







本文简记我在学习自动微分相关技术时遇到的知识点。
反向传播和自动微分
以 NN 为代表的深度学习技术展现出了强大的参数拟合能力,人们通过堆叠固定的 layer 就能轻松设计出满足要求的参数拟合器。
例如,大部分图神经网络均基于消息传递的架构。在推理阶段,用户只需给出分子坐标及原子类型,就能得到整个分子的性质。因此其整体架构与下图类似:

在模型设计阶段,我们用 pytorch 即可满足大部分需求,以 schnetpack 为例:
- 我们
from torch import nn导入了设计 nn 常用的模块。在初始化模型时,我们直接继承了 pytorch 内置的模块class AtomisticModel(nn.Module) - 有一些函数是重新编写的,例如激活函数 shiftedsoftplus
我们可以看到,模型的整体框架依然是基于 pytorch 的,但针对具体的应用场景,我们做了很多优化。
一方面,使用 pytorch 可以帮助我们快速建立类似上图的模型网络,pytorch 会自动执行梯度的反向传播。从 loss function 开始,逐层递进直至输入层。pytorch 还会帮助我们完成整个网络的参数迭代,学习率的迭代等等。。。
另一方面,针对一些特殊的需求,用户需要自行 DIY,完成需要的功能。
这其中隐含着,用户在程序设计时灵活性与便利性之间的折中。
注意到,刚才提到了梯度的反向传播,事实上,这种常用算法只是自动微分算法中的一种。引用 Gemini 的一个例子:
- 反向传播好像是计算小山丘斜率(仅限于 NN)的一种算法;
- 自动微分则可以计算除了小山丘以外的所有物品的斜率(涵盖所有链式求导法则);
写到这里,自动微分技术的应用场景就很好理解了:
- 有一些应用场景不适合无脑堆叠 NN,但仍然需要优化参数,此时
from torch import nn就不管用了,套用固定模版已经很难带来便利性; - 由于整个网络的框架已经不再是上图所示,规整的一层层的 NN 结构,反向传播算法就不再适用于参数优化了,需要更加灵活的自动微分方法;
pytorch 与 jax
我们可以将参数优化的相关框架归结为两个应用场景:
- 用户调用标准函数,搭建层级式标准 NN;
- 用户自行设计函数,搭建非标准拟合器(仍需优化参数)
针对第一个场景,我们可以使用 pytorch,因为 pytorch 对常用网络架构封装很好。
针对第二个场景,使用 pytorch 会更加繁琐,此时可以切换为 jax ,因为 jax 对用户自定义函数形式更加友好,其内置自动微分算法使用起来更加方便。
除了应用场景的区别外,二者还有以下几个区别:
- pytorch 支持静态/动态计算图,而 jax 仅支持静态图
- pytorch debug 起来更加方便
- jax 针对 GPU, TPU 等硬件优化更多,结合其 JIT(Just In Time) 特性,jax 模型一般比 pytorch 模型快得多
- 二者间的相互转换难度不大(参见:一文打通PyTorch与JAX)
AI for Science 领域内三个应用案例
DMFF
余旷老师在他的系列博文里系统阐释了为什么 DMFF 要基于 jax 开发(参见:漫谈分子力场、自动微分与DMFF项目:4. DMFF和JAX概述)
总结一下,使用 jax 的原因有以下几点:
- 传统分子力场的形式不适合用 NN 建模
- 为方便大家理解,我举一个中学物理的例子。苹果从树上落下,遵从自由落体运动,位移随时间变化的规律:h=1/2 * g * t^2, 其中 g 作为引力常数就是需要通过多次落体实验测定的量。我们当然可以用多层 NN 拟合这一参数,但假如我们已经知道了这样一个表达式,此时直接使用该表达式即可。
- 传统分子力场就是高度参数化的方程,发展至今已经有了一套函数形式,无需从头用 NN 的形式拟合
- 反向传播算法只适用与 NN,不适应上述高度参数化的方程,但优化力场参数仍需要自动微分技术
- 计算原子受力,整个盒子的维里均需要微分技术,使用 jax 编程会更加方便
- jax 性能更高,速度快
- jax 可拓展性好
- 余旷老师在 漫谈分子力场、自动微分与DMFF项目:5. DMFF中势函数的生成和拓展 举了一个例子,使用 DMFF 能有效复用前人开发势函数模块,无需从头造轮子
E3x
在 Oliver T. Unke 近期的一篇论文中,作者介绍了名为 E3x 的神经网络框架,对标 pytorch_geometric。
其目的在于,方便用户设计具有 E3 等变性的图神经网络。
使用 E3x 能将所有 AI for Science 领域的 GNN 从 pytorch 迁移至 jax 框架,再结合 jax-MD,获得大幅性能提升。
作者在另一篇论文中透露了这种改造的效果:
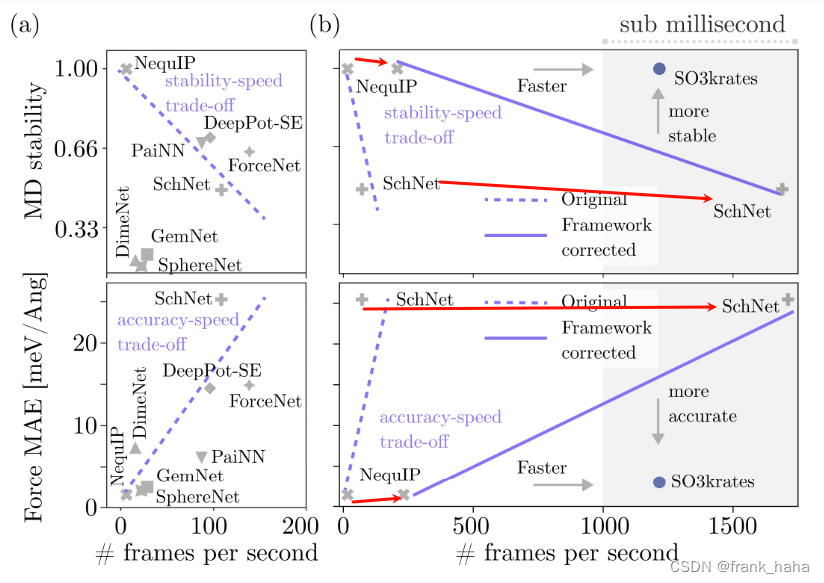
在稳定性和受力误差不变的情况下,NequIP 提速 28 倍,SchNet 提速 15 倍。那么,E3x 做了哪些关键改动呢?
-
e3x 对不可约张量进行了压缩,降低了其稀疏性

-
e3x 设计了开箱即用的激活函数,全连接层、张量层等,这些网络结构都是 E3 等变的
DLDFPT
神经网络与密度泛函围绕理论的结合,论文地址
这是李贺大神今年上半年的一篇 PRL,说实话,我也没看懂。我只是理解到:
- 传统的 DFPT 理论在计算某一个矩阵的时候遇到了计算瓶颈;
- 使用自动微分技术能绕开这一瓶颈















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









