 DeepseekV2MoE:混合专家模型的高效微调
DeepseekV2MoE:混合专家模型的高效微调








DeepseekV2MoE
flyfish
主要分析small版本
(mlp): DeepseekV2MoE(
(experts): ModuleList(
(0-63): 64 x DeepseekV2MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=1408, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=1408, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=1408, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=1408, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=1408, out_features=2048, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=1408, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekV2MLP(
(gate_proj): Linear(in_features=2048, out_features=2816, bias=False)
(up_proj): Linear(in_features=2048, out_features=2816, bias=False)
(down_proj): Linear(in_features=2816, out_features=2048, bias=False)
(act_fn): SiLU()
)
)
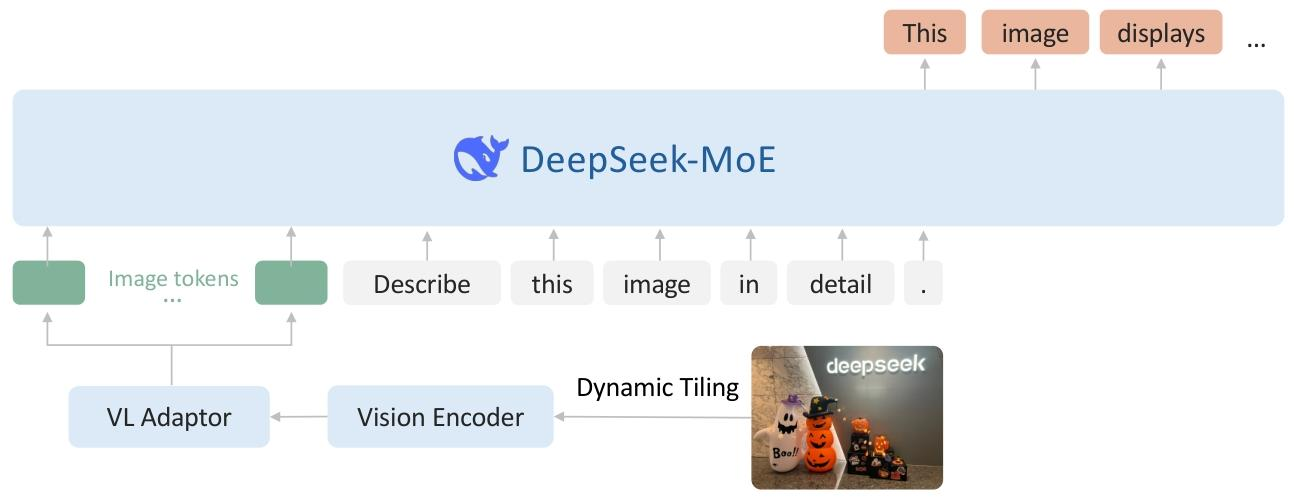
DeepSeek-VL2 概述
整体结构是一个类 LLaVA 的架构,其中包括一个视觉编码器、一个视觉语言适配器和一个基于 MoE 的大语言模型。
DeepSeek-VL2 由三个核心模块组成:(1)视觉编码器,(2)视觉语言适配器,以及(3)混合专家语言模型。在其前身的仅解码器 LLaVA 风格[54]架构的基础上,DeepSeek-VL2 引入了两项重大改进:动态分块策略和具有多头潜在注意力[53]的 DeepSeekMOE[20,86]语言模型。这些创新使得对高分辨率视觉输入和文本数据的处理更加高效。
动态分块策略。原始的 DeepSeek-VL 采用了混合视觉编码器,结合了用于在 384×384 分辨率下进行粗粒度特征提取的 SigLIP [106] 和用于在 1024×1024 分辨率下进行细粒度特征提取的 SAMB [35]。虽然这种融合方法生成了适合各种视觉语言任务的丰富视觉表示,但它受到固定的 1024×1024 分辨率限制。对于处理具有更高分辨率和极端纵横比的图像,例如在信息图问答(InfographicVQA)[67]、密集光学字符识别(dense OCR)和详细的视觉基础任务中发现的图像,这种限制尤其具有挑战性。
