






本篇文章利用到的数据是mne包中的多导睡眠图(PSG)数据进行睡眠阶段分类
作者处于大二阶段,文中解读字数较少,可能一些东西讲的不清楚,大家直接看代码就行,这也是本人第一次关于脑电数据的实战,参考MNE文档官方的例子,链接如下:
 https://mne.tools/stable/auto_tutorials/clinical/60_sleep.html
https://mne.tools/stable/auto_tutorials/clinical/60_sleep.html希望通过本文能帮助你了解脑电数据分类的大致流程
一、数据集介绍
给定Sleep Physionet数据集2 3中的两个受试者,我们默认命名为Alice和Bob(实际上可能并不是这两个人),从Alice的数据中预测出Bob的睡眠有多少。这是一个监督式的多类分类任务来解决,从30秒的数据中5个可能阶段预测睡眠阶段
利用dataset包中的sleep_physionet.age.fetch_data()加载数据。
-PSG.edf 包含多导睡眠图。来自脑电图头盔的原始数据
-Hypnogram.edf 包含专家记录的注释
将这两者结合在一个 mne.io.Raw 对象中,然后我们可以根据注释的描述提取事件以获得纪元
Sleep Physionet 数据集使用 8 个标签进行注释:Wake (W)、Stage 1、Stage 2、Stage 3、Stage 4,对应于从浅睡眠到深度睡眠的范围,REM 睡眠 (R),其中 REM 是快速眼动睡眠、运动 (M) 和任何未评分片段的阶段 (?) 的缩写
但是这里我们只处理五个阶段,分别是:Wake (W)、stage1、stage2、stage3/4 和REM sleep (R)
二、数据处理与特征工程
1.导包
from mne.datasets.sleep_physionet.age import fetch_data
import mne
import numpy as np
import matplotlib.pyplot as plt
from mne.time_frequency import psd_array_welch
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score2.读取PSG数据并创建对象
# 对实验对象进行ALICE BOB进行临时命名
ALICE,BOB = 0,1
# 加载两位受试者的实验数据 recording表示夜间记录的编号 有效值为[1] [2] [1,2]
[alice_files,bob_files] = fetch_data(subjects=[ALICE,BOB],recording=[1])
# 通道名称
mapping = {'EOG horizontal': 'eog',
