







YOLO-V3

设计思想
主要特点:
-
单阶段检测,同时完成候选区域生成 + 物体位置和类别的预测
-
每个真实框只对应一个正的候选区域

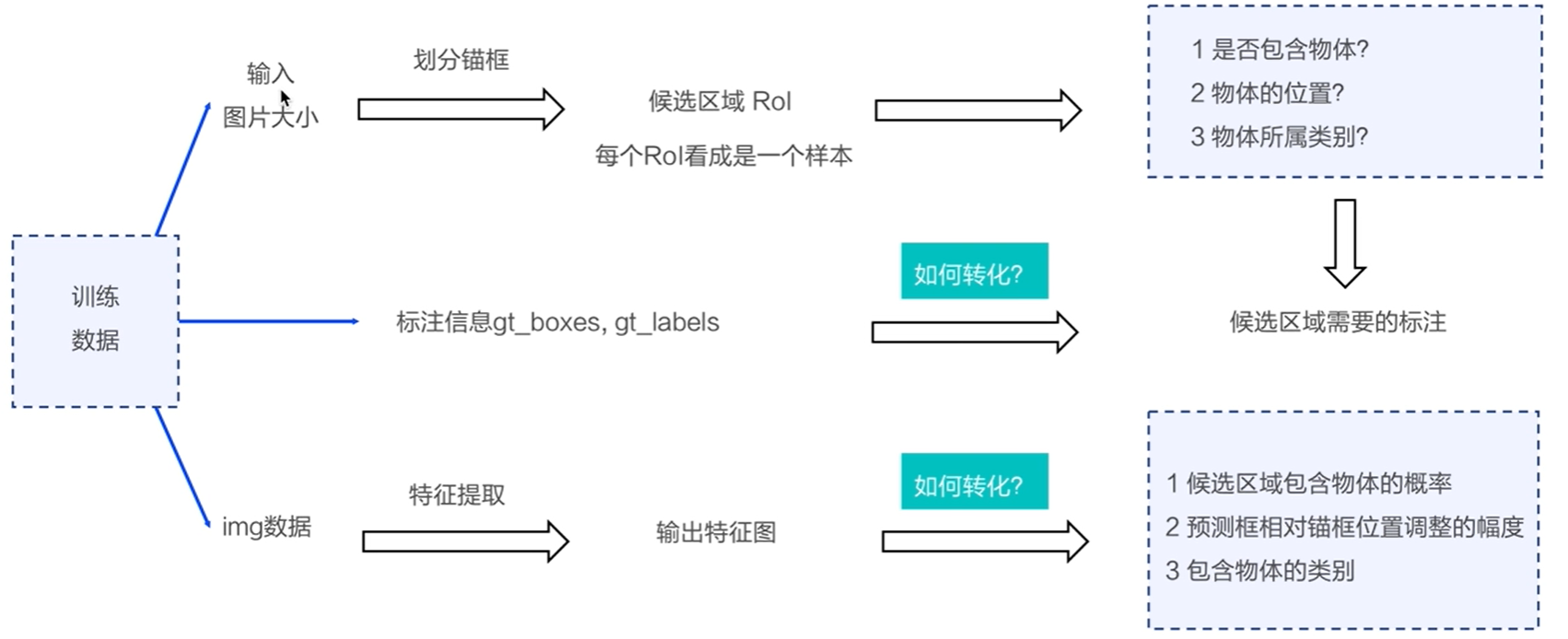
实现方案
生成锚框和候选区域
生成锚框
step1:将原图划分成多个小方块区域
原图大小:640 × 480
小方块尺寸:32 × 32
划分成了20 × 15 个小方块区域
step2:以小方块区域为中心,生成一系列锚框
生成锚框的规则:
-
中心点:小方块区域的中心
-
大小:3种 [w,h]
-
[116,90] , [156,198] , [373,326] (数字的选择-聚类中心)
-
在每个小方块区域都生成三种形状的锚框,将会覆盖整张图片
一张图片上锚框的总数为20 ×15 × 3 = 900

产生候选区域
生成预测框
所有锚框覆盖住了整张图片,但是锚框的位置是固定的,一般不会跟物体真实框刚好重合。
要想得到跟物体真实框足够接近的预测结果,需要在锚框的基础上做一些小的调整。
预测框
可以看作是 在锚框的基础上做微调, 可以调整 中心坐标和宽度、高度。


step1:选择第10行第4列的小方块区域, Cx ,Cy = [4,10]
step2:以小方块为中心,生成锚框。所示锚框大小为[250,250]
step3:计算预测框的中心坐标和尺寸


标注候选区域

标注锚框 ----objectnes
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









