







前言
很偶然的一个机会,在用拉钩app的时候发现了一个上拉加载更多的效果,就是列表到达最底部时继续上拉,底部文字会由点击加载变成松开载入。我感觉这个效果不错,所以给XRefreshView加了这个功能,先上图。

用法说明
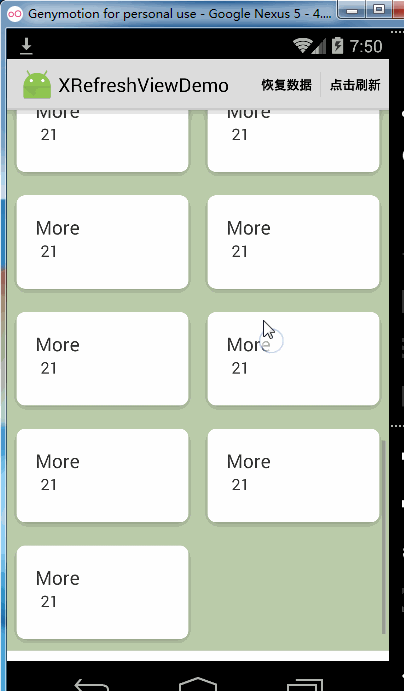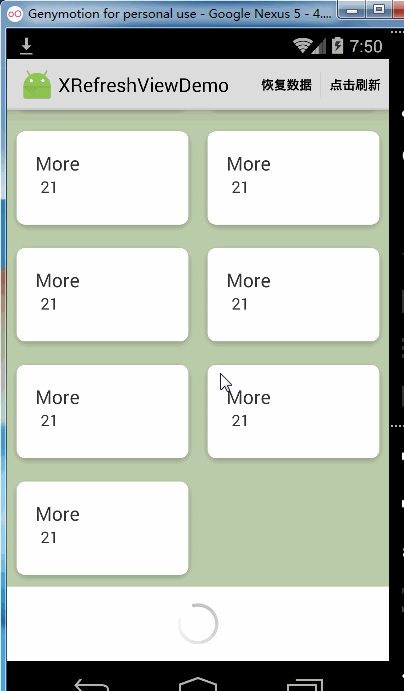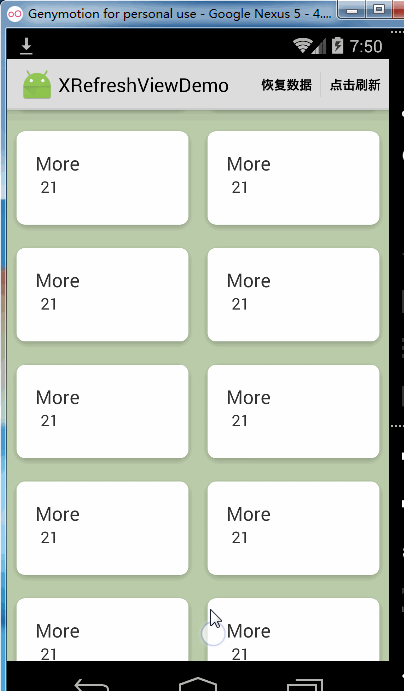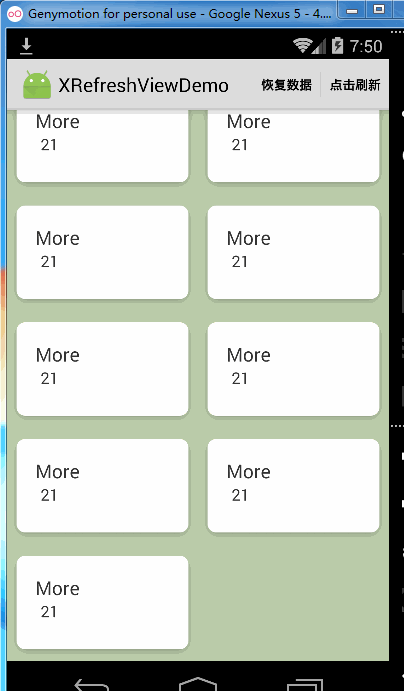
松开加载更多的功能只有在Recyclerview非自动加载更多的时候才会有作用,Recyclerview自动加载的效果是这样的:
