W
print ('Matrix W:\n',w)
#第四步:通过映射矩阵W将d=13维的输入数据集X转换到新的k=2维特征子空间
print (X_train_std[0].dot(w)) #转换一行,一个样本
X_train_pca=X_train_std.dot(w)#转换整个样本集,从13维到2维
X_test_pca=X_test_std.dot(w)
print (X_train_pca.shape)
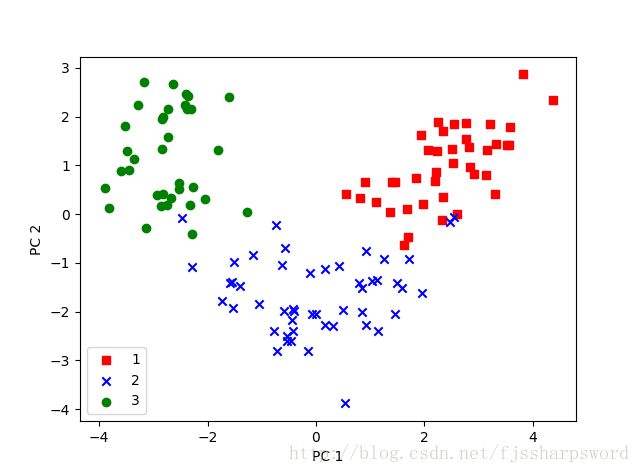
#用二维散点图可视化降维后的样本
colors=['r','b','g']
markers=['s','x','o']
for l,c,m in zip(np.unique(y_train),colors,markers):
plt.scatter(X_train_pca[y_train == l, 0],X_train_pca[y_train == l, 1],c=c, label=l, marker=m)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.show()
#第五步:转换后的数据集进行线性训练
lr=LogisticRegression()
lr.fit(X_train_pca,y_train)
print ('Training accuracy:',lr.score(X_train_pca, y_train))
print ('Test accuracy:',lr.score(X_test_pca, y_test))
结果:
('class labels:', array([1, 2, 3], dtype=int64))
Eigenvalues
[ 4.8923083 2.46635032 1.42809973 1.01233462 0.84906459 0.60181514
0.52251546 0.08414846 0.33051429 0.29595018 0.16831254 0.21432212
0.2399553 ]
(13L, 13L)
('Matrix W:\n', array([[ 0.14669811, 0.50417079],
[-0.24224554, 0.24216889],
[-0.02993442, 0.28698484],
[-0.25519002, -0.06468718],
[ 0.12079772, 0.22995385],
[ 0.38934455, 0.09363991],
[ 0.42326486, 0.01088622],
[-0.30634956, 0.01870216],
[ 0.30572219, 0.03040352],
[-0.09869191, 0.54527081],
[ 0.30032535, -0.27924322],
[ 0.36821154, -0.174365 ],
[ 0.29259713, 0.36315461]]))
[ 2.59891628 0.00484089]
(124L, 2L)
('Training accuracy:', 0.967741935483871)
('Test accuracy:', 0.98148148148148151)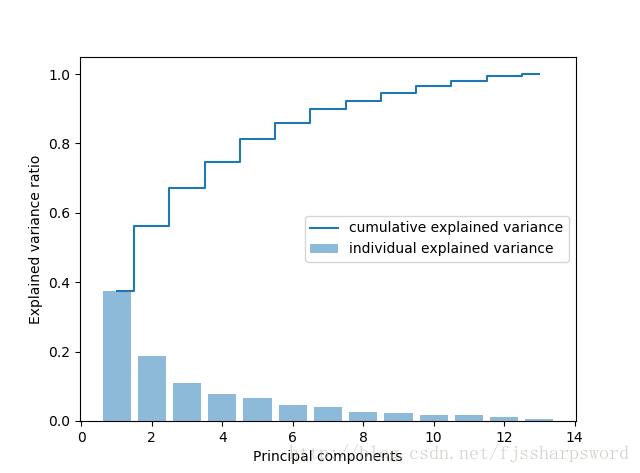















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









