







一、学习实现
(注,本文中的截图参考夏宇闻的《verilog 数字系统设计教程》第三版)
两个数相乘
1、计算方式如下:

转变为硬件实现:
定义一个乘法单元(MU,multiple unit)
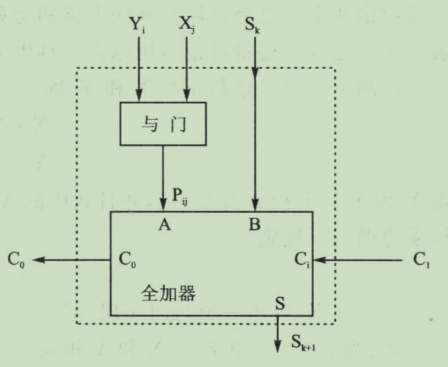
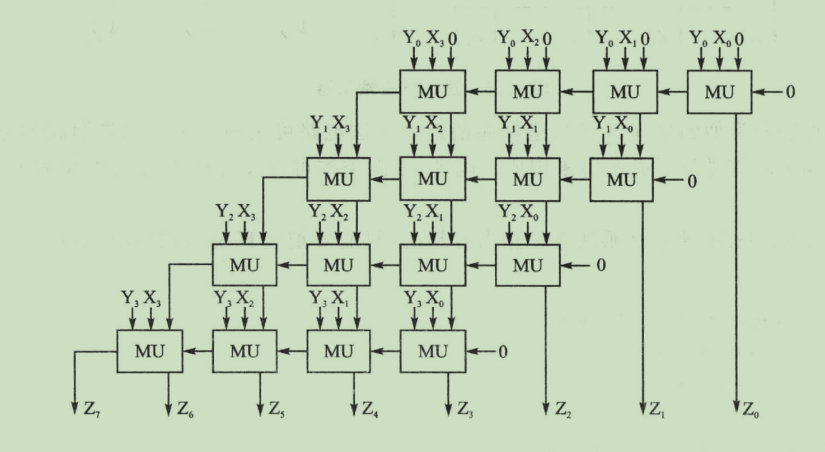
则乘法计算方式转变为如下结构:
2、verilog 实现
`timescale 1ns / 1ps
module add(
input A,
input B,
input Cin,
output S,
output Cout
);
assign S = (A ^ B) ^ Cin;
assign Cout = (A & Cin) | (A & B) | (B & Cin);
endmodule
module mu(
input Y,
input X,
input Sin,
input Cin,
output Cout,
output Sout
);
wire Pij;
assign Pij = X & Y;
add add1(
.A(Pij),
.B(Sin),
.Cin(Cin),
.S(Sout),
.Cout(Cout)
);
endmodule
module mul_self(
input [3:0] X,
input [3:0] Y,
output [7:0] Z
);
/*
*------------->0-6
|
|
|
|
V
0-3
*/
wire
C03, C04, C05, //C06 = 0,
C12, C13, C14, //C15 = 0,
C21, C22, C23, //C24 = 0,
C30, C31, C32; //C33 = 0;