受最近视觉语言模型(VLMs)的进展启发,我们通过将高分辨率图像分割成图块来实现动态分块策略。这种方法能够使用单个 SigLIP-SO400M-384 视觉编码器[106]高效处理具有不同宽高比的各种高分辨率图像。预训练的 SigLIP 在 384×384 的基础分辨率下运行。为了适应不同的宽高比,我们定义了一组候选分辨率:CR={(m⋅384,n⋅384)∣m∈N,n∈N,1≤m≤n,mn≤9}C_{R}=\{(m\cdot384,n\cdot384)|m\in\mathbb{N},n\in\mathbb{N},1\leq m\leq n,mn\leq9\}CR={(m⋅384,n⋅384)∣m∈N,n∈N,1≤m≤n,mn≤9},其中m:nm:nm:n表示宽高比。对于大小为(H,W)(H,W)(H,W)的输入图像,我们计算将其调整为CRC_{R}CR中的每个候选分辨率所需的填充区域。我们选择使填充区域最小的分辨率mi⋅384×ni⋅384m_{i}\cdot384\times n_{i}\cdot384mi⋅384×ni⋅384。然后,将调整大小后的图像分成mi×nim_{i}\times n_{i}mi×ni个 384×384 像素的局部图块,再加上一个全局缩略图块。SigLIP-SO400M-384 视觉编码器处理所有(1+mi×ni)(1+m_{i}\times n_{i})(1+mi×ni)个图块,每个图块产生27×27=72927\times27=72927×27=729个 1152 维的视觉嵌入。为了提高计算效率和管理上下文长度,在处理多个(>2)图像时,我们禁用动态分块策略。
DeepseekV2MoE通过混合专家架构,结合门控网络和多个专家网络(包括共享专家网络),能够根据输入动态地选择合适的专家进行处理,提高模型的表达能力和处理复杂任务的效率。LoRA的使用使得在微调过程中可以更高效地更新模型参数。
整体结构
DeepseekV2MoE模块主要由三个部分组成:
- 专家网络集合(
experts):包含64个DeepseekV2MLP实例,用于对不同的输入部分进行处理。 - 门控网络(
gate):MoEGate模块,负责根据输入决定将输入分配给哪些专家网络进行处理。 - 共享专家网络(
shared_experts):一个DeepseekV2MLP实例,所有输入都可以使用该共享专家网络。
专家网络集合(experts)
(experts): ModuleList(
(0-63): 64 x DeepseekV2MLP(
...
)
)
ModuleList是PyTorch中用于存储多个子模块的容器。这里存储了64个DeepseekV2MLP专家网络,每个专家网络负责处理输入的一部分。
单个DeepseekV2MLP专家网络
(0-63): 64 x DeepseekV2MLP(
(gate_proj): lora.Linear(
...
)
(up_proj): lora.Linear(
...
)
(down_proj): lora.Linear(
...
