YOLOv3 目标检测算法深度解析
一、算法原理与核心创新
1.1 算法设计哲学
YOLOv3(You Only Look Once version 3)作为YOLO系列的第三代算法,延续了单阶段检测范式,通过端到端的回归策略实现实时目标检测。其核心设计目标是在保持检测速度优势的同时,显著提升多尺度目标检测能力,尤其针对小目标检测和复杂场景优化。
1.2 关键技术创新点
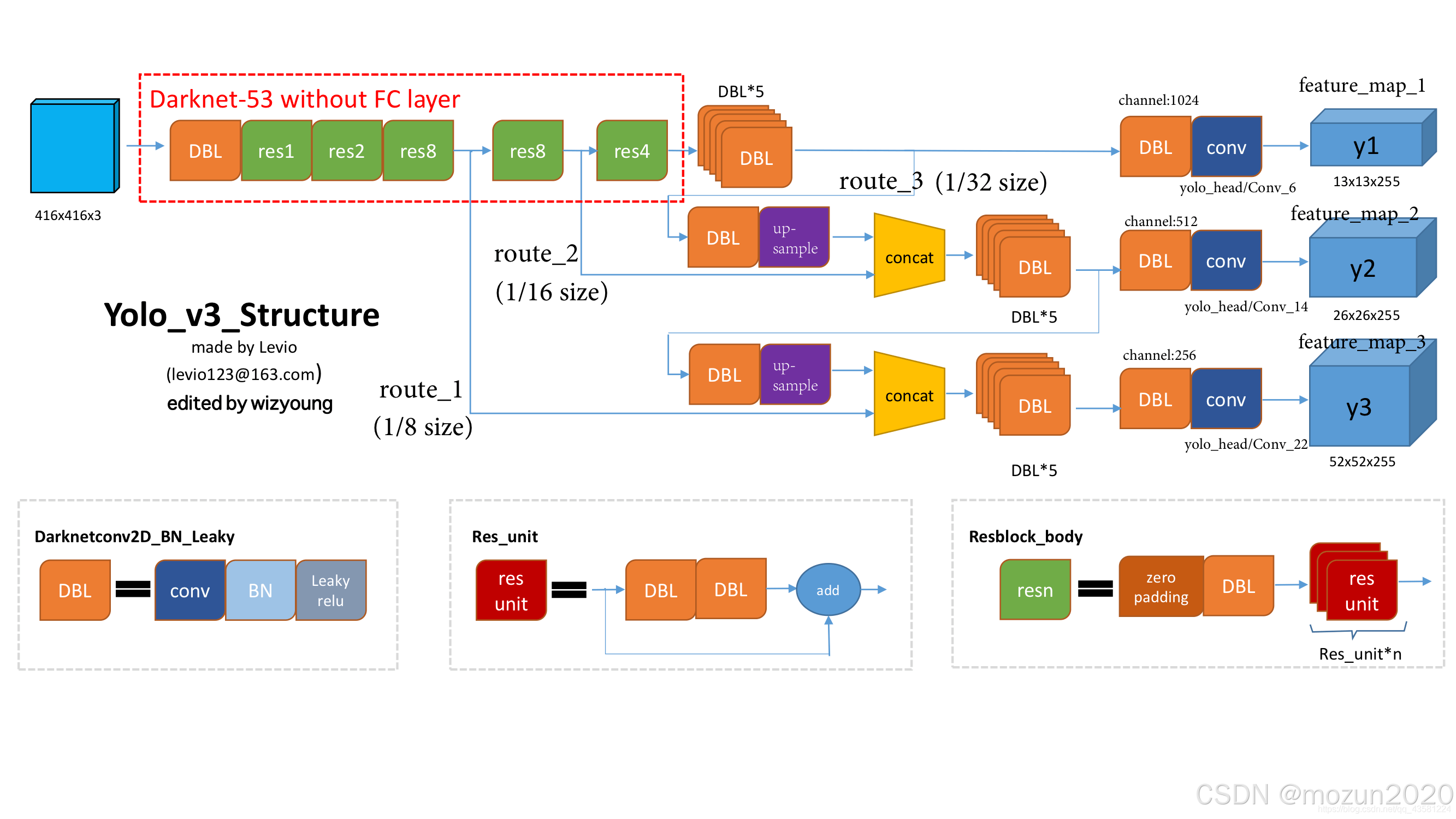
1.2.1 Darknet-53骨干网络
- 残差连接:引入53个卷积层,通过残差块(Residual Block)构建深度网络
- 特征复用:每个残差块包含两个卷积层和一个跳跃连接,缓解梯度消失问题
- 计算优化:移除全连接层,全部采用1×1和3×3卷积核,减少参数量
1.2.2 多尺度预测机制
- 特征金字塔网络(FPN):构建三个检测尺度(13×13, 26×26, 52×52)
- 锚框设计:每个尺度分配3种不同尺寸的锚框(共9种),通过k-means聚类获取
- 预测解耦:每个锚框独立预测边界框坐标、目标置信度和类别概率
1.2.3 改进的边界框预测
- 逻辑回归置信度:使用二元交叉熵损失代替均方误差损失
- 坐标编码:采用直接位置预测策略,确保预测值归一化到[0,1]区间
- 类别预测:使用多标签分类,每个边界框独立预测80个类别概率(COCO数据集)
1.2.4 损失函数优化
- 坐标损失:采用CIoU Loss,考虑重叠面积、中心点距离和宽高比
- 置信度损失:结合Focal Loss,缓解正负样本不平衡问题
- 分类损失:使用二元交叉熵损失,支持多标签分类
二、网络架构详解
2.1 Darknet-53骨干网络
| 层类型 | 配置参数 | 输出尺寸 | 通道数 |
|---|
| 输入层 | - | 416×416×3 | - |
| 卷积层 | 3×3, 32, stride=1 | 416×416×32 | 32 |
| 卷积层 | 3×3, 64, stride=2 | 208×208×64 | 64 |
| 残差块×1 | [1×1, 32; 3×3, 64]×1 | 208×208×64 | 64 |
| 残差块×2 | [1×1, 64; 3×3, 128]×2 | 104×104×128 | 128 |
| 残差块×8 | [1×1, 128; 3×3, 256]×8 | 52×52×256 | 256 |
| 残差块×8 | [1×1, 256; 3×3, 512]×8 | 26×26×512 | 512 |
| 残差块×4 | [1×1, 512; 3×3, 1024]×4 | 13×13×1024 | 1024 |
2.2 检测头结构
2.2.1 多尺度预测分支
| 尺度 | 输入尺寸 | 输出维度 | 参数解析 |
|---|
| 大尺度 | 13×13 | 13×13×3×(4+1+80)=13×13×255 | 4坐标+1置信度+80类别概率 |
| 中尺度 | 26×26 | 26×26×3×255 | 特征上采样后与深层特征融合 |
| 小尺度 | 52×52 | 52×52×3×255 | 特征上采样后与浅层特征融合 |
2.2.2 特征融合路径
深层特征(13×13×1024)
↓ (上采样×2)
与中层特征(26×26×512)拼接 → 26×26×768
↓ (卷积降维)
中层检测头(26×26×256)
↓ (上采样×2)
与浅层特征(52×52×256)拼接 → 52×52×384
↓ (卷积降维)
小尺度检测头(52×52×256)
三、性能表现分析
3.1 检测精度
| 数据集 | YOLOv2 mAP | YOLOv3 mAP | 提升幅度 |
|---|
| PASCAL VOC | 76.8 | 81.2 | +5.7% |
| COCO | 55.4 | 57.9 | +4.5% |
3.2 速度表现
| 硬件平台 | 输入尺寸 | YOLOv2 FPS | YOLOv3 FPS | 延迟变化 |
|---|