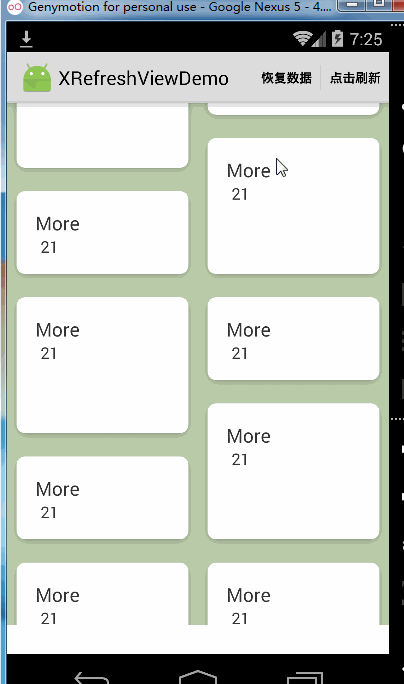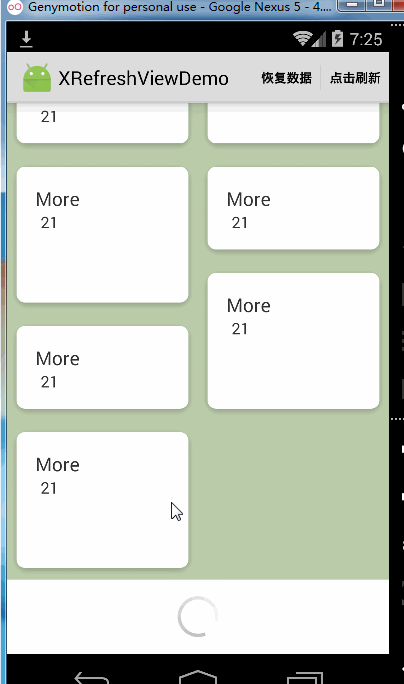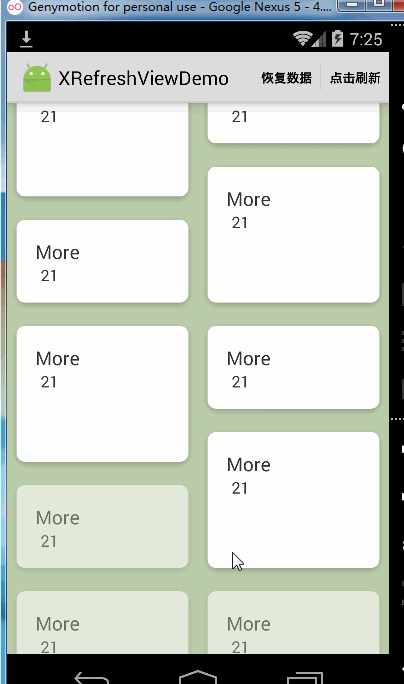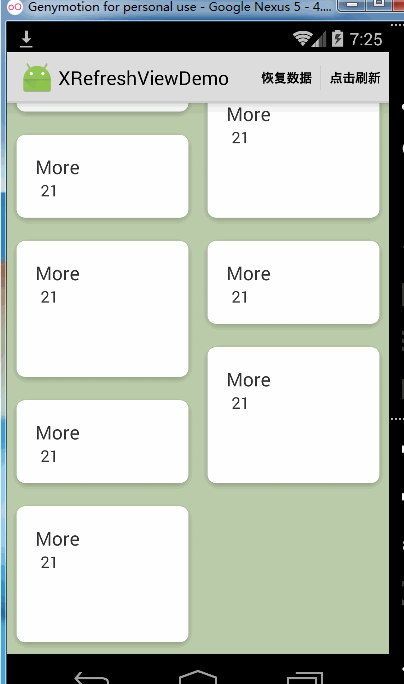
松开加载更多默认是开启的,如果不想用这个功能想关掉的话,可以这样做:
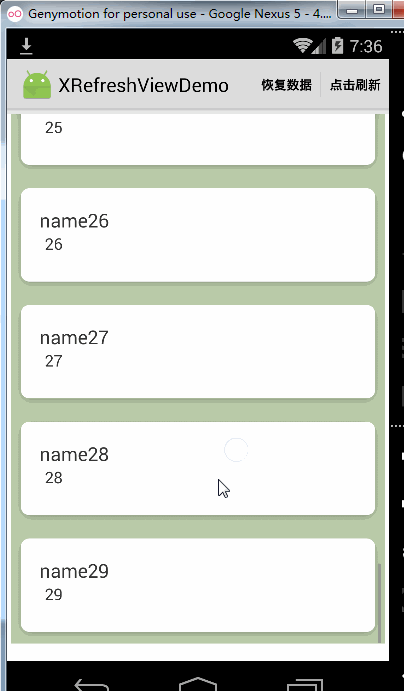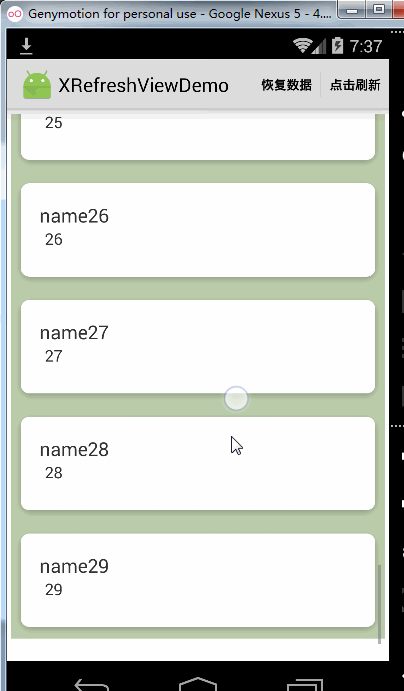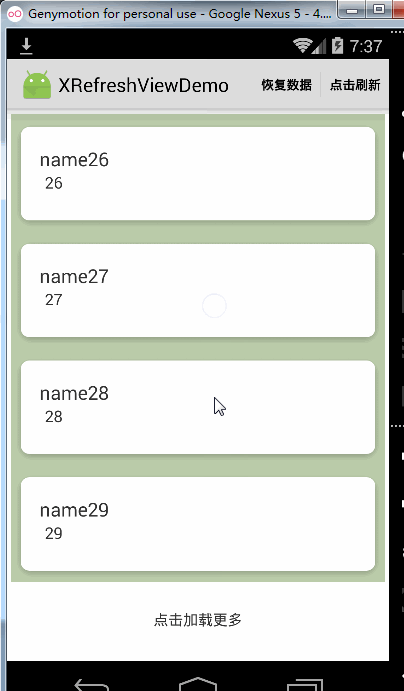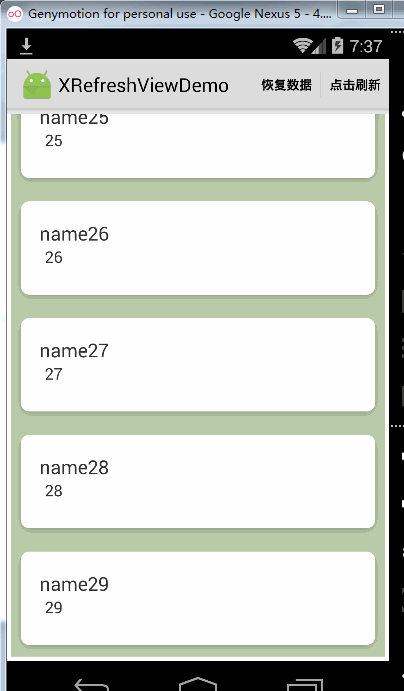
xRefreshView.enableReleaseToLoadMore(false);效果如下:
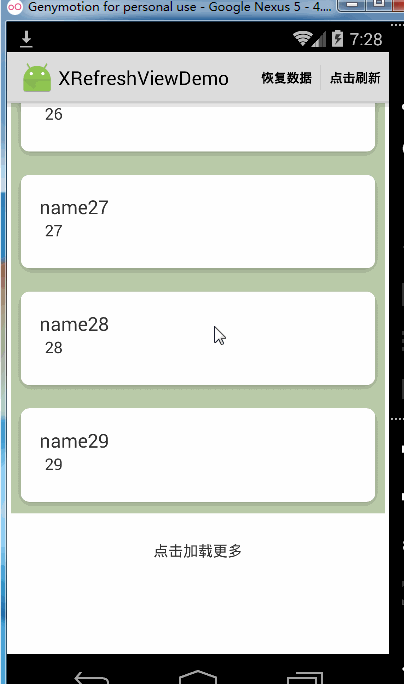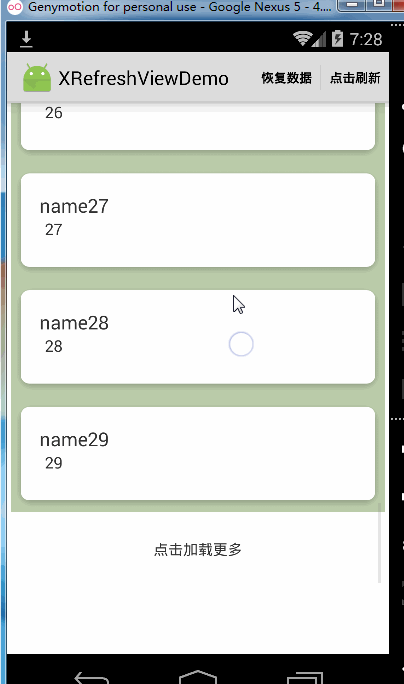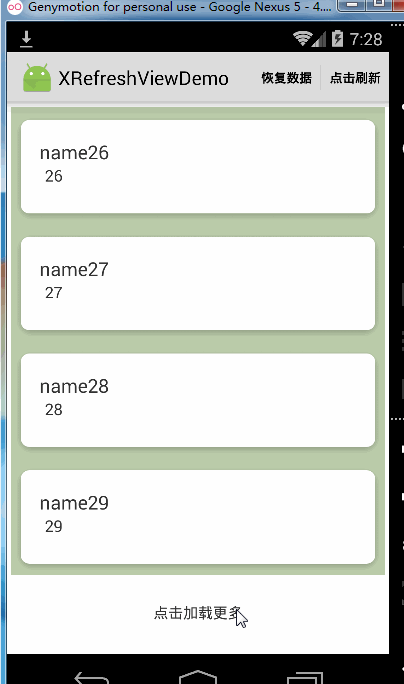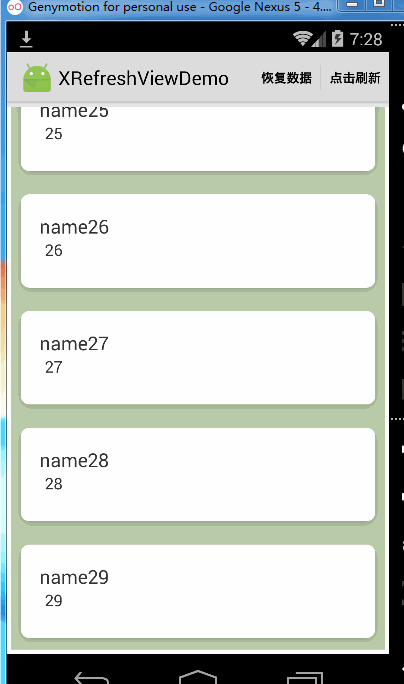
可以看到,当关掉松开加载更多的功能时Recyclerview到达底部仍然是可以继续向上拉起的,但是如果你完全不想让Recyclerview到达底部被继续往上拉起可以这样做:
xRefreshView.enableRecyclerViewPullUp(false);这时的效果是这样的:
这时候完全不能往上拉起Recyclerview了,同时松开加载更多的功能也不能用了。
但是如果你只是想在数据加载完成以后才关闭到达底部继续往上拉的功能,而在数据没有加载完成的时候能使用松开加载更多的功能的话,你可以这样做:
xRefreshView.enablePullUpWhenLoadCompleted(false);效果如下:
以上只是XRefreshView功能的一小部分,XRefreshView支持任何view的下拉刷新和上拉加载更多,不过如果要做上拉加载更多的功能的话我更推荐用Recyclerview,因为XRefreshView对Recyclerview做了特别的适配,上拉加载更多的效果是最好的。其他的view只使用下拉刷新就好了。
一些关于XRefreshView的博客
最后
以上就介绍完了,如果感兴趣的话,可以前往XRefreshView了解更多。如果有意见或者疑问可以留言或者在github找到我。















 5797
5797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