)
(act_fn): SiLU()
)
每个DeepseekV2MLP包含三个线性层(gate_proj、up_proj、down_proj)和一个激活函数(act_fn):
gate_proj、up_proj、down_proj:- 这些是带有LoRA(Low - Rank Adaptation)的线性层。LoRA是一种用于高效微调预训练模型的技术,通过添加低秩矩阵来减少可训练参数的数量。
base_layer:原始的线性层,例如gate_proj的base_layer输入特征维度为2048,输出为1408。lora_dropout:用于防止过拟合的Dropout层,失活概率p = 0.05。lora_A和lora_B:LoRA引入的低秩矩阵,用于对原始线性层的输出进行调整。例如lora_A将2048维输入映射到8维,lora_B再将8维映射回1408维。lora_embedding_A、lora_embedding_B、lora_magnitude_vector:用于存储LoRA相关参数的字典,当前为空。
act_fn:激活函数为SiLU(Sigmoid Linear Unit),用于引入非线性。
门控网络(gate)
(gate): MoEGate()
MoEGate负责计算每个专家网络的权重,根据输入决定将输入分配给哪些专家网络,以实现动态路由。
共享专家网络(shared_experts)
(shared_experts): DeepseekV2MLP(
(gate_proj): Linear(in_features=2048, out_features=2816, bias=False)
(up_proj): Linear(in_features=2048, out_features=2816, bias=False)
(down_proj): Linear(in_features=2816, out_features=2048, bias=False)
(act_fn): SiLU()
)
共享专家网络也是一个DeepseekV2MLP,但与专家网络集合中的DeepseekV2MLP不同:
- 其线性层是普通的
Linear层。 gate_proj和up_proj将2048维输入映射到2816维,down_proj再将2816维映射回2048维。- 同样使用SiLU作为激活函数。
专家网络(experts)
1. 提升模型的表达能力
- 处理多样化的数据模式:不同的专家网络可以专注于学习输入数据中的不同模式或特征。在一个复杂的任务里,数据可能包含多种不同类型的信息,例如在视觉 - 语言任务中,图像可能有不同的场景、物体特征,文本也有不同的语义和语法结构。64 个
DeepseekV2MLP专家网络可以分别学习这些多样化的模式,使得模型能够更全面、细致地对输入进行理解和处理,从而提升模型整体的表达能力。 - 增加模型复杂度:相比于单一的神经网络,多个专家网络的组合能够构建出更为复杂的函数映射关系。每个
DeepseekV2MLP专家网络都可以看作是一个独立的子模型,它们各自学习不同的函数,然后通过门控网络将这些子模型的输出进行整合,最终实现对复杂输入 - 输出关系的建模。
2. 实现动态路由和高效计算
- 动态分配输入:门控网络(
MoEGate)会根据输入数据的特征,为每个专家网络计算一个权重,然后根据这些权重将输入动态地分配给不同的专家网络进行处理。例如,对于某些特定的输入,门控网络可能会将其主要分配给擅长处理这类输入的专家网络,而其他专家网络则可以处理其他类型的输入。这样可以避免让所有的专家网络都对每个输入进行处理,从而减少不必要的计算,提高计算效率。 - 稀疏激活:在 MoE 架构中,并非所有的专家网络都会在每次输入时都被激活。只有那些被门控网络选中的专家网络才会参与计算,这种稀疏激活的方式可以显著减少计算量和内存占用,特别是在处理大规模数据时,优势更加明显。
3. 增强模型的泛化能力
- 减少过拟合:不同的专家网络可以从不同的角度对数据进行学习,这相当于对数据进行了多种不同方式的抽象和表示。通过这种方式,模型可以学习到数据的更本质特征,而不是仅仅记住训练数据中的噪声和细节,从而减少过拟合的风险,提高模型在未知数据上的泛化能力。
- 集成学习效果:多个专家网络的输出经过整合后得到最终的模型输出,类似于集成学习的思想。集成学习通过组合多个弱学习器来构建一个更强的学习器,在 MoE 架构中,每个专家网络可以看作是一个弱学习器,它们的组合可以提高模型的稳定性和泛化性能。
4. 结合 LoRA 实现高效微调
- 参数高效微调:代码中的专家网络采用了 LoRA(Low - Rank Adaptation)技术。在微调预训练模型时,传统的全量参数微调需要更新模型的所有参数,计算量和存储需求都很大。而 LoRA 只需要更新少量的低秩矩阵参数(
lora_A和lora_B),大大减少了可训练参数的数量,从而实现高效的微调。这样在不改变原始模型大部分参数的情况下,让专家网络能够快速适应新的任务和数据。



















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