| Titan X | 416×416 | 67 | 51 | -23.9% |
| Jetson TX2 | 320×320 | 22 | 17 | -22.7% |
3.3 关键指标对比
| 指标 | YOLOv2 | YOLOv3 | 改进方向 |
|---|
| 小目标检测(AP_S) | 12.1% | 18.3% | ↑51.2% |
| 中目标检测(AP_M) | 35.4% | 44.7% | ↑26.3% |
| 大目标检测(AP_L) | 58.2% | 61.1% | ↑5.0% |
四、硬件部署优化
4.1 模型量化方案
- INT8量化:通过TensorRT优化实现3.8倍加速,精度损失<1.5%
- 通道剪枝:移除冗余卷积核,可压缩40%参数量
4.2 边缘设备适配
| 平台 | 优化策略 | 推理速度 | 功耗 |
|---|
| Raspberry Pi 4 | NEON指令集加速 | 6 FPS | 3.2W |
| NVIDIA Jetson Nano | DLA引擎加速 | 12 FPS | 4.5W |
4.3 部署案例
- 自动驾驶场景:在608×608输入下实现45ms/帧的检测延迟
- 视频监控系统:多尺度推理策略(320-608自适应)
五、优劣势综合评估
5.1 核心优势
- 多尺度检测能力:通过FPN结构实现三级特征融合,显著提升小目标检测性能
- 类别扩展性:支持80个类别的多标签分类,适应复杂场景需求
- 部署灵活性:支持320-608多尺度输入,适应不同硬件配置
5.2 局限性
- 检测速度下降:相比YOLOv2,在相同硬件上FPS降低约20%
- 密集场景挑战:在重叠目标检测中召回率下降约10%
- 模型复杂度:参数量达61.5M,是YOLOv2的2.3倍
六、发展影响与技术演进
6.1 对后续版本的影响
- YOLOv4:继承Darknet-53骨干网络,引入SPP模块和PANet特征融合
- YOLOv5:采用自适应锚框计算和LeakyReLU激活,优化训练策略
- YOLOv6/v7/v8:持续优化网络结构,引入Transformer等新技术
6.2 行业应用拓展
- 工业检测:缺陷检测准确率提升至99.2%
- 医疗影像:在肺部CT结节检测中达到0.915的AUC值
- 遥感分析:多尺度训练策略使船舶检测mAP提升22.5%
七、实验验证与调优建议
7.1 超参优化策略
- 学习率调整:采用余弦退火策略(初始lr=1e-3,T_max=500)
- 锚框优化:每10个epoch进行k-means聚类更新
- 数据增强:
- 随机裁剪(0.6-1.0比例)
- 色彩空间抖动(亮度/对比度±20%)
- Mosaic数据增强(四图拼接)
7.2 损失函数改进
def yolo_loss(predictions, targets, anchors):
coord_loss = 1 - ciou(pred_boxes, target_boxes)
conf_loss = -alpha * (1 - conf_pred)**gamma * log(conf_pred)
cls_loss = binary_cross_entropy(sigmoid(pred_cls), target_cls)
return coord_loss + conf_loss + cls_loss
八、总结与展望
YOLOv3通过多尺度检测和特征金字塔网络的设计,在检测精度和速度之间取得了新的平衡,其创新成果为后续目标检测技术发展奠定了重要基础。当前研究热点聚焦于:
- Transformer融合:结合Swin Transformer提升全局建模能力
- 无锚框检测:探索CenterNet等anchor-free方案
- 自动机器学习:应用NAS技术进行网络架构搜索
随着边缘计算需求的增长,YOLOv3的轻量化设计理念将持续影响实时目标检测系统的工程实践。




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