wire
//S03=0, s04=0, S05=0, S06=0,
S12, S13, S14, S15,
S21, S22, S23, S24,
S30, S31, S32, S33;
mu mu06(.Y(Y[0]), .X(X[0]), .Sin(1'b0), .Cin(1'b0), .Cout(C05), .Sout(Z[0]) );
mu mu05(.Y(Y[0]), .X(X[1]), .Sin(1'b0), .Cin(C05), .Cout(C04), .Sout(S15) );
mu mu04(.Y(Y[0]), .X(X[2]), .Sin(1'b0), .Cin(C04), .Cout(C03), .Sout(S14) );
mu mu03(.Y(Y[0]), .X(X[3]), .Sin(1'b0), .Cin(C03), .Cout(S12), .Sout(S13) );
mu mu15(.Y(Y[1]), .X(X[0]), .Sin(S15), .Cin(1'b0), .Cout(C14), .Sout(Z[1]) );
mu mu14(.Y(Y[1]), .X(X[1]), .Sin(S14), .Cin(C14), .Cout(C13), .Sout(S24) );
mu mu13(.Y(Y[1]), .X(X[2]), .Sin(S13), .Cin(C13), .Cout(C12), .Sout(S23) );
mu mu12(.Y(Y[1]), .X(X[3]), .Sin(S12), .Cin(C12), .Cout(S21), .Sout(S22) );
mu mu24(.Y(Y[2]), .X(X[0]), .Sin(S24), .Cin(1'b0), .Cout(C23), .Sout(Z[2]) );