'Resp oro-nasal': 'misc',
'EMG submental': 'misc',
'Temp rectal': 'misc',
'Event marker': 'misc'}
# 读取ALICE的edf文件
raw_train = mne.io.read_raw_edf(alice_files[0])
annot_train = mne.read_annotations(alice_files[1])
print(raw_train)
print(annot_train)
print(alice_files[0])
raw_train.set_annotations(annot_train,emit_warning=False)
raw_train.set_channel_types(mapping)
# 绘制空0s开始 时间窗口为40s的连续通道数据波形图
raw_train.plot(duration=40,scalings='auto')
plt.show()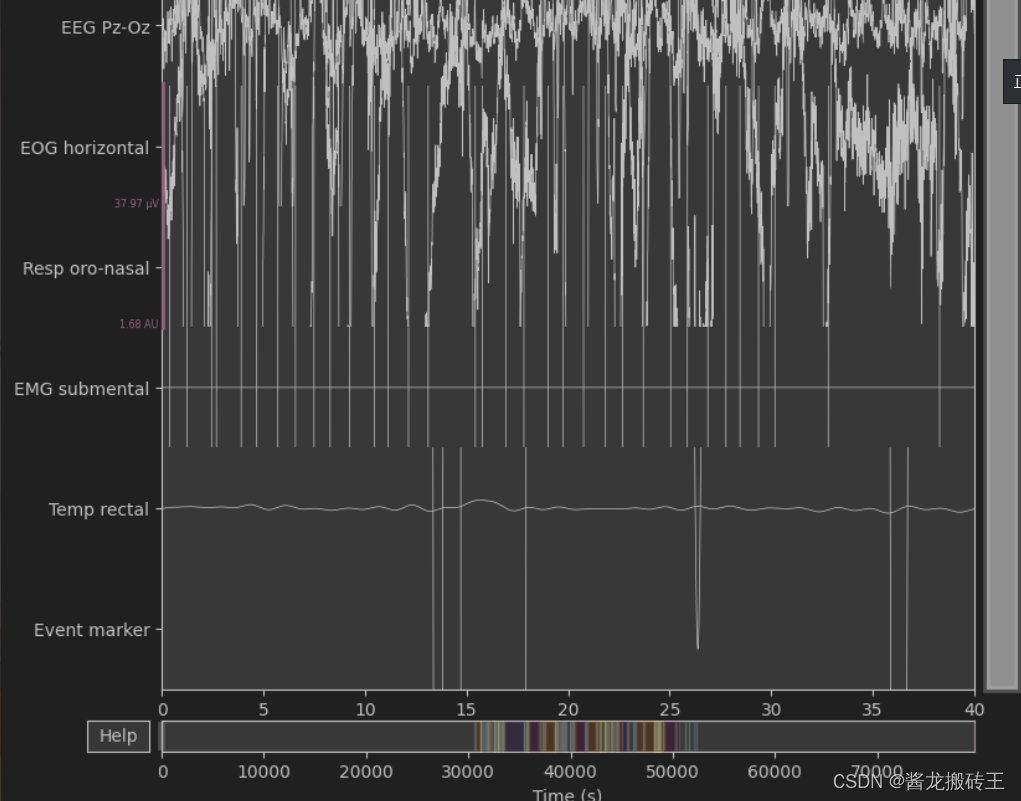
3.绘制睡眠与事件的图像
利用绘图直观地得出事件的分布
#进行睡眠事件与事件映射
annotation_desc_2_event_id = {'Sleep stage W': 1,
'Sleep stage 1': 2,
'Sleep stage 2': 3,
'Sleep stage 3': 4,
'Sleep stage 4': 4,
'Sleep stage R': 5
}
events_train,_ = mne.events_from_annotations(
raw_train,event_id=annotation_desc_2_event_id,chunk_duration=30
)
# 自定义事件标签
event_id = {'Sleep stage W': 1,
'Sleep stage 1': 2,
'Sleep stage 2': 3,
'Sleep stage 3/4': 4,
'Sleep stage R': 5
}
# 绘制事件数据
mne.viz.plot_events(events_train,event_id=event_id,sfreq=raw_train.info['sfreq'])
# 保留颜色代码以便进一步绘制
stage_colors = plt.rcParams['axes.prop_cycle'].by_key()['color']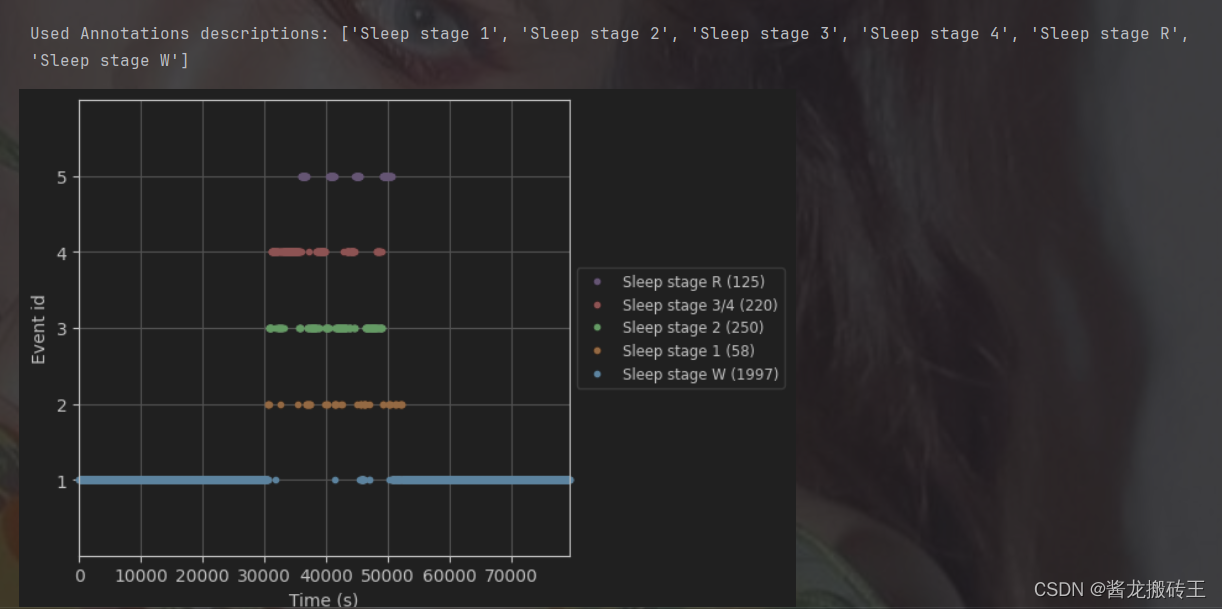
4.创建Epoch对象
tmax = 30 - 1 / raw_train.info['sfreq']