mu mu23(.Y(Y[2]), .X(X[1]), .Sin(S23), .Cin(C23), .Cout(C22), .Sout(S33) );
mu mu22(.Y(Y[2]), .X(X[2]), .Sin(S22), .Cin(C22), .Cout(C21), .Sout(S32) );
mu mu21(.Y(Y[2]), .X(X[3]), .Sin(S21), .Cin(C22), .Cout(S30), .Sout(S31) );
mu mu33(.Y(Y[3]), .X(X[0]), .Sin(S33), .Cin(1'b0), .Cout(C32), .Sout(Z[3]) );
mu mu32(.Y(Y[3]), .X(X[1]), .Sin(S32), .Cin(C32), .Cout(C31), .Sout(Z[4]) );
mu mu31(.Y(Y[3]), .X(X[2]), .Sin(S31), .Cin(C31), .Cout(C30), .Sout(Z[5]) );
mu mu30(.Y(Y[3]), .X(X[3]), .Sin(S30), .Cin(C30), .Cout(Z[7]), .Sout(Z[6]) );
endmodule
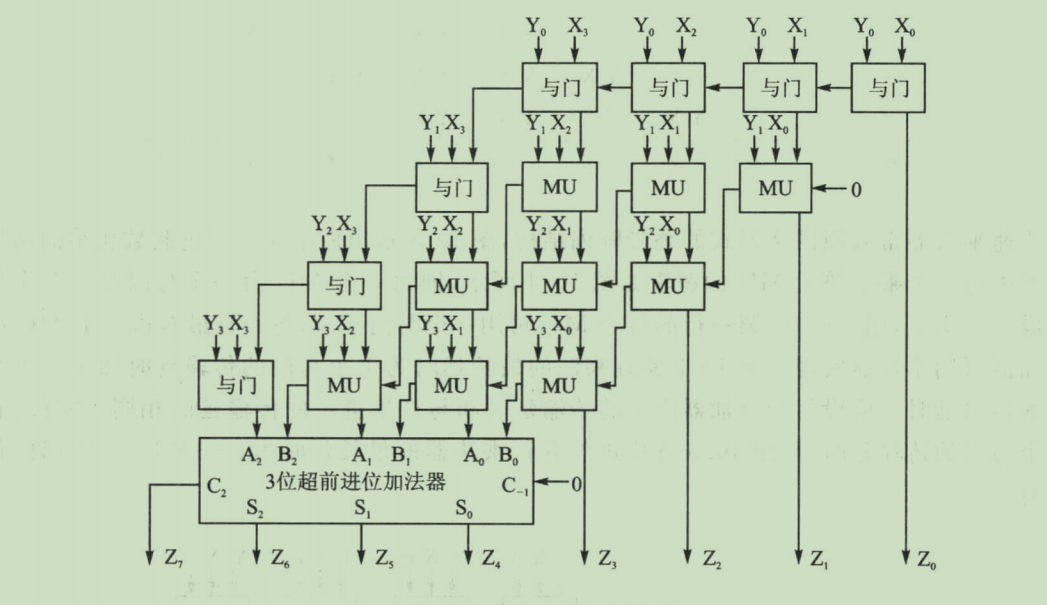
完全按照图示结构进行实现
3、testbench
`timescale 1ns / 1ps
module mul_self_tb(
);
reg [3:0] X;
reg [3:0] Y;
wire [7:0] Z;
mul_self mul_self1(
.X(X),
.Y(Y),
.Z(Z)
);
initial begin
X = 15;
Y = 2;