# 所创建的是时间从tmin=0开始,到tmax为止epochs
epochs_train = mne.Epochs(raw=raw_train,events=events_train,event_id=event_id,tmin=0,tmax=tmax,baseline=None)
print(epochs_train)
raw_test = mne.io.read_raw_edf(bob_files[0])
annot_test = mne.read_annotations(bob_files[1])
raw_test.set_annotations(annot_test,emit_warning=False)
raw_test.set_channel_types(mapping)
events_test,_ = mne.events_from_annotations(raw_test,event_id=annotation_desc_2_event_id,chunk_duration=30)
epochs_test = mne.Epochs(raw=raw_test,events=events_test,event_id=event_id,tmin=0,tmax=tmax,baseline=None)
print(epochs_test)
print(epochs_test.get_data)
进行功率谱密度(PSD)图像的绘制
fig,(ax1,ax2) = plt.subplots(ncols=2)
stages = sorted(event_id.keys())
for ax,title,epochs in zip([ax1,ax2],['Alice','Bob'],[epochs_train,epochs_test]):
for stage,color in zip(stages,stage_colors):
epochs[stage].plot_psd(area_mode=None,color=color,ax=ax,fmin=0.1,fmax=20,show=False,average=True,spatial_colors=False)
ax.set(title=title,xlabel='Frequency(HZ)')
ax2.set(ylabel='uV^2/hz(dB)')
plt.tight_layout()
plt.show()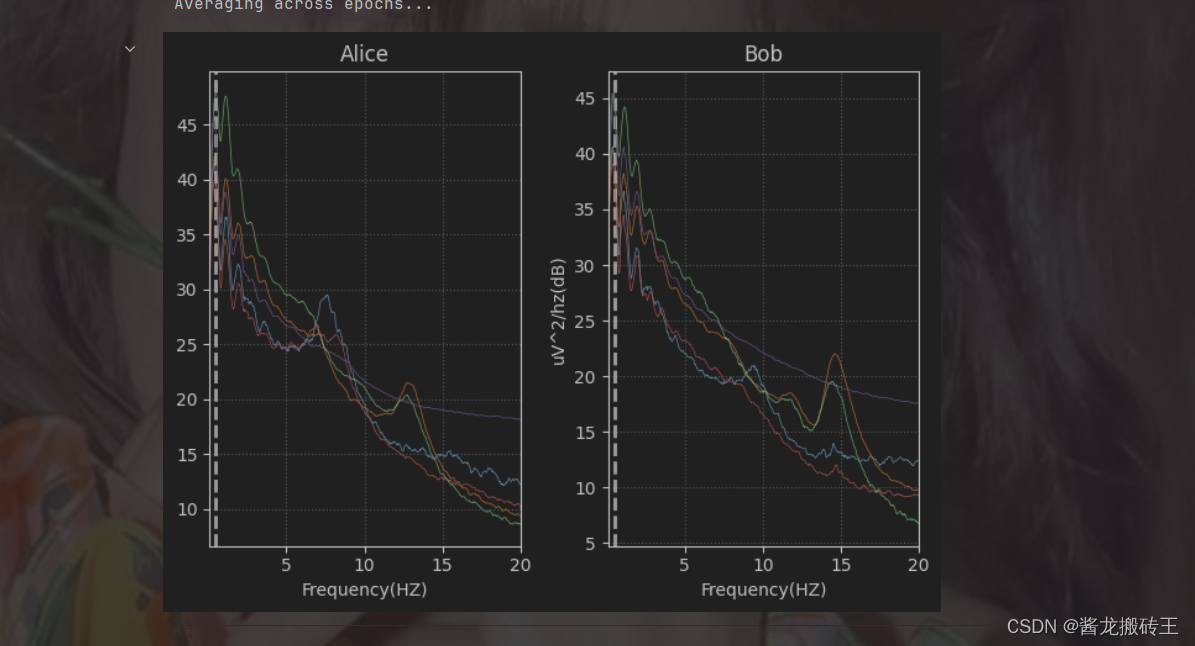 三、从python函数设计scikit-learn转换器
三、从python函数设计scikit-learn转换器
1.设计一个函数用于Epochs的处理
def eeg_power_band(epochs):
FREQ_BANDS = {
'delta': [0.5,4.5],
'theta': [4.5,8.5],
'alpha': [8.5,11.5],
'sigma': [11.5,15.5],
'beta': [15.5,30]
}
spectrum = epochs.compute_psd(picks='eeg',fmin=0.5,fmax=30.0)
psds,freqs = spectrum.get_data(return_freqs=True)
# 归一化 PSDs
psds /= np.sum(psds,axis=-1,keepdims=True)
X = []
for fmin,fmax in FREQ_BANDS.values():
psds_band = psds[:,:,(freqs >= fmin) & (freqs < fmax)].mean(axis=-1)
X.append(psds_band.reshape(len(psds),-1))
return np.concatenate(X,axis=1)2.构造pipe
将函数和随机森林分类器注入到pipe当中构建出一个管道,并利用Bob的数据进行模型评估得出准确率,该过程运行的事件可能比较长。
利用循环遍历不同的param得到树木的棵树对精确度的影响,并将其存储在列表当中
params = [10,20,30,40,50,60,70,80,90,100,110,120,130,140,150]
acc_list = []
for param in params:
pipe = make_pipeline(FunctionTransformer(eeg_power_band,validate=False),RandomForestClassifier(n_estimators=param,random_state=42))
# 训练
y_train = epochs_train.events[:,2]
pipe.fit(epochs_train,y_train)
# 预测
y_pred = pipe.predict(epochs_test)
# 评估准确率
y_test = epochs_test.events[:,2]
acc = accuracy_score(y_test,y_pred)
acc_list.append(acc)
绘制出树木棵数与分类器的准确率之间的关系
plt.plot(params,acc_list)
plt.show()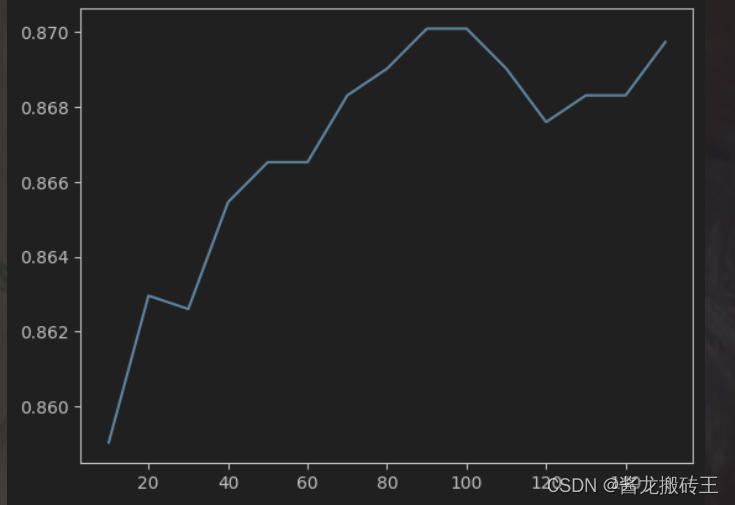
四、总结与思考
是否利用SVM、CSP、ICA去伪迹得到的效果会更好呢?这个是后面继续做的改进与测试,争取提高获取较高准确率。
本文只是简单地对脑电数据进行处理与分类预测,欢迎大家发表看法。最后,致敬脑机领域的所有人。

















 4826
4826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