# 10;
$display("X = %d, Y = %d, Z = %d",X,Y,Z);
X = 0;
Y = 2;
# 10;
$display("X = %d, Y = %d, Z = %d",X,Y,Z);
end
endmodule
测试结果

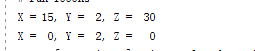
可以看到结果正确
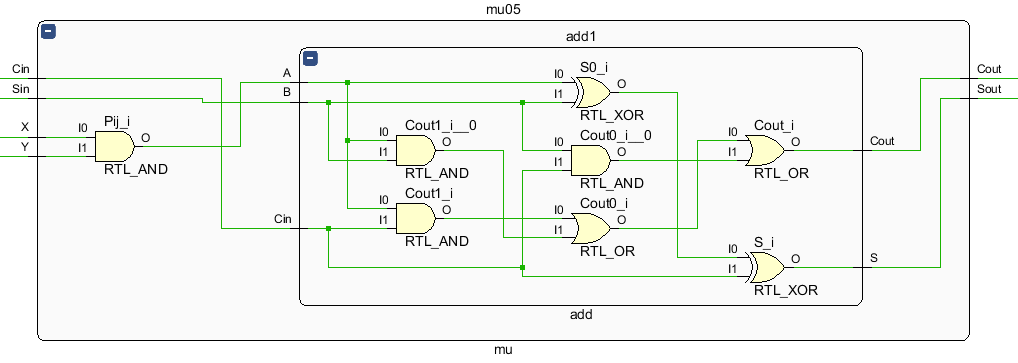
4、RTL
MU单元
整体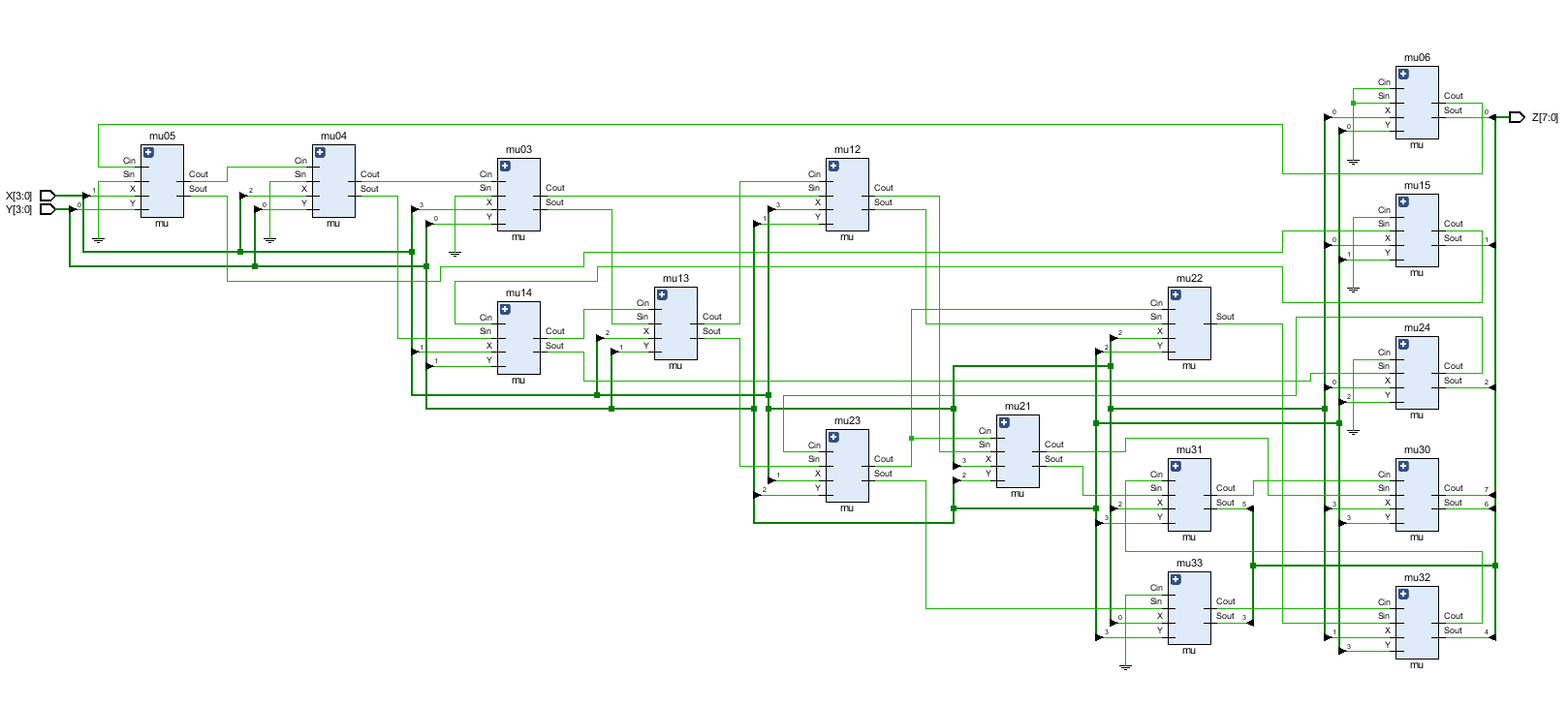
5、综合
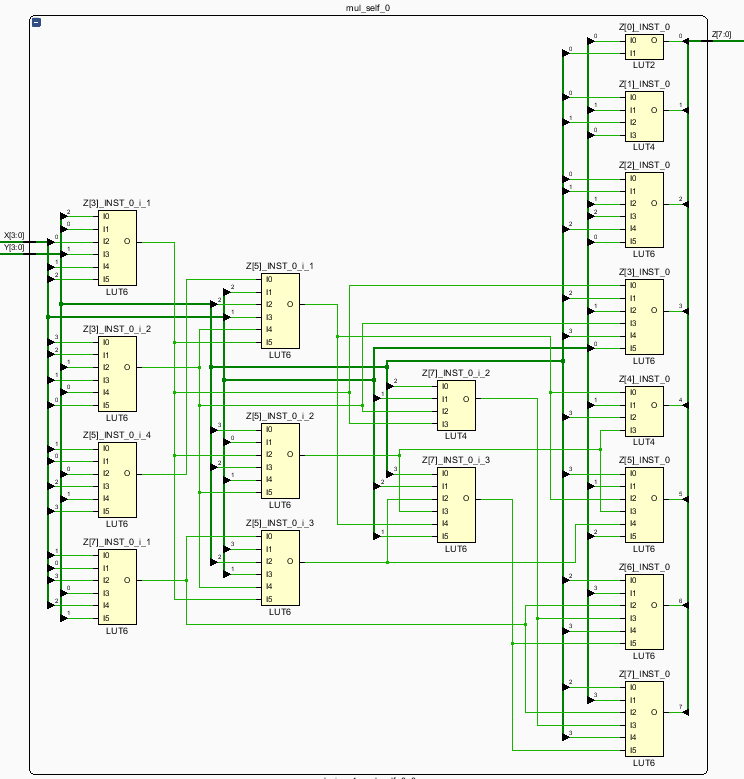
17个LUT实现的
6、实现
17个LUT实现的
二vivado编译实现
1、verilog代码
`timescale 1ns / 1ps
module mul(
input [3:0] X,
input [3:0] Y,
output [7:0] Z
);
assign Z = X * Y;
endmodule2、RTL

3、综合
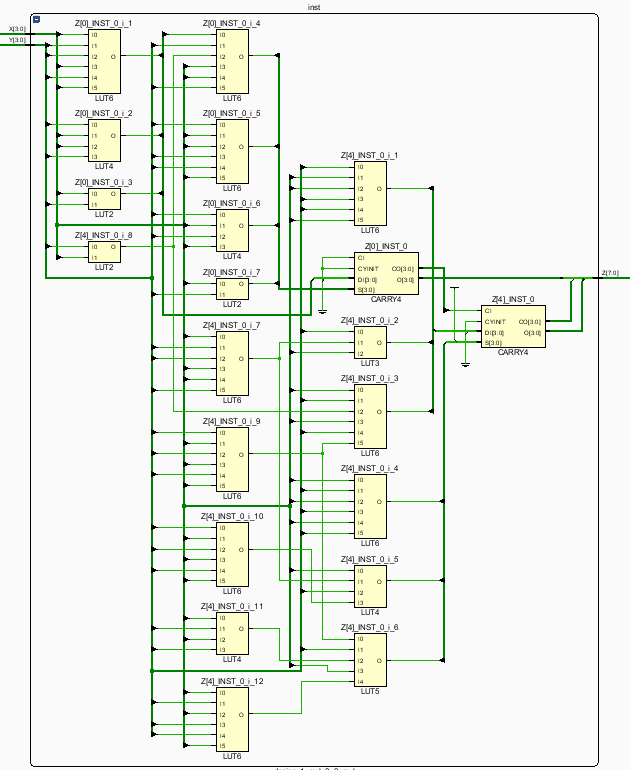
上面综合结果最终消耗了19个LUT和2个CARRY4,与进位节省乘法器相似,如下图
4、实现
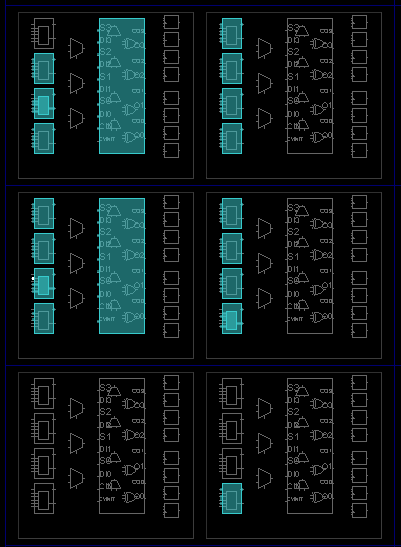
最终实现由16个LUT组成,这是由于部分LUT被实现到同一个LUT中,如下:

其中INST_0_i_5和INST_0_i_2都被实现到同一个LUT中,所有最终消耗16个LUT。















 4777
4777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









